 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENIGMA-360: An Ego-Exo Dataset for Human Behavior Understanding in Industrial Scenarios
Mar 11, 2026Understanding human behavior from complementary egocentric (ego) and exocentric (exo) points of view enables the development of systems that can support workers in industrial environments and enhance their safety. However, progress in this area is hindered by the lack of datasets capturing both views in realistic industrial scenarios. To address this gap, we propose ENIGMA-360, a new ego-exo dataset acquired in a real industrial scenario. The dataset is composed of 180 egocentric and 180 exocentric procedural videos temporally synchronized offering complementary information of the same scene. The 360 videos have been labeled with temporal and spatial annotations, enabling the study of different aspects of human behavior in industrial domain. We provide baseline experiments for 3 foundational tasks for human behavior understanding: 1) Temporal Action Segmentation, 2) Keystep Recognition and 3) Egocentric Human-Object Interaction Detection, showing the limits of state-of-the-art approaches on this challenging scenario. These results highlight the need for new models capable of robust ego-exo understanding in real-world environments. We publicly release the dataset and its annotations at https://fpv-iplab.github.io/ENIGMA-360/.
ProSkill: Segment-Level Skill Assessment in Procedural Videos
Jan 28, 2026Skill assessment in procedural videos is crucial for the objective evaluation of human performance in settings such as manufacturing and procedural daily tasks. Current research on skill assessment has predominantly focused on sports and lacks large-scale datasets for complex procedural activities. Existing studies typically involve only a limited number of actions, focus on either pairwise assessments (e.g., A is better than B) or on binary labels (e.g., good execution vs needs improvement). In response to these shortcomings, we introduce ProSkill, the first benchmark dataset for action-level skill assessment in procedural tasks. ProSkill provides absolute skill assessment annotations, along with pairwise ones. This is enabled by a novel and scalable annotation protocol that allows for the creation of an absolute skill assessment ranking starting from pairwise assessments. This protocol leverages a Swiss Tournament scheme for efficient pairwise comparisons, which are then aggregated into consistent, continuous global scores using an ELO-based rating system. We use our dataset to benchmark the main state-of-the-art skill assessment algorithms, including both ranking-based and pairwise paradigms. The suboptimal results achieved by the current state-of-the-art highlight the challenges and thus the value of ProSkill in the context of skill assessment for procedural videos. All data and code are available at https://fpv-iplab.github.io/ProSkill/
Synchronization is All You Need: Exocentric-to-Egocentric Transfer for Temporal Action Segmentation with Unlabeled Synchronized Video Pairs
Dec 05, 2023



