 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Data Meets LLM -- Explainable Financial Time Series Forecasting
Jun 19, 2023This paper presents a novel study on harnessing Large Language Models' (LLMs) outstanding knowledge and reasoning abilities for explainable financial time series forecasting. The application of machine learning models to financial time series comes with several challenges, including the difficulty in cross-sequence reasoning and inference, the hurdle of incorporating multi-modal signals from historical news, financial knowledge graphs, etc., and the issue of interpreting and explaining the model results. In this paper, we focus on NASDAQ-100 stocks, making use of publicly accessible historical stock price data, company metadata, and historical economic/financial news. We conduct experiments to illustrate the potential of LLMs in offering a unified solution to the aforementioned challenges. Our experiments include trying zero-shot/few-shot inference with GPT-4 and instruction-based fine-tuning with a public LLM model Open LLaMA. We demonstrate our approach outperforms a few baselines, including the widely applied classic ARMA-GARCH model and a gradient-boosting tree model. Through the performance comparison results and a few examples, we find LLMs can make a well-thought decision by reasoning over information from both textual news and price time series and extracting insights, leveraging cross-sequence information, and utilizing the inherent knowledge embedded within the LLM. Additionally, we show that a publicly available LLM such as Open-LLaMA, after fine-tuning, can comprehend the instruction to generate explainable forecasts and achieve reasonable performance, albeit relatively inferior in comparison to GPT-4.
The Chai Platform's AI Safety Framework
Jun 05, 2023Chai empowers users to create and interact with customized chatbots, offering unique and engaging experiences. Despite the exciting prospects, the work recognizes the inherent challenges of a commitment to modern safety standards. Therefore, this paper presents the integrated AI safety principles into Chai to prioritize user safety, data protection, and ethical technology use. The paper specifically explores the multidimensional domain of AI safety research, demonstrating its application in Chai's conversational chatbot platform. It presents Chai's AI safety principles, informed by well-established AI research centres and adapted for chat AI. This work proposes the following safety framework: Content Safeguarding; Stability and Robustness; and Operational Transparency and Traceability. The subsequent implementation of these principles is outlined, followed by an experimental analysis of Chai's AI safety framework's real-world impact. We emphasise the significance of conscientious application of AI safety principles and robust safety measures. The successful implementation of the safe AI framework in Chai indicates the practicality of mitigating potential risks for responsible and ethical use of AI technologies. The ultimate vision is a transformative AI tool fostering progress and innovation while prioritizing user safety and ethical standards.
Safer Conversational AI as a Source of User Delight
Apr 18, 2023This work explores the impact of moderation on users' enjoyment of conversational AI systems. While recent advancements in Large Language Models (LLMs) have led to highly capable conversational AIs that are increasingly deployed in real-world settings, there is a growing concern over AI safety and the need to moderate systems to encourage safe language and prevent harm. However, some users argue that current approaches to moderation limit the technology, compromise free expression, and limit the value delivered by the technology. This study takes an unbiased stance and shows that moderation does not necessarily detract from user enjoyment. Heavy handed moderation does seem to have a nefarious effect, but models that are moderated to be safer can lead to a better user experience. By deploying various conversational AIs in the Chai platform, the study finds that user retention can increase with a level of moderation and safe system design. These results demonstrate the importance of appropriately defining safety in models in a way that is both responsible and focused on serving users.
Rewarding Chatbots for Real-World Engagement with Millions of Users
Mar 10, 2023The emergence of pretrained large language models has led to the deployment of a range of social chatbots for chitchat. Although these chatbots demonstrate language ability and fluency, they are not guaranteed to be engaging and can struggle to retain users. This work investigates the development of social chatbots that prioritize user engagement to enhance retention, specifically examining the use of human feedback to efficiently develop highly engaging chatbots. The proposed approach uses automatic pseudo-labels collected from user interactions to train a reward model that can be used to reject low-scoring sample responses generated by the chatbot model at inference time. Intuitive evaluation metrics, such as mean conversation length (MCL), are introduced as proxies to measure the level of engagement of deployed chatbots. A/B testing on groups of 10,000 new daily chatbot users on the Chai Research platform shows that this approach increases the MCL by up to 70%, which translates to a more than 30% increase in user retention for a GPT-J 6B model. Future work aims to use the reward model to realise a data fly-wheel, where the latest user conversations can be used to alternately fine-tune the language model and the reward model.
Detection of Audio-Video Synchronization Errors Via Event Detection
Apr 20, 2021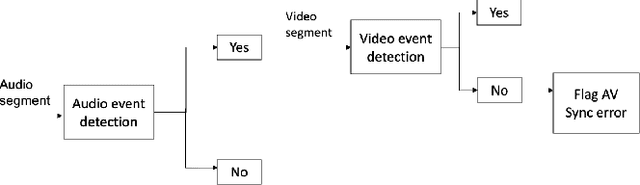
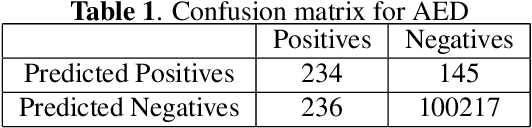
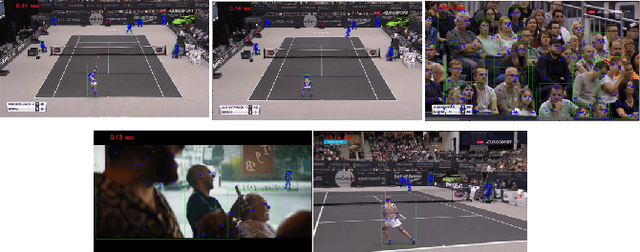

We present a new method and a large-scale database to detect audio-video synchronization(A/V sync) errors in tennis videos. A deep network is trained to detect the visual signature of the tennis ball being hit by the racquet in the video stream. Another deep network is trained to detect the auditory signature of the same event in the audio stream. During evaluation, the audio stream is searched by the audio network for the audio event of the ball being hit. If the event is found in audio, the neighboring interval in video is searched for the corresponding visual signature. If the event is not found in the video stream but is found in the audio stream, A/V sync error is flagged. We developed a large-scaled database of 504,300 frames from 6 hours of videos of tennis events, simulated A/V sync errors, and found our method achieves high accuracy on the task.