 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Data Meets LLM -- Explainable Financial Time Series Forecasting
Jun 19, 2023This paper presents a novel study on harnessing Large Language Models' (LLMs) outstanding knowledge and reasoning abilities for explainable financial time series forecasting. The application of machine learning models to financial time series comes with several challenges, including the difficulty in cross-sequence reasoning and inference, the hurdle of incorporating multi-modal signals from historical news, financial knowledge graphs, etc., and the issue of interpreting and explaining the model results. In this paper, we focus on NASDAQ-100 stocks, making use of publicly accessible historical stock price data, company metadata, and historical economic/financial news. We conduct experiments to illustrate the potential of LLMs in offering a unified solution to the aforementioned challenges. Our experiments include trying zero-shot/few-shot inference with GPT-4 and instruction-based fine-tuning with a public LLM model Open LLaMA. We demonstrate our approach outperforms a few baselines, including the widely applied classic ARMA-GARCH model and a gradient-boosting tree model. Through the performance comparison results and a few examples, we find LLMs can make a well-thought decision by reasoning over information from both textual news and price time series and extracting insights, leveraging cross-sequence information, and utilizing the inherent knowledge embedded within the LLM. Additionally, we show that a publicly available LLM such as Open-LLaMA, after fine-tuning, can comprehend the instruction to generate explainable forecasts and achieve reasonable performance, albeit relatively inferior in comparison to GPT-4.
Large-scale Hybrid Approach for Predicting User Satisfaction with Conversational Agents
May 29, 2020
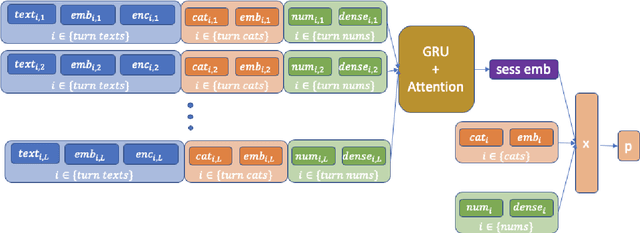
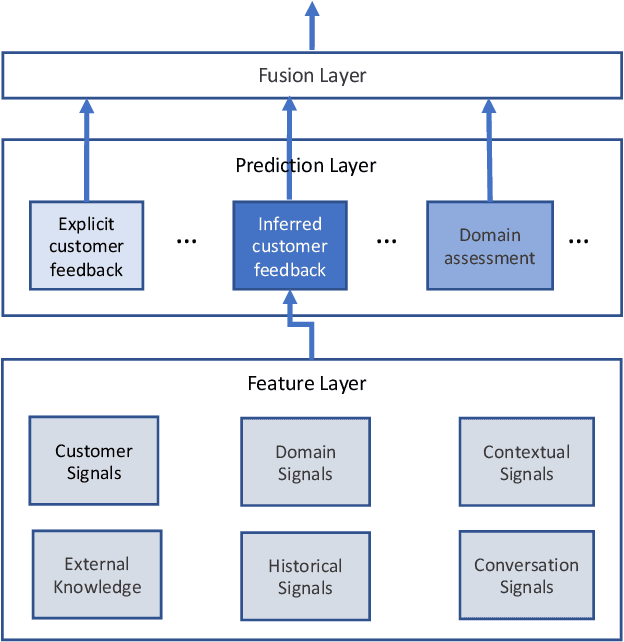
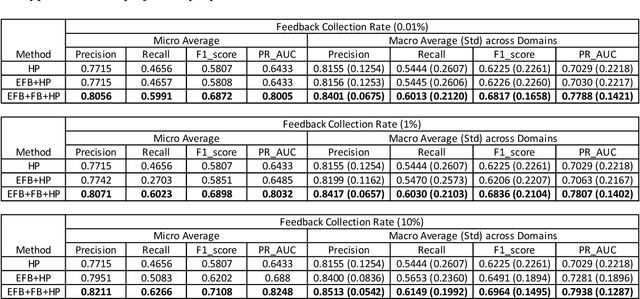
Measuring user satisfaction level is a challenging task, and a critical component in developing large-scale conversational agent systems serving the needs of real users. An widely used approach to tackle this is to collect human annotation data and use them for evaluation or modeling. Human annotation based approaches are easier to control, but hard to scale. A novel alternative approach is to collect user's direct feedback via a feedback elicitation system embedded to the conversational agent system, and use the collected user feedback to train a machine-learned model for generalization. User feedback is the best proxy for user satisfaction, but is not available for some ineligible intents and certain situations. Thus, these two types of approaches are complementary to each other. In this work, we tackle the user satisfaction assessment problem with a hybrid approach that fuses explicit user feedback, user satisfaction predictions inferred by two machine-learned models, one trained on user feedback data and the other human annotation data. The hybrid approach is based on a waterfall policy, and the experimental results with Amazon Alexa's large-scale datasets show significant improvements in inferring user satisfaction. A detailed hybrid architecture, an in-depth analysis on user feedback data, and an algorithm that generates data sets to properly simulate the live traffic are presented in this paper.
