 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Data-Driven Design of High-Dimensional Predictive Studies
May 21, 2026Predictive modelling is important for health data analysis and data-driven clinical decision-making. However, predictive studies are challenging to design optimally by hand when tens or even hundreds of features require selection, transformation, or interaction modelling. While complex machine learning models offer high performance, their "black-box" nature limits the clinical trust, transparency, and interpretability required for decision-making. We developed and evaluated an Exploratory AI Recommender that provides data-driven recommendations to improve predictive performance of existing interpretable statistical models. The developed framework uses flexible AI modelling to capture complex data patterns and explainable AI techniques to translate the patterns into three recommendation types: feature exclusion, non-linear terms, and feature interactions. We evaluated the framework by comparing predictive performance of a baseline (i.e., no interactions or non-linear terms) Cox Proportional Hazards (CPH) model against an augmented CPH incorporating recommendations suggested by our method. The primary analysis predicts the time to the first occurrence of a fall or related injury in 245,614 patients. Our method recommended excluding 23 features, including non-linear terms for two features, and including 221 suggested feature interactions. The C-index improved from 0.805 (95% CI 0.798-0.812) to 0.815 (95% CI 0.809-0.822), and so did calibration (intercept: -0.006 to 0.003; slope: 1.063 to 0.950). All recommendations were supported by existing literature. The method also proved effective on two additional public datasets, demonstrating wider applicability. The proposed Exploratory AI Recommender demonstrates the potential of explainable AI and data-driven study design to improve the process of developing, and the performance of high-dimensional transparent predictive models.
A Causal Framework for Mitigating Data Shifts in Healthcare
Mar 13, 2026Developing predictive models that perform reliably across diverse patient populations and heterogeneous environments is a core aim of medical research. However, generalization is only possible if the learned model is robust to statistical differences between data used for training and data seen at the time and place of deployment. Domain generalization methods provide strategies to address data shifts, but each method comes with its own set of assumptions and trade-offs. To apply these methods in healthcare, we must understand how domain shifts arise, what assumptions we prefer to make, and what our design constraints are. This article proposes a causal framework for the design of predictive models to improve generalization. Causality provides a powerful language to characterize and understand diverse domain shifts, regardless of data modality. This allows us to pinpoint why models fail to generalize, leading to more principled strategies to prepare for and adapt to shifts. We recommend general mitigation strategies, discussing trade-offs and highlighting existing work. Our causality-based perspective offers a critical foundation for developing robust, interpretable, and clinically relevant AI solutions in healthcare, paving the way for reliable real-world deployment.
