 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDR or SDR? A Subjective and Objective Study of Scaled and Compressed Videos
Apr 25, 2023



We conducted a large-scale study of human perceptual quality judgments of High Dynamic Range (HDR) and Standard Dynamic Range (SDR) videos subjected to scaling and compression levels and viewed on three different display devices. HDR videos are able to present wider color gamuts, better contrasts, and brighter whites and darker blacks than SDR videos. While conventional expectations are that HDR quality is better than SDR quality, we have found subject preference of HDR versus SDR depends heavily on the display device, as well as on resolution scaling and bitrate. To study this question, we collected more than 23,000 quality ratings from 67 volunteers who watched 356 videos on OLED, QLED, and LCD televisions. Since it is of interest to be able to measure the quality of videos under these scenarios, e.g. to inform decisions regarding scaling, compression, and SDR vs HDR, we tested several well-known full-reference and no-reference video quality models on the new database. Towards advancing progress on this problem, we also developed a novel no-reference model called HDRPatchMAX, that uses both classical and bit-depth sensitive distortion statistics more accurately than existing metrics.
HDR-ChipQA: No-Reference Quality Assessment on High Dynamic Range Videos
Apr 25, 2023We present a no-reference video quality model and algorithm that delivers standout performance for High Dynamic Range (HDR) videos, which we call HDR-ChipQA. HDR videos represent wider ranges of luminances, details, and colors than Standard Dynamic Range (SDR) videos. The growing adoption of HDR in massively scaled video networks has driven the need for video quality assessment (VQA) algorithms that better account for distortions on HDR content. In particular, standard VQA models may fail to capture conspicuous distortions at the extreme ends of the dynamic range, because the features that drive them may be dominated by distortions {that pervade the mid-ranges of the signal}. We introduce a new approach whereby a local expansive nonlinearity emphasizes distortions occurring at the higher and lower ends of the {local} luma range, allowing for the definition of additional quality-aware features that are computed along a separate path. These features are not HDR-specific, and also improve VQA on SDR video contents, albeit to a reduced degree. We show that this preprocessing step significantly boosts the power of distortion-sensitive natural video statistics (NVS) features when used to predict the quality of HDR content. In similar manner, we separately compute novel wide-gamut color features using the same nonlinear processing steps. We have found that our model significantly outperforms SDR VQA algorithms on the only publicly available, comprehensive HDR database, while also attaining state-of-the-art performance on SDR content.
Making Video Quality Assessment Models Robust to Bit Depth
Apr 25, 2023We introduce a novel feature set, which we call HDRMAX features, that when included into Video Quality Assessment (VQA) algorithms designed for Standard Dynamic Range (SDR) videos, sensitizes them to distortions of High Dynamic Range (HDR) videos that are inadequately accounted for by these algorithms. While these features are not specific to HDR, and also augment the equality prediction performances of VQA models on SDR content, they are especially effective on HDR. HDRMAX features modify powerful priors drawn from Natural Video Statistics (NVS) models by enhancing their measurability where they visually impact the brightest and darkest local portions of videos, thereby capturing distortions that are often poorly accounted for by existing VQA models. As a demonstration of the efficacy of our approach, we show that, while current state-of-the-art VQA models perform poorly on 10-bit HDR databases, their performances are greatly improved by the inclusion of HDRMAX features when tested on HDR and 10-bit distorted videos.