Neural Stochastic Block Model & Scalable Community-Based Graph Learning
May 16, 2020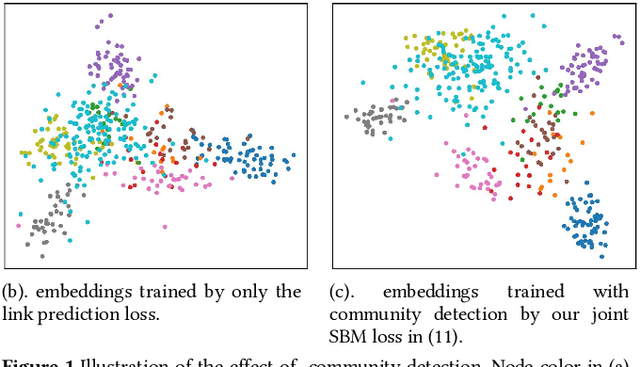
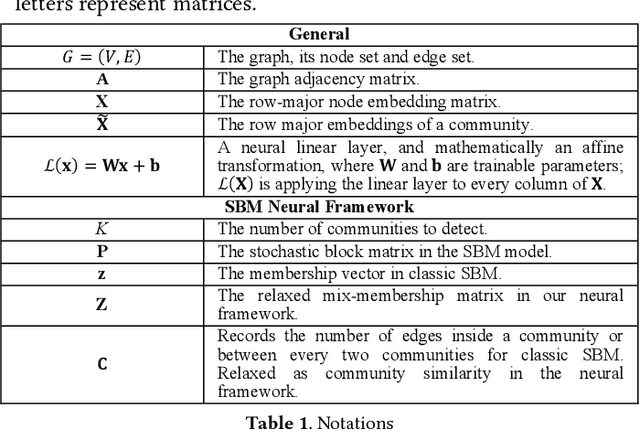
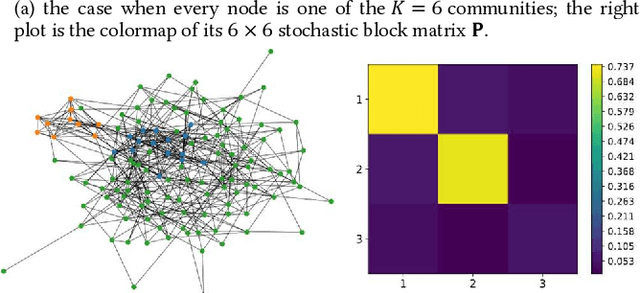
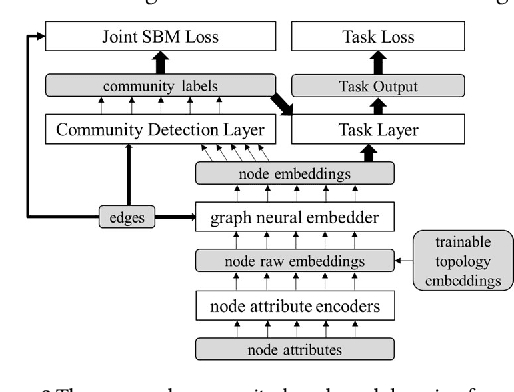
This paper proposes a novel scalable community-based neural framework for graph learning. The framework learns the graph topology through the task of community detection and link prediction by optimizing with our proposed joint SBM loss function, which results from a non-trivial adaptation of the likelihood function of the classic Stochastic Block Model (SBM). Compared with SBM, our framework is flexible, naturally allows soft labels and digestion of complex node attributes. The main goal is efficient valuation of complex graph data, therefore our design carefully aims at accommodating large data, and ensures there is a single forward pass for efficient evaluation. For large graph, it remains an open problem of how to efficiently leverage its underlying structure for various graph learning tasks. Previously it can be heavy work. With our community-based framework, this becomes less difficult and allows the task models to basically plug-in-and-play and perform joint training. We currently look into two particular applications, the graph alignment and the anomalous correlation detection, and discuss how to make use of our framework to tackle both problems. Extensive experiments are conducted to demonstrate the effectiveness of our approach. We also contributed tweaks of classic techniques which we find helpful for performance and scalability. For example, 1) the GAT+, an improved design of GAT (Graph Attention Network), the scaled-cosine similarity, and a unified implementation of the convolution/attention based and the random-walk based neural graph models.