We consider the problem of transferring a temporal action segmentation system initially designed for exocentric (fixed) cameras to an egocentric scenario, where wearable cameras capture video data. The conventional supervised approach requires the collection and labeling of a new set of egocentric videos to adapt the model, which is costly and time-consuming. Instead, we propose a novel methodology which performs the adaptation leveraging existing labeled exocentric videos and a new set of unlabeled, synchronized exocentric-egocentric video pairs, for which temporal action segmentation annotations do not need to be collected. We implement the proposed methodology with an approach based on knowledge distillation, which we investigate both at the feature and model level. To evaluate our approach, we introduce a new benchmark based on the Assembly101 dataset. Results demonstrate the feasibility and effectiveness of the proposed method against classic unsupervised domain adaptation and temporal sequence alignment approaches. Remarkably, without bells and whistles, our best model performs on par with supervised approaches trained on labeled egocentric data, without ever seeing a single egocentric label, achieving a +15.99% (28.59% vs 12.60%) improvement in the edit score on the Assembly101 dataset compared to a baseline model trained solely on exocentric data.
Panoptic Segmentation using Synthetic and Real Data
Apr 14, 2022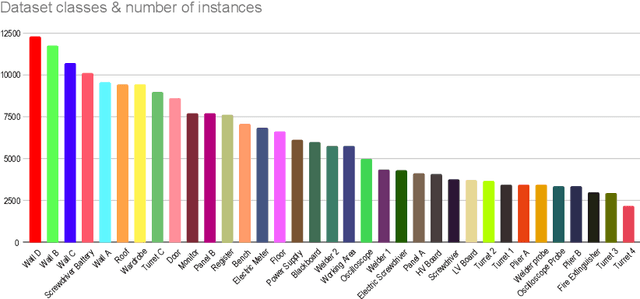
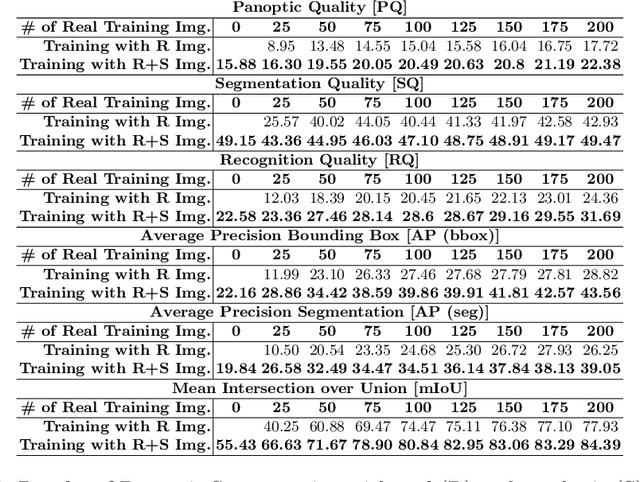
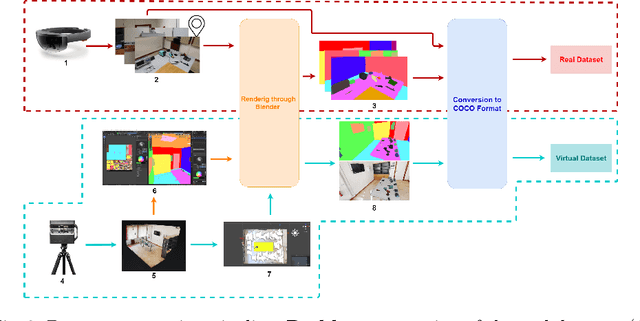

Being able to understand the relations between the user and the surrounding environment is instrumental to assist users in a worksite. For instance, understanding which objects a user is interacting with from images and video collected through a wearable device can be useful to inform the worker on the usage of specific objects in order to improve productivity and prevent accidents. Despite modern vision systems can rely on advanced algorithms for object detection, semantic and panoptic segmentation, these methods still require large quantities of domain-specific labeled data, which can be difficult to obtain in industrial scenarios. Motivated by this observation, we propose a pipeline which allows to generate synthetic images from 3D models of real environments and real objects. The generated images are automatically labeled and hence effortless to obtain. Exploiting the proposed pipeline, we generate a dataset comprising synthetic images automatically labeled for panoptic segmentation. This set is complemented by a small number of manually labeled real images for fine-tuning. Experiments show that the use of synthetic images allows to drastically reduce the number of real images needed to obtain reasonable panoptic segmentation performance.
SceneAdapt: Scene-based domain adaptation for semantic segmentation using adversarial learning
Jun 18, 2020



Semantic segmentation methods have achieved outstanding performance thanks to deep learning. Nevertheless, when such algorithms are deployed to new contexts not seen during training, it is necessary to collect and label scene-specific data in order to adapt them to the new domain using fine-tuning. This process is required whenever an already installed camera is moved or a new camera is introduced in a camera network due to the different scene layouts induced by the different viewpoints. To limit the amount of additional training data to be collected, it would be ideal to train a semantic segmentation method using labeled data already available and only unlabeled data coming from the new camera. We formalize this problem as a domain adaptation task and introduce a novel dataset of urban scenes with the related semantic labels. As a first approach to address this challenging task, we propose SceneAdapt, a method for scene adaptation of semantic segmentation algorithms based on adversarial learning. Experiments and comparisons with state-of-the-art approaches to domain adaptation highlight that promising performance can be achieved using adversarial learning both when the two scenes have different but points of view, and when they comprise images of completely different scenes. To encourage research on this topic, we made our code available at our web page: https://iplab.dmi.unict.it/ParkSmartSceneAdaptation/.