Subjective Assessment of High Dynamic Range Videos Under Different Ambient Conditions
Sep 20, 2022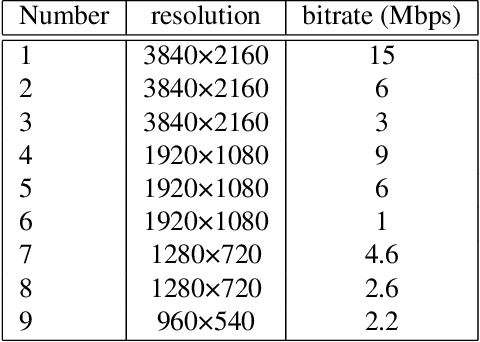

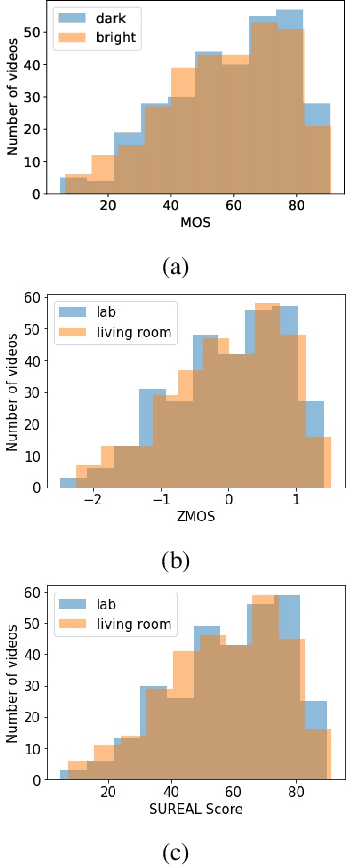
High Dynamic Range (HDR) videos can represent a much greater range of brightness and color than Standard Dynamic Range (SDR) videos and are rapidly becoming an industry standard. HDR videos have more challenging capture, transmission, and display requirements than legacy SDR videos. With their greater bit depth, advanced electro-optical transfer functions, and wider color gamuts, comes the need for video quality algorithms that are specifically designed to predict the quality of HDR videos. Towards this end, we present the first publicly released large-scale subjective study of HDR videos. We study the effect of distortions such as compression and aliasing on the quality of HDR videos. We also study the effect of ambient illumination on perceptual quality of HDR videos by conducting the study in both a dark lab environment and a brighter living-room environment. A total of 66 subjects participated in the study and more than 20,000 opinion scores were collected, which makes this the largest in-lab study of HDR video quality ever. We anticipate that the dataset will be a valuable resource for researchers to develop better models of perceptual quality for HDR videos.
Subjective and Objective Quality Assessment of High-Motion Sports Videos at Low-Bitrates
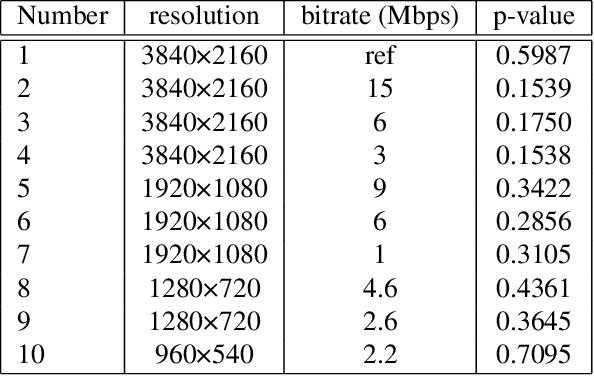
Jul 12, 2022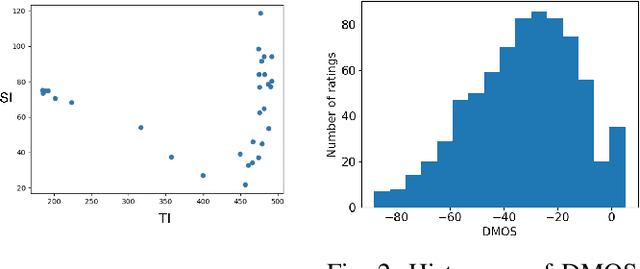
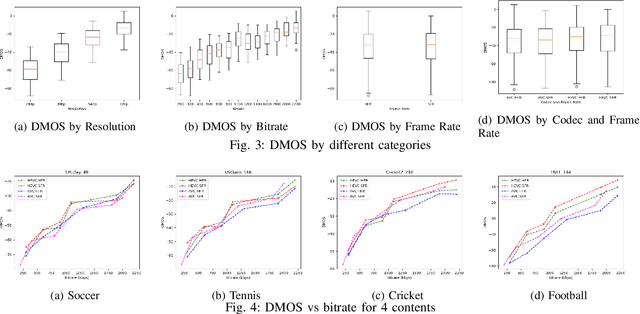
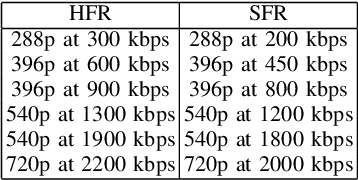