Pre-Training for Query Rewriting in A Spoken Language Understanding System
Feb 13, 2020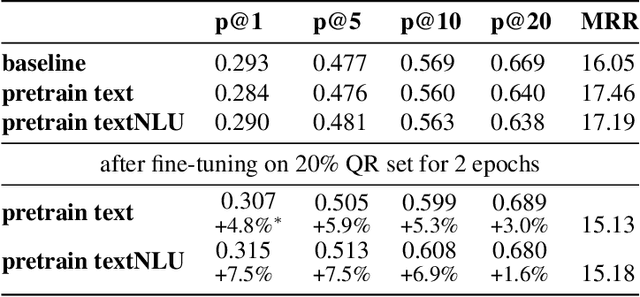
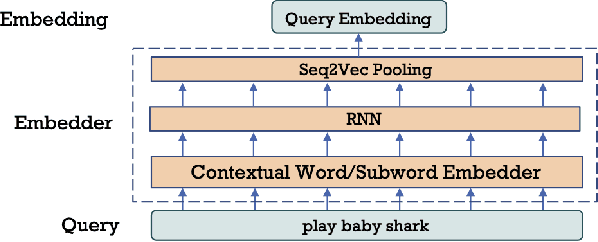
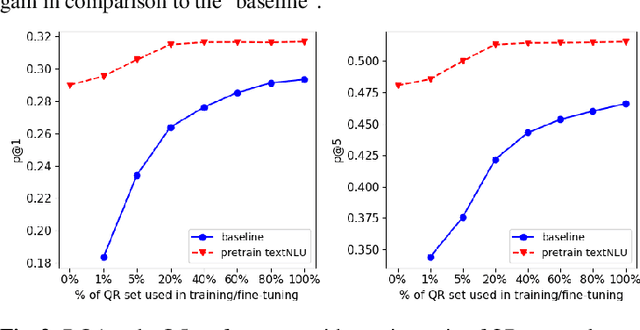
Query rewriting (QR) is an increasingly important technique to reduce customer friction caused by errors in a spoken language understanding pipeline, where the errors originate from various sources such as speech recognition errors, language understanding errors or entity resolution errors. In this work, we first propose a neural-retrieval based approach for query rewriting. Then, inspired by the wide success of pre-trained contextual language embeddings, and also as a way to compensate for insufficient QR training data, we propose a language-modeling (LM) based approach to pre-train query embeddings on historical user conversation data with a voice assistant. In addition, we propose to use the NLU hypotheses generated by the language understanding system to augment the pre-training. Our experiments show pre-training provides rich prior information and help the QR task achieve strong performance. We also show joint pre-training with NLU hypotheses has further benefit. Finally, after pre-training, we find a small set of rewrite pairs is enough to fine-tune the QR model to outperform a strong baseline by full training on all QR training data.
