 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Accurate Scene Text Recognition with Cascaded-Transformers
Mar 24, 2025In recent years, vision transformers with text decoder have demonstrated remarkable performance on Scene Text Recognition (STR) due to their ability to capture long-range dependencies and contextual relationships with high learning capacity. However, the computational and memory demands of these models are significant, limiting their deployment in resource-constrained applications. To address this challenge, we propose an efficient and accurate STR system. Specifically, we focus on improving the efficiency of encoder models by introducing a cascaded-transformers structure. This structure progressively reduces the vision token size during the encoding step, effectively eliminating redundant tokens and reducing computational cost. Our experimental results confirm that our STR system achieves comparable performance to state-of-the-art baselines while substantially decreasing computational requirements. In particular, for large-models, the accuracy remains same, 92.77 to 92.68, while computational complexity is almost halved with our structure.
Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation
Mar 20, 2025



Scaling architectures have been proven effective for improving Scene Text Recognition (STR), but the individual contribution of vision encoder and text decoder scaling remain under-explored. In this work, we present an in-depth empirical analysis and demonstrate that, contrary to previous observations, scaling the decoder yields significant performance gains, always exceeding those achieved by encoder scaling alone. We also identify label noise as a key challenge in STR, particularly in real-world data, which can limit the effectiveness of STR models. To address this, we propose Cloze Self-Distillation (CSD), a method that mitigates label noise by distilling a student model from context-aware soft predictions and pseudolabels generated by a teacher model. Additionally, we enhance the decoder architecture by introducing differential cross-attention for STR. Our methodology achieves state-of-the-art performance on 10 out of 11 benchmarks using only real data, while significantly reducing the parameter size and computational costs.
Trust And Balance: Few Trusted Samples Pseudo-Labeling and Temperature Scaled Loss for Effective Source-Free Unsupervised Domain Adaptation
Sep 01, 2024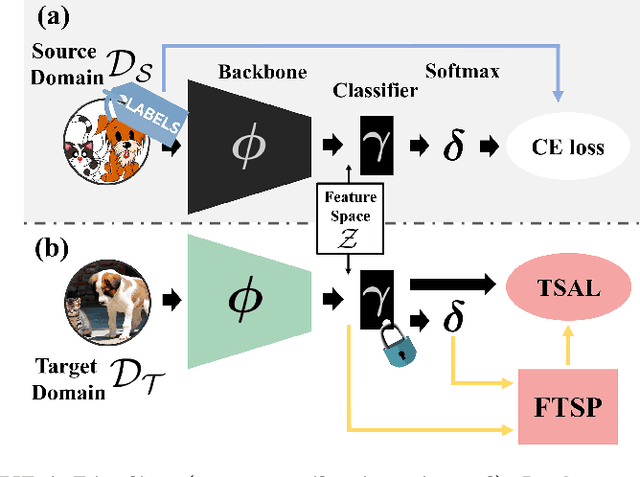
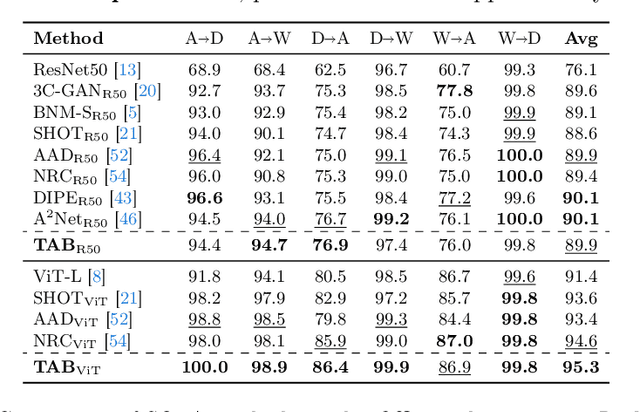
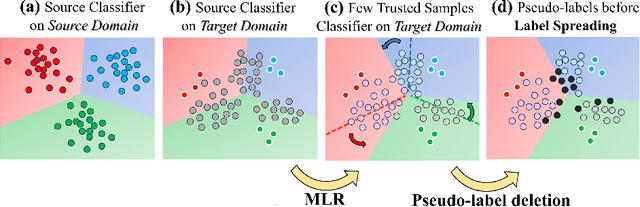
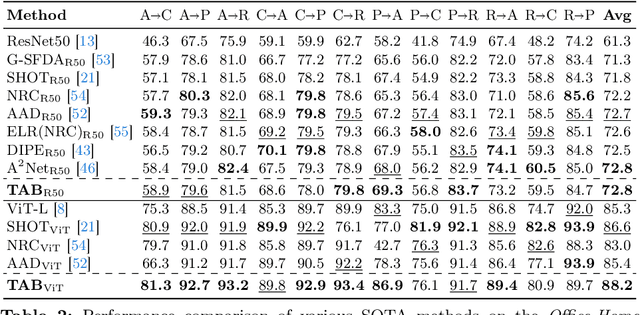
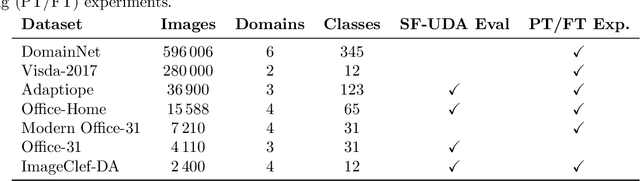
