 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Invariant Restricted Boltzmann Machine Using Shared Gradient Filters
Paper and Code
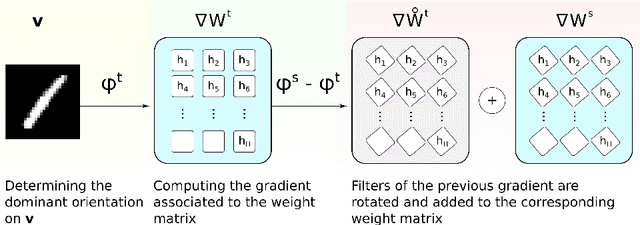



Finding suitable features has been an essential problem in computer vision. We focus on Restricted Boltzmann Machines (RBMs), which, despite their versatility, cannot accommodate transformations that may occur in the scene. As a result, several approaches have been proposed that consider a set of transformations, which are used to either augment the training set or transform the actual learned filters. In this paper, we propose the Explicit Rotation-Invariant Restricted Boltzmann Machine, which exploits prior information coming from the dominant orientation of images. Our model extends the standard RBM, by adding a suitable number of weight matrices, associated with each dominant gradient. We show that our approach is able to learn rotation-invariant features, comparing it with the classic formulation of RBM on the MNIST benchmark dataset. Overall, requiring less hidden units, our method learns compact features, which are robust to rotations.