Knowledge Distillation from Internal Representations
Oct 08, 2019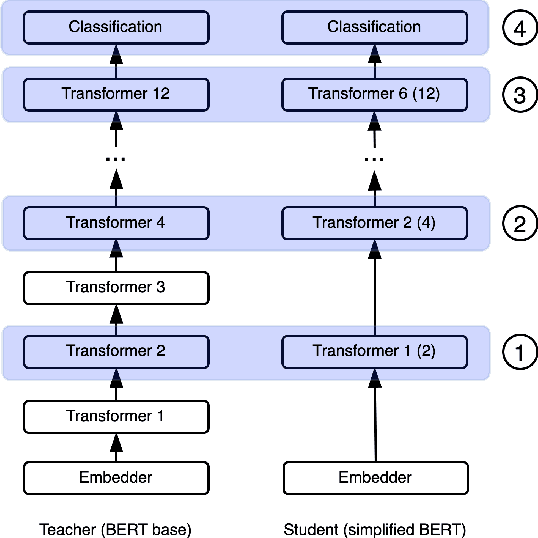
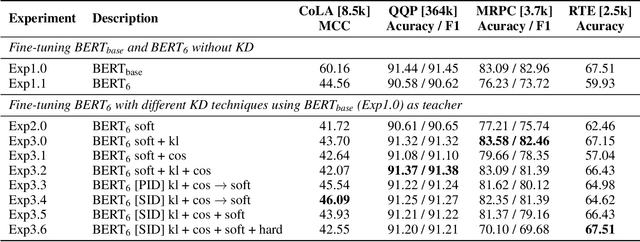
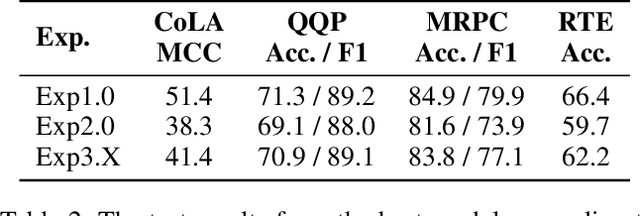
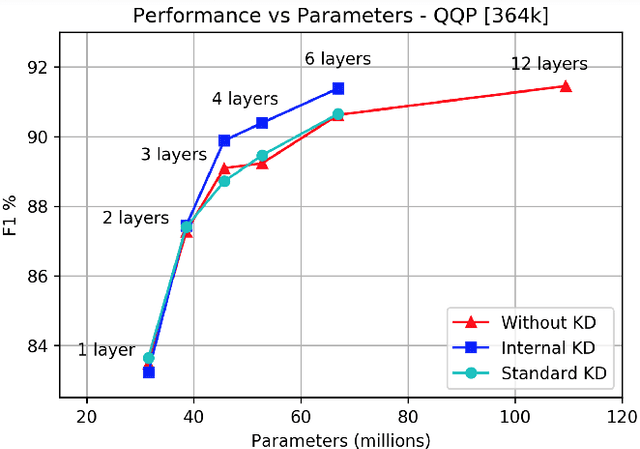
Knowledge distillation is typically conducted by training a small model (the student) to mimic a large and cumbersome model (the teacher). The idea is to compress the knowledge from the teacher by using its output probabilities as soft-labels to optimize the student. However, when the teacher is considerably large, there is no guarantee that the internal knowledge of the teacher will be transferred into the student; even if the student closely matches the soft-labels, its internal representations may be considerably different. This internal mismatch can undermine the generalization capabilities originally intended to be transferred from the teacher to the student. In this paper, we propose to distill the internal representations of a large model such as BERT into a simplified version of it. We formulate two ways to distill such representations and various algorithms to conduct the distillation. We experiment with datasets from the GLUE benchmark and consistently show that adding knowledge distillation from internal representations is a more powerful method than only using soft-label distillation.