CROCODILE: Causality aids RObustness via COntrastive DIsentangled LEarning
Aug 09, 2024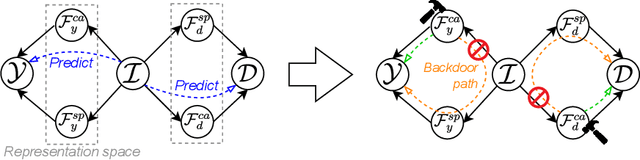
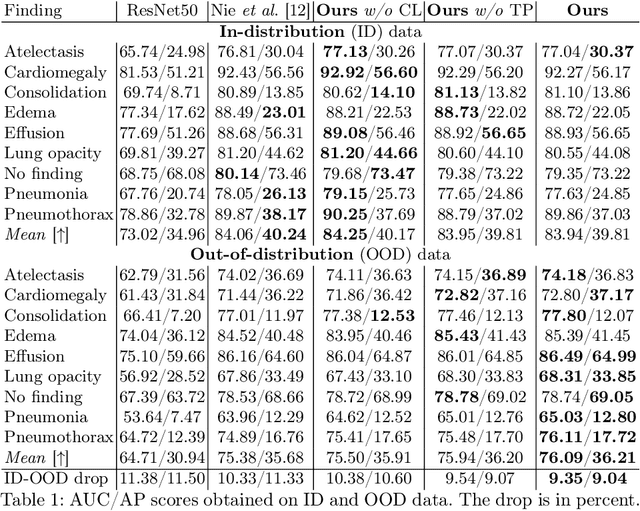
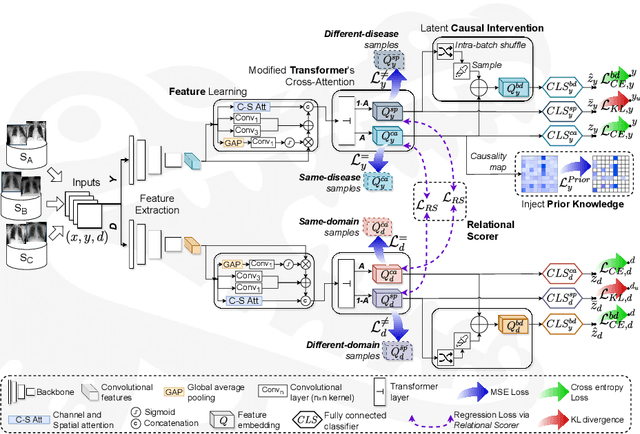
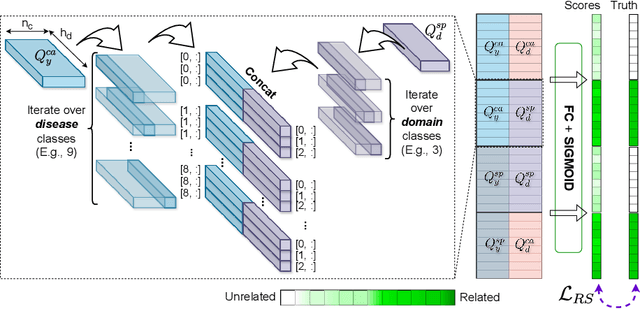
Due to domain shift, deep learning image classifiers perform poorly when applied to a domain different from the training one. For instance, a classifier trained on chest X-ray (CXR) images from one hospital may not generalize to images from another hospital due to variations in scanner settings or patient characteristics. In this paper, we introduce our CROCODILE framework, showing how tools from causality can foster a model's robustness to domain shift via feature disentanglement, contrastive learning losses, and the injection of prior knowledge. This way, the model relies less on spurious correlations, learns the mechanism bringing from images to prediction better, and outperforms baselines on out-of-distribution (OOD) data. We apply our method to multi-label lung disease classification from CXRs, utilizing over 750000 images from four datasets. Our bias-mitigation method improves domain generalization and fairness, broadening the applicability and reliability of deep learning models for a safer medical image analysis. Find our code at: https://github.com/gianlucarloni/crocodile.
Have you forgotten? A method to assess if machine learning models have forgotten data
Apr 21, 2020
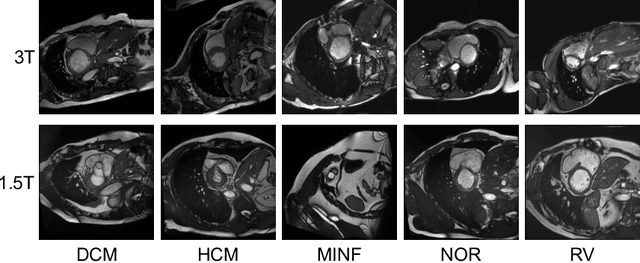

In the era of deep learning, aggregation of data from several sources is considered as a common approach to ensuring data diversity. Let us consider a scenario where several providers contribute data to a consortium for the joint development of a classification model (hereafter the target model), but, now one of the providers decides to leave. The provider requests that their data (hereafter the query dataset) be removed from the databases but also that the model `forgets' their data. In this paper, for the first time, we want to address the challenging question of whether data have been forgotten by a model. We assume knowledge of the query dataset and the distribution of a model's output activations. We establish statistical methods that compare the outputs of the target with outputs of models trained with different datasets. We evaluate our approach on several benchmark datasets (MNIST, CIFAR-10 and SVHN) and on a cardiac pathology diagnosis task using data from the Automated Cardiac Diagnosis Challenge (ACDC). We hope to encourage investigations on what information a model retains and inspire extensions in more complex settings.