Videos often have to be transmitted and stored at low bitrates due to poor network connectivity during adaptive bitrate streaming. Designing optimal bitrate ladders that would select the perceptually-optimized resolution, frame-rate, and compression level for low-bitrate videos for adaptive streaming across the internet is therefore a task of great interest. Towards that end, we conducted the first large-scale study of medium and low-bitrate videos from live sports for two codecs (Elemental AVC and HEVC) and created the Amazon Prime Video Low-Bitrate Sports (APV LBS) dataset. The study involved 94 participants and 742 videos, with more than 23,000 human opinion scores collected in total. We analyzed the data obtained and we also conducted an extensive evaluation of objective Video Quality Assessment (VQA) algorithms and benchmarked their performance, and make recommendations on bitrate ladder design. We're making the metadata and VQA features available at https://github.com/JoshuaEbenezer/lbmfr-public.
ChipQA: No-Reference Video Quality Prediction via Space-Time Chips
Sep 17, 2021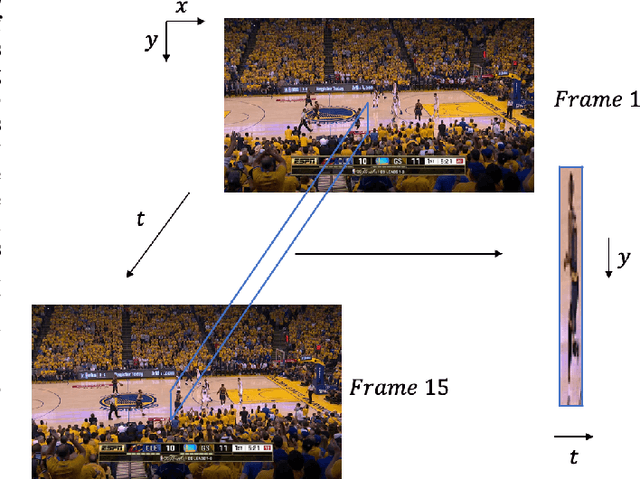
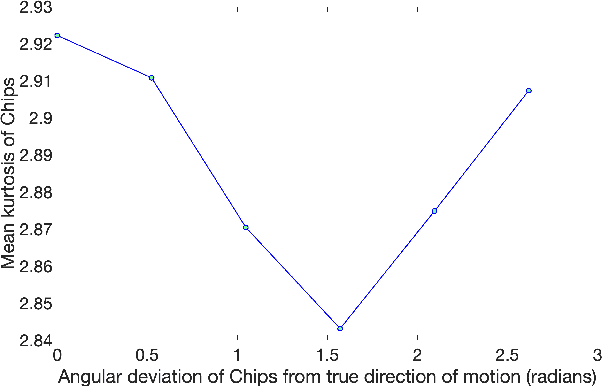
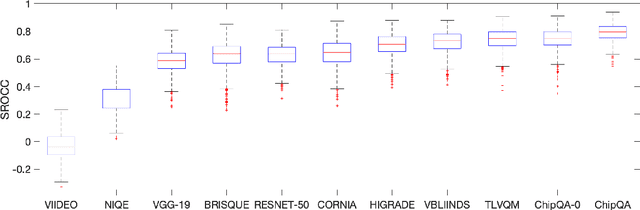
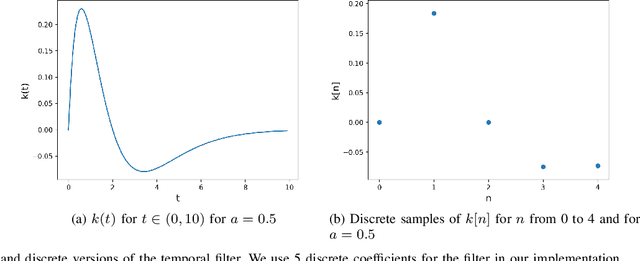
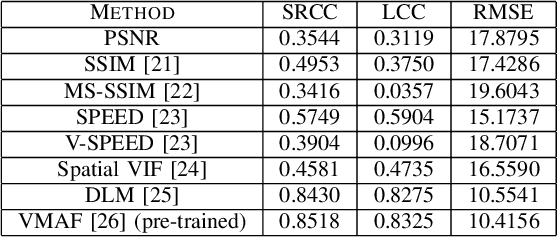
We propose a new model for no-reference video quality assessment (VQA). Our approach uses a new idea of highly-localized space-time (ST) slices called Space-Time Chips (ST Chips). ST Chips are localized cuts of video data along directions that \textit{implicitly} capture motion. We use perceptually-motivated bandpass and normalization models to first process the video data, and then select oriented ST Chips based on how closely they fit