Correlated Anomaly Detection from Large Streaming Data
Jan 14, 2019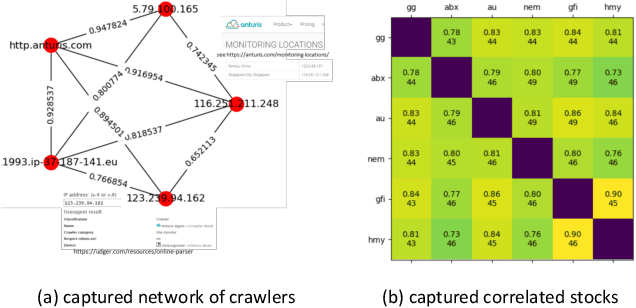
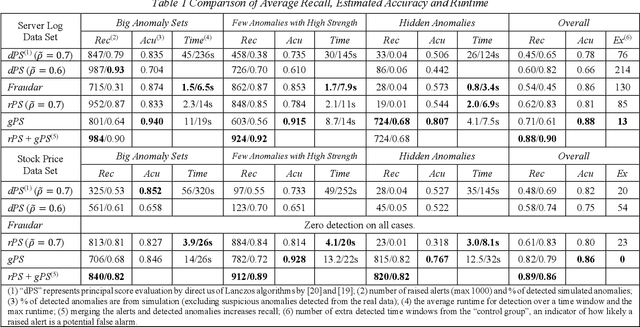
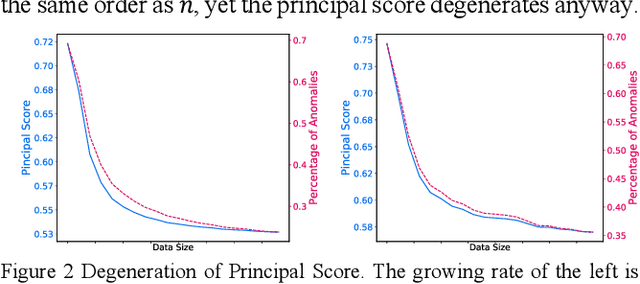
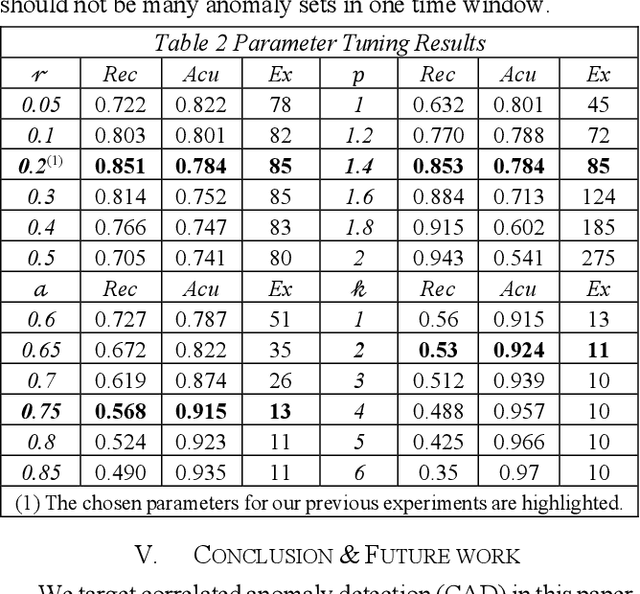
Correlated anomaly detection (CAD) from streaming data is a type of group anomaly detection and an essential task in useful real-time data mining applications like botnet detection, financial event detection, industrial process monitor, etc. The primary approach for this type of detection in previous researches is based on principal score (PS) of divided batches or sliding windows by computing top eigenvalues of the correlation matrix, e.g. the Lanczos algorithm. However, this paper brings up the phenomenon of principal score degeneration for large data set, and then mathematically and practically prove current PS-based methods are likely to fail for CAD on large-scale streaming data even if the number of correlated anomalies grows with the data size at a reasonable rate; in reality, anomalies tend to be the minority of the data, and this issue can be more serious. We propose a framework with two novel randomized algorithms rPS and gPS for better detection of correlated anomalies from large streaming data of various correlation strength. The experiment shows high and balanced recall and estimated accuracy of our framework for anomaly detection from a large server log data set and a U.S. stock daily price data set in comparison to direct principal score evaluation and some other recent group anomaly detection algorithms. Moreover, our techniques significantly improve the computation efficiency and scalability for principal score calculation.