Deep Neural Networks have significantly impacted many computer vision tasks. However, their effectiveness diminishes when test data distribution (target domain) deviates from the one of training data (source domain). In situations where target labels are unavailable and the access to the labeled source domain is restricted due to data privacy or memory constraints, Source-Free Unsupervised Domain Adaptation (SF-UDA) has emerged as a valuable tool. Recognizing the key role of SF-UDA under these constraints, we introduce a novel approach marked by two key contributions: Few Trusted Samples Pseudo-labeling (FTSP) and Temperature Scaled Adaptive Loss (TSAL). FTSP employs a limited subset of trusted samples from the target data to construct a classifier to infer pseudo-labels for the entire domain, showing simplicity and improved accuracy. Simultaneously, TSAL, designed with a unique dual temperature scheduling, adeptly balance diversity, discriminability, and the incorporation of pseudo-labels in the unsupervised adaptation objective. Our methodology, that we name Trust And Balance (TAB) adaptation, is rigorously evaluated on standard datasets like Office31 and Office-Home, and on less common benchmarks such as ImageCLEF-DA and Adaptiope, employing both ResNet50 and ViT-Large architectures. Our results compare favorably with, and in most cases surpass, contemporary state-of-the-art techniques, underscoring the effectiveness of our methodology in the SF-UDA landscape.
Key Design Choices in Source-Free Unsupervised Domain Adaptation: An In-depth Empirical Analysis
Feb 25, 2024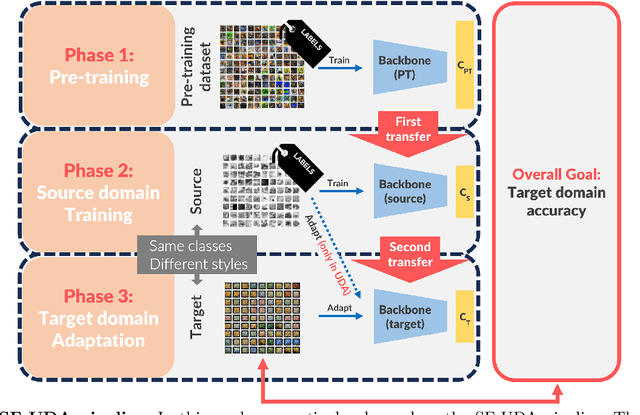


This study provides a comprehensive benchmark framework for Source-Free Unsupervised Domain Adaptation (SF-UDA) in image classification, aiming to achieve a rigorous empirical understanding of the complex relationships between multiple key design factors in SF-UDA methods. The study empirically examines a diverse set of SF-UDA techniques, assessing their consistency across datasets, sensitivity to specific hyperparameters, and applicability across different families of backbone architectures. Moreover, it exhaustively evaluates pre-training datasets and strategies, particularly focusing on both supervised and self-supervised methods, as well as the impact of fine-tuning on the source domain. Our analysis also highlights gaps in existing benchmark practices, guiding SF-UDA research towards more effective and general approaches. It emphasizes the importance of backbone architecture and pre-training dataset selection on SF-UDA performance, serving as an essential reference and providing key insights. Lastly, we release the source code of our experimental framework. This facilitates the construction, training, and testing of SF-UDA methods, enabling systematic large-scale experimental analysis and supporting further research efforts in this field.
