 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Learned in Knowledge Graph Embeddings?
Paper and Code
Oct 19, 2021
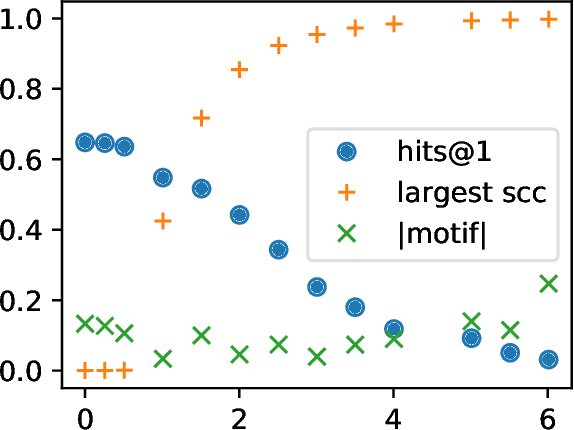

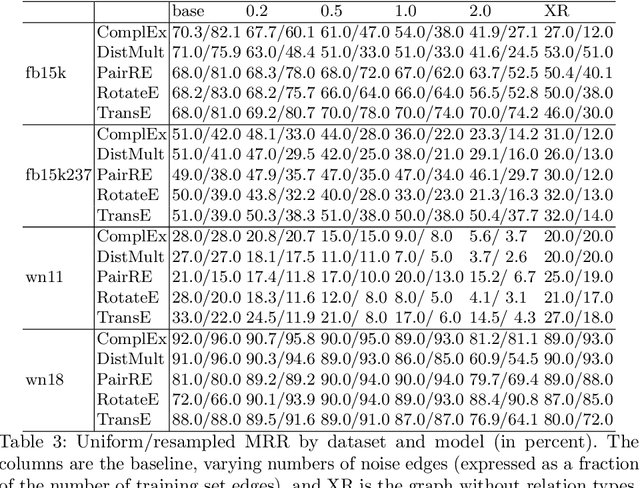
A knowledge graph (KG) is a data structure which represents entities and relations as the vertices and edges of a directed graph with edge types. KGs are an important primitive in modern machine learning and artificial intelligence. Embedding-based models, such as the seminal TransE [Bordes et al., 2013] and the recent PairRE [Chao et al., 2020] are among the most popular and successful approaches for representing KGs and inferring missing edges (link completion). Their relative success is often credited in the literature to their ability to learn logical rules between the relations. In this work, we investigate whether learning rules between relations is indeed what drives the performance of embedding-based methods. We define motif learning and two alternative mechanisms, network learning (based only on the connectivity of the KG, ignoring the relation types), and unstructured statistical learning (ignoring the connectivity of the graph). Using experiments on synthetic KGs, we show that KG models can learn motifs and how this ability is degraded by non-motif (noise) edges. We propose tests to distinguish the contributions of the three mechanisms to performance, and apply them to popular KG benchmarks. We also discuss an issue with the standard performance testing protocol and suggest an improvement. To appear in the proceedings of Complex Networks 2021.