Teacher-Student chain for efficient semi-supervised histology image classification
Mar 20, 2020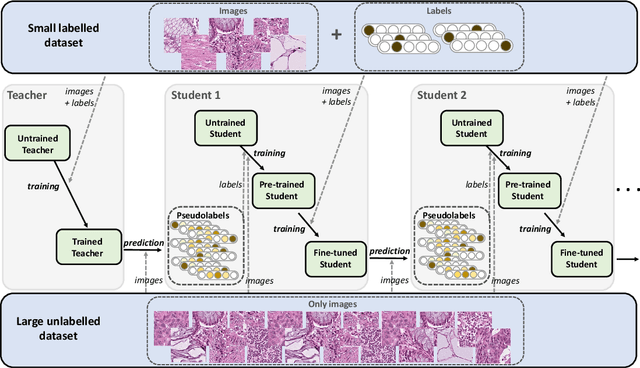

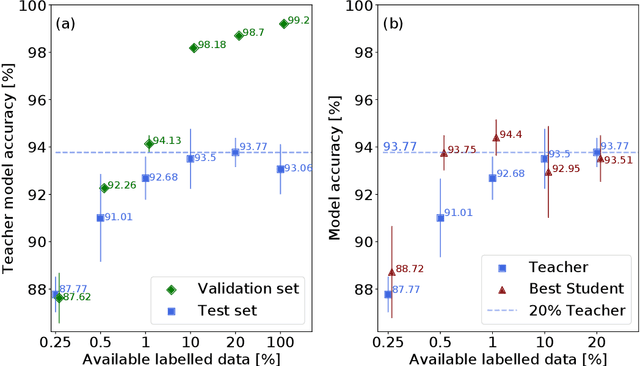
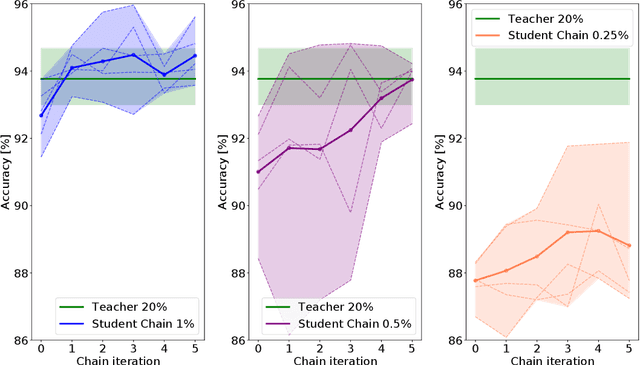
Deep learning shows great potential for the domain of digital pathology. An automated digital pathology system could serve as a second reader, perform initial triage in large screening studies, or assist in reporting. However, it is expensive to exhaustively annotate large histology image databases, since medical specialists are a scarce resource. In this paper, we apply the semi-supervised teacher-student knowledge distillation technique proposed by Yalniz et al. (2019) to the task of quantifying prognostic features in colorectal cancer. We obtain accuracy improvements through extending this approach to a chain of students, where each student's predictions are used to train the next student i.e. the student becomes the teacher. Using the chain approach, and only 0.5% labelled data (the remaining 99.5% in the unlabelled pool), we match the accuracy of training on 100% labelled data. At lower percentages of labelled data, similar gains in accuracy are seen, allowing some recovery of accuracy even from a poor initial choice of labelled training set. In conclusion, this approach shows promise for reducing the annotation burden, thus increasing the affordability of automated digital pathology systems.
Leveraging multiple datasets for deep leaf counting
Sep 05, 2017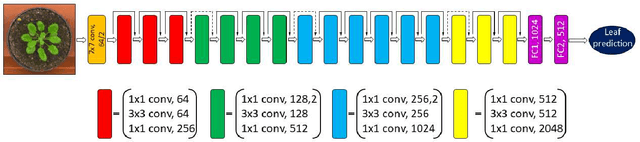
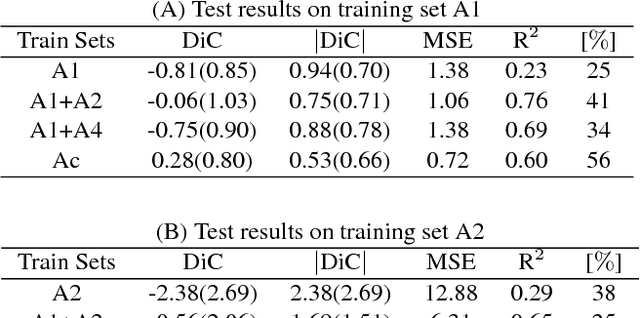

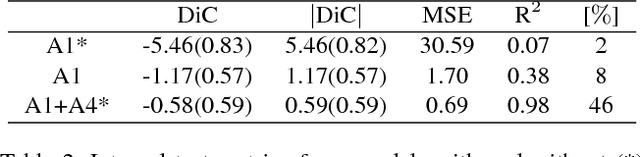
The number of leaves a plant has is one of the key traits (phenotypes) describing its development and growth. Here, we propose an automated, deep learning based approach for counting leaves in model rosette plants. While state-of-the-art results on leaf counting with deep learning methods have recently been reported, they obtain the count as a result of leaf segmentation and thus require per-leaf (instance) segmentation to train the models (a rather strong annotation). Instead, our method treats leaf counting as a direct regression problem and thus only requires as annotation the total leaf count per plant. We argue that combining different datasets when training a deep neural network is beneficial and improves the results of the proposed approach. We evaluate our method on the CVPPP 2017 Leaf Counting Challenge dataset, which contains images of Arabidopsis and tobacco plants. Experimental results show that the proposed method significantly outperforms the winner of the previous CVPPP challenge, improving the results by a minimum of ~50% on each of the test datasets, and can achieve this performance without knowing the experimental origin of the data (i.e. in the wild setting of the challenge). We also compare the counting accuracy of our model with that of per leaf segmentation algorithms, achieving a 20% decrease in mean absolute difference in count (|DiC|).