Sim2Real Bilevel Adaptation for Object Surface Classification using Vision-Based Tactile Sensors
Nov 02, 2023In this paper, we address the Sim2Real gap in the field of vision-based tactile sensors for classifying object surfaces. We train a Diffusion Model to bridge this gap using a relatively small dataset of real-world images randomly collected from unlabeled everyday objects via the DIGIT sensor. Subsequently, we employ a simulator to generate images by uniformly sampling the surface of objects from the YCB Model Set. These simulated images are then translated into the real domain using the Diffusion Model and automatically labeled to train a classifier. During this training, we further align features of the two domains using an adversarial procedure. Our evaluation is conducted on a dataset of tactile images obtained from a set of ten 3D printed YCB objects. The results reveal a total accuracy of 81.9%, a significant improvement compared to the 34.7% achieved by the classifier trained solely on simulated images. This demonstrates the effectiveness of our approach. We further validate our approach using the classifier on a 6D object pose estimation task from tactile data.
Key Design Choices for Double-Transfer in Source-Free Unsupervised Domain Adaptation
Feb 10, 2023Fine-tuning and Domain Adaptation emerged as effective strategies for efficiently transferring deep learning models to new target tasks. However, target domain labels are not accessible in many real-world scenarios. This led to the development of Unsupervised Domain Adaptation (UDA) methods, which only employ unlabeled target samples. Furthermore, efficiency and privacy requirements may also prevent the use of source domain data during the adaptation stage. This challenging setting, known as Source-Free Unsupervised Domain Adaptation (SF-UDA), is gaining interest among researchers and practitioners due to its potential for real-world applications. In this paper, we provide the first in-depth analysis of the main design choices in SF-UDA through a large-scale empirical study across 500 models and 74 domain pairs. We pinpoint the normalization approach, pre-training strategy, and backbone architecture as the most critical factors. Based on our quantitative findings, we propose recipes to best tackle SF-UDA scenarios. Moreover, we show that SF-UDA is competitive also beyond standard benchmarks and backbone architectures, performing on par with UDA at a fraction of the data and computational cost. In the interest of reproducibility, we include the full experimental results and code as supplementary material.
RECALL: Replay-based Continual Learning in Semantic Segmentation
Aug 08, 2021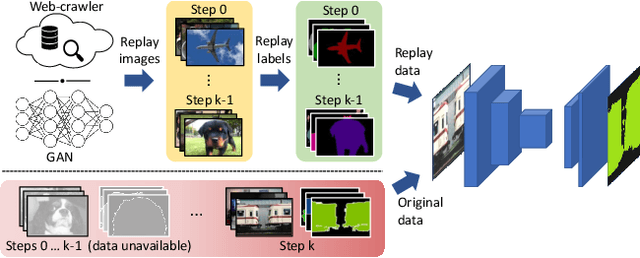
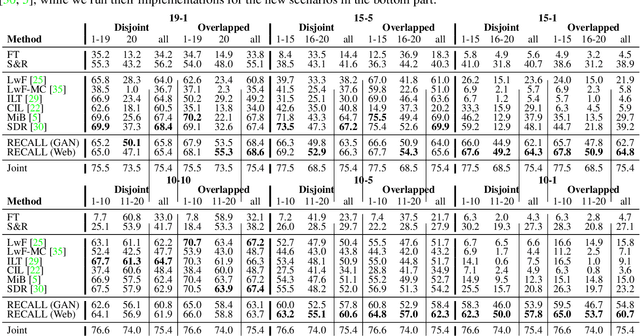
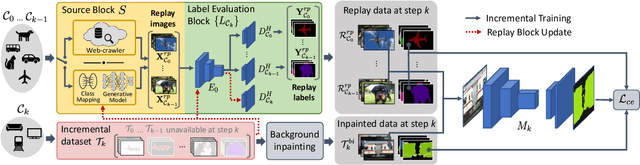
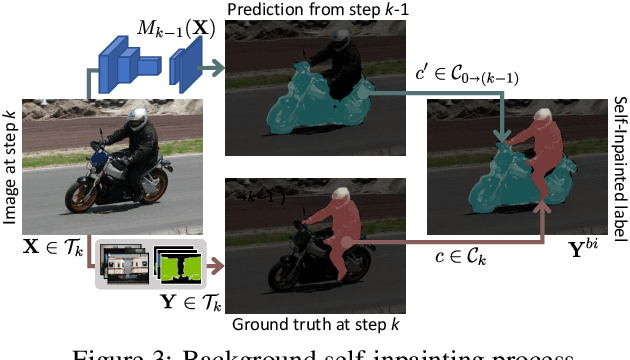
Deep networks allow to obtain outstanding results in semantic segmentation, however they need to be trained in a single shot with a large amount of data. Continual learning settings where new classes are learned in incremental steps and previous training data is no longer available are challenging due to the catastrophic forgetting phenomenon. Existing approaches typically fail when several incremental steps are performed or in presence of a distribution shift of the background class. We tackle these issues by recreating no longer available data for the old classes and outlining a content inpainting scheme on the background class. We propose two sources for replay data. The first resorts to a generative adversarial network to sample from the class space of past learning steps. The second relies on web-crawled data to retrieve images containing examples of old classes from online databases. In both scenarios no samples of past steps are stored, thus avoiding privacy concerns. Replay data are then blended with new samples during the incremental steps. Our approach, RECALL, outperforms state-of-the-art methods.
