 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation
Mar 20, 2025



Scaling architectures have been proven effective for improving Scene Text Recognition (STR), but the individual contribution of vision encoder and text decoder scaling remain under-explored. In this work, we present an in-depth empirical analysis and demonstrate that, contrary to previous observations, scaling the decoder yields significant performance gains, always exceeding those achieved by encoder scaling alone. We also identify label noise as a key challenge in STR, particularly in real-world data, which can limit the effectiveness of STR models. To address this, we propose Cloze Self-Distillation (CSD), a method that mitigates label noise by distilling a student model from context-aware soft predictions and pseudolabels generated by a teacher model. Additionally, we enhance the decoder architecture by introducing differential cross-attention for STR. Our methodology achieves state-of-the-art performance on 10 out of 11 benchmarks using only real data, while significantly reducing the parameter size and computational costs.
A Data-driven Approach to Estimate User Satisfaction in Multi-turn Dialogues
Mar 01, 2021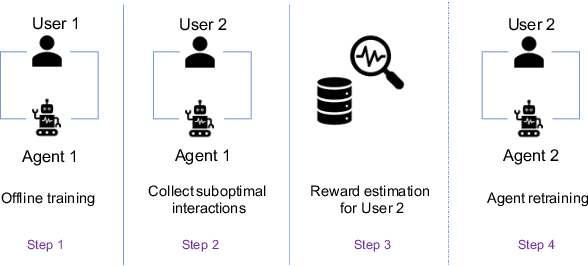
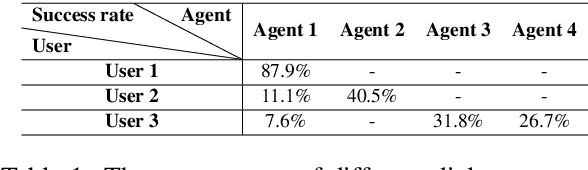

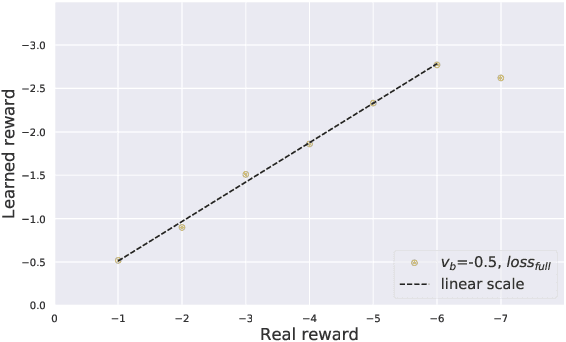
The evaluation of multi-turn dialogues remains challenging. The common approach of labeling the user satisfaction with the experience on the dialogue level does not reflect the task's difficulty. Therefore assigning the same experience score to two tasks with different complexity levels is misleading. Another approach, which suggests evaluating each dialogue turn independently, ignores each turn's long-term influence over the final user experience with dialogue. We instead develop a new method to estimate the turn-level satisfaction for dialogue, which is context-sensitive and has a long-term view. Our approach is data-driven which makes it easily personalized. The interactions between users and dialogue systems are formulated using a budget consumption setup. We assume the user has an initial interaction budget for a conversation based on the task complexity, and each dialogue turn has a cost. When the task is completed or the budget has been run out, the user will quit the interaction. We demonstrate the effectiveness of our method by extensive experimentation with a simulated dialogue platform and a realistic dialogue dataset.
Large-scale Hybrid Approach for Predicting User Satisfaction with Conversational Agents
May 29, 2020
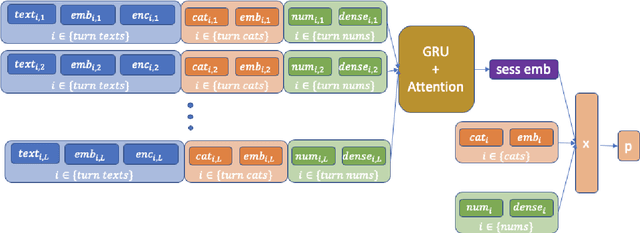
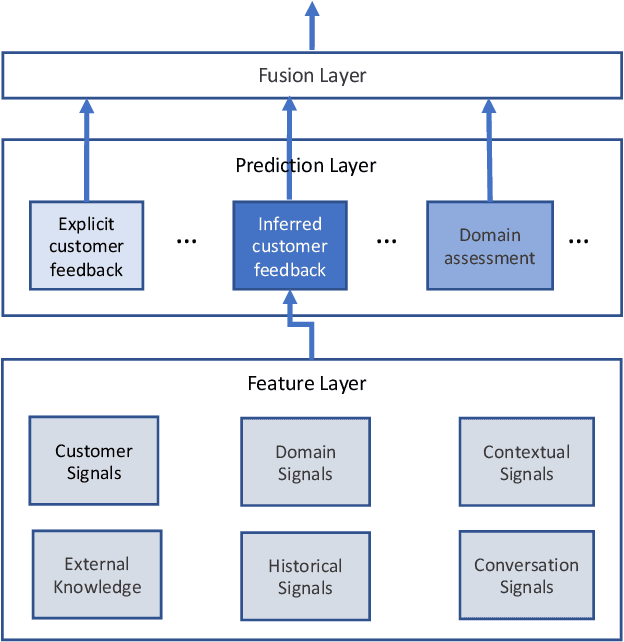
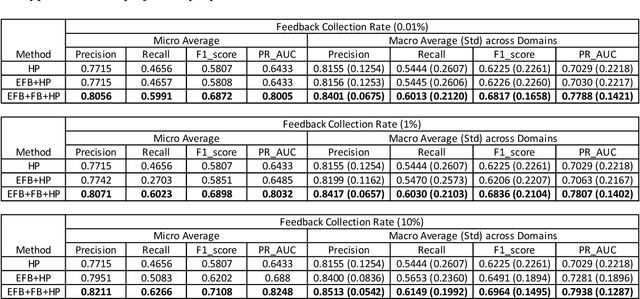
Measuring user satisfaction level is a challenging task, and a critical component in developing large-scale conversational agent systems serving the needs of real users. An widely used approach to tackle this is to collect human annotation data and use them for evaluation or modeling. Human annotation based approaches are easier to control, but hard to scale. A novel alternative approach is to collect user's direct feedback via a feedback elicitation system embedded to the conversational agent system, and use the collected user feedback to train a machine-learned model for generalization. User feedback is the best proxy for user satisfaction, but is not available for some ineligible intents and certain situations. Thus, these two types of approaches are complementary to each other. In this work, we tackle the user satisfaction assessment problem with a hybrid approach that fuses explicit user feedback, user satisfaction predictions inferred by two machine-learned models, one trained on user feedback data and the other human annotation data. The hybrid approach is based on a waterfall policy, and the experimental results with Amazon Alexa's large-scale datasets show significant improvements in inferring user satisfaction. A detailed hybrid architecture, an in-depth analysis on user feedback data, and an algorithm that generates data sets to properly simulate the live traffic are presented in this paper.