* 8 pages, 3 figures, 3 tables
ARIGAN: Synthetic Arabidopsis Plants using Generative Adversarial Network
Sep 04, 2017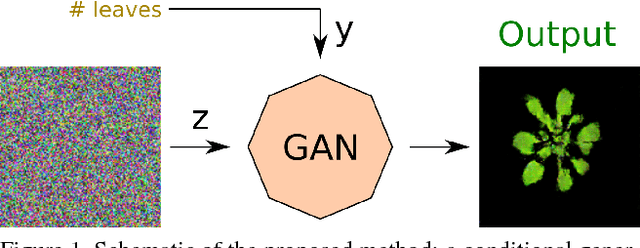
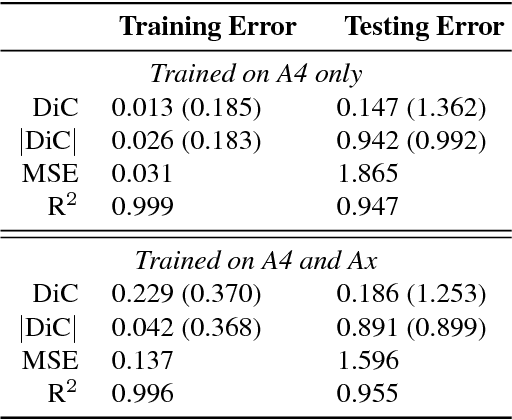
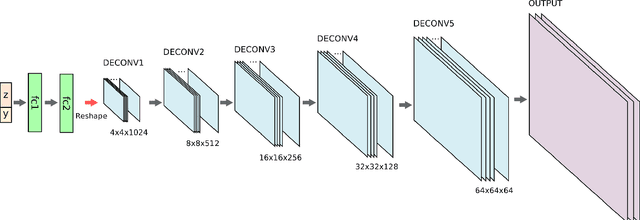
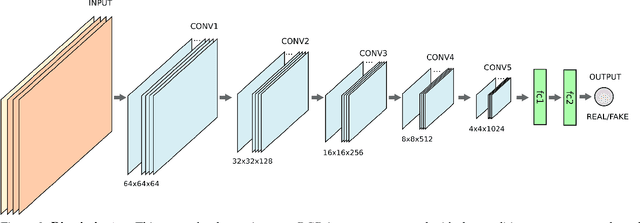
In recent years, there has been an increasing interest in image-based plant phenotyping, applying state-of-the-art machine learning approaches to tackle challenging problems, such as leaf segmentation (a multi-instance problem) and counting. Most of these algorithms need labelled data to learn a model for the task at hand. Despite the recent release of a few plant phenotyping datasets, large annotated plant image datasets for the purpose of training deep learning algorithms are lacking. One common approach to alleviate the lack of training data is dataset augmentation. Herein, we propose an alternative solution to dataset augmentation for plant phenotyping, creating artificial images of plants using generative neural networks. We propose the Arabidopsis Rosette Image Generator (through) Adversarial Network: a deep convolutional network that is able to generate synthetic rosette-shaped plants, inspired by DCGAN (a recent adversarial network model using convolutional layers). Specifically, we trained the network using A1, A2, and A4 of the CVPPP 2017 LCC dataset, containing Arabidopsis Thaliana plants. We show that our model is able to generate realistic 128x128 colour images of plants. We train our network conditioning on leaf count, such that it is possible to generate plants with a given number of leaves suitable, among others, for training regression based models. We propose a new Ax dataset of artificial plants images, obtained by our ARIGAN. We evaluate this new dataset using a state-of-the-art leaf counting algorithm, showing that the testing error is reduced when Ax is used as part of the training data.