Unsupervised Domain Adaptation in Semantic Segmentation: a Review
May 21, 2020
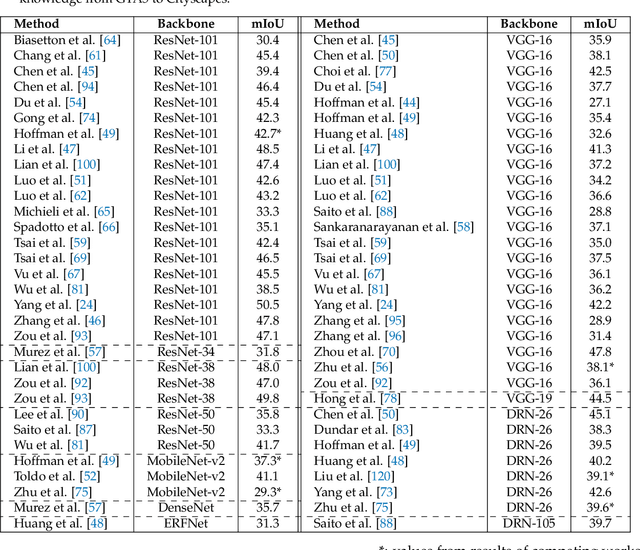

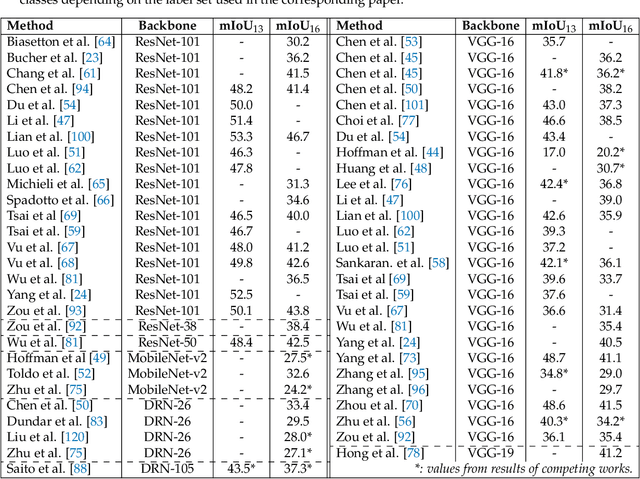
The aim of this paper is to give an overview of the recent advancements in the Unsupervised Domain Adaptation (UDA) of deep networks for semantic segmentation. This task is attracting a wide interest, since semantic segmentation models require a huge amount of labeled data and the lack of data fitting specific requirements is the main limitation in the deployment of these techniques. This problem has been recently explored and has rapidly grown with a large number of ad-hoc approaches. This motivates us to build a comprehensive overview of the proposed methodologies and to provide a clear categorization. In this paper, we start by introducing the problem, its formulation and the various scenarios that can be considered. Then, we introduce the different levels at which adaptation strategies may be applied: namely, at the input (image) level, at the internal features representation and at the output level. Furthermore, we present a detailed overview of the literature in the field, dividing previous methods based on the following (non mutually exclusive) categories: adversarial learning, generative-based, analysis of the classifier discrepancies, self-teaching, entropy minimization, curriculum learning and multi-task learning. Novel research directions are also briefly introduced to give a hint of interesting open problems in the field. Finally, a comparison of the performance of the various methods in the widely used autonomous driving scenario is presented.