Joint Correction of Attenuation and Scatter Using Deep Convolutional Neural Networks (DCNN) for Time-of-Flight PET
Nov 28, 2018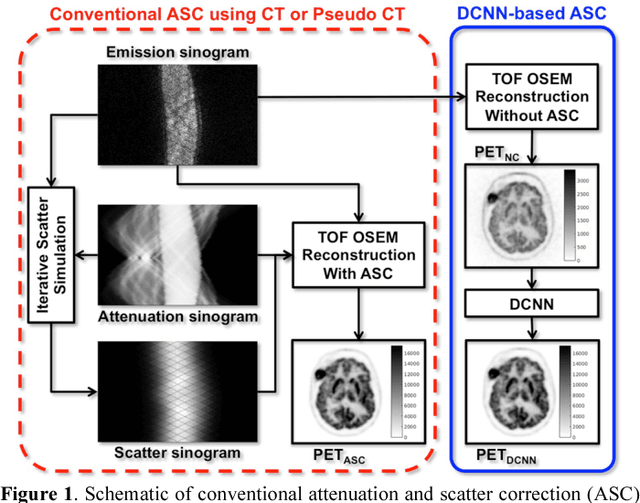
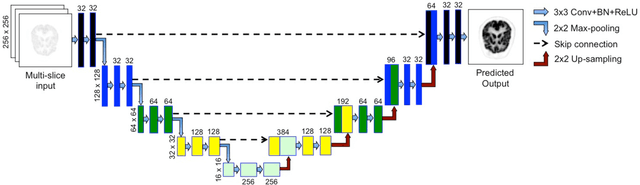
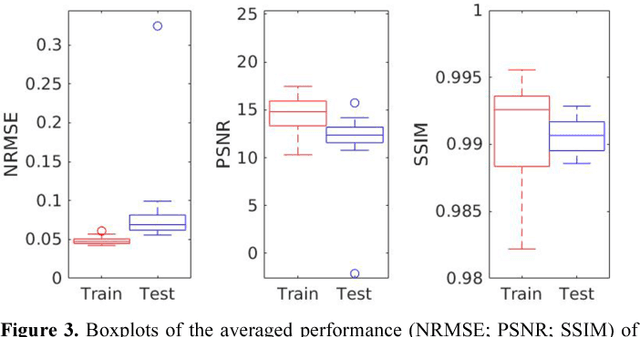
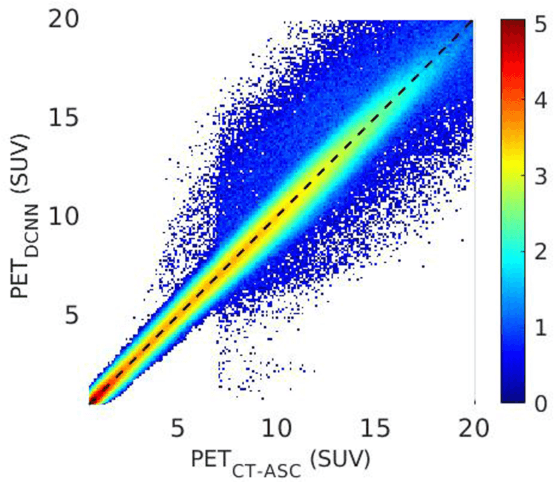
Deep convolutional neural networks (DCNN) have demonstrated its capability to convert MR image to pseudo CT for PET attenuation correction in PET/MRI. Conventionally, attenuated events are corrected in sinogram space using attenuation maps derived from CT or MR-derived pseudo CT. Separately, scattered events are iteratively estimated by a 3D model-based simulation using down-sampled attenuation and emission sinograms. However, no studies have investigated joint correction of attenuation and scatter using DCNN in image space. Therefore, we aim to develop and optimize a DCNN model for attenuation and scatter correction (ASC) simultaneously in PET image space without additional anatomical imaging or time-consuming iterative scatter simulation. For the first time, we demonstrated the feasibility of directly producing PET images corrected for attenuation and scatter using DCNN (PET-DCNN) from noncorrected PET (PET-NC) images.