DR-BiLSTM: Dependent Reading Bidirectional LSTM for Natural Language Inference
Apr 11, 2018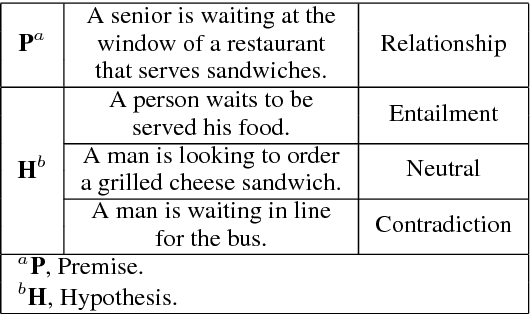
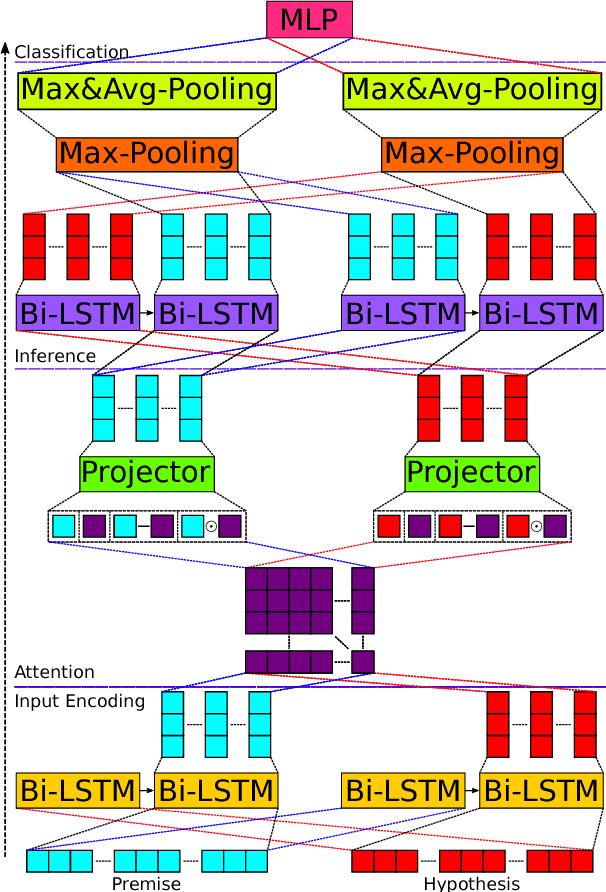
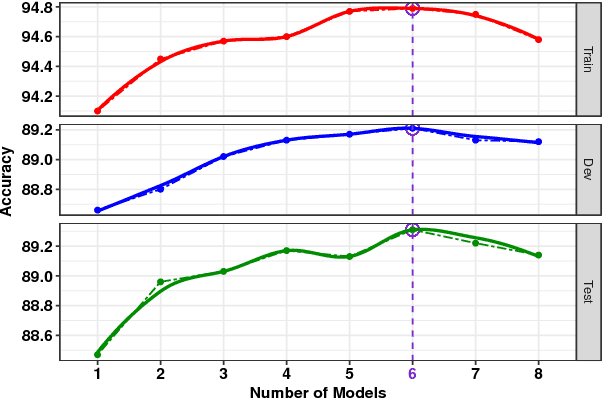
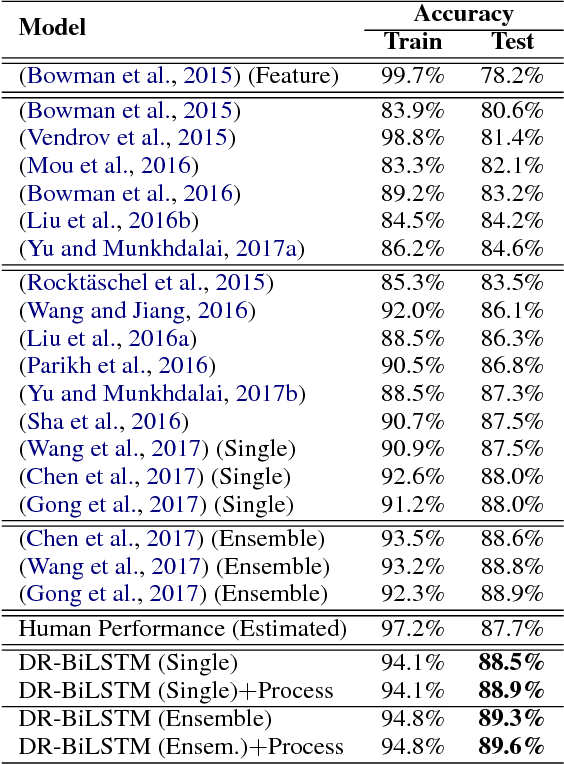
We present a novel deep learning architecture to address the natural language inference (NLI) task. Existing approaches mostly rely on simple reading mechanisms for independent encoding of the premise and hypothesis. Instead, we propose a novel dependent reading bidirectional LSTM network (DR-BiLSTM) to efficiently model the relationship between a premise and a hypothesis during encoding and inference. We also introduce a sophisticated ensemble strategy to combine our proposed models, which noticeably improves final predictions. Finally, we demonstrate how the results can be improved further with an additional preprocessing step. Our evaluation shows that DR-BiLSTM obtains the best single model and ensemble model results achieving the new state-of-the-art scores on the Stanford NLI dataset.