parametric models of natural video statistics. We show that the parameters that describe these statistics can be used to reliably predict the quality of videos, without the need for a reference video. The proposed method implicitly models ST video naturalness, and deviations from naturalness. We train and test our model on several large VQA databases, and show that our model achieves state-of-the-art performance at reduced cost, without requiring motion computation.
Assessment of Subjective and Objective Quality of Live Streaming Sports Videos
Jun 15, 2021
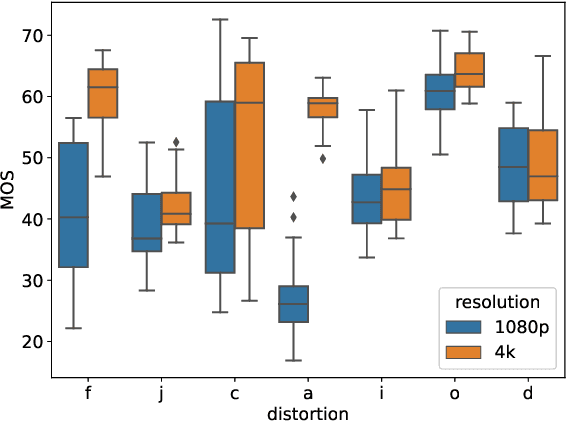
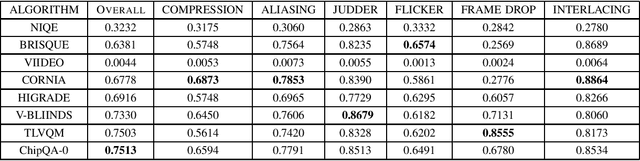
Video live streaming is gaining prevalence among video streaming services, especially for the delivery of popular sporting events. Many objective Video Quality Assessment (VQA) models have been developed to predict the perceptual quality of videos. Appropriate databases that exemplify the distortions encountered in live streaming videos are important to designing and learning objective VQA models. Towards making progress in this direction, we built a video quality database specifically designed for live streaming VQA research. The new video database is called the Laboratory for Image and Video Engineering (LIVE) Live stream Database. The LIVE Livestream Database includes 315 videos of 45 contents impaired by 6 types of distortions. We also performed a subjective quality study using the new database, whereby more than 12,000 human opinions were gathered from 40 subjects. We demonstrate the usefulness of the new resource by performing a holistic evaluation of the performance of current state-of-the-art (SOTA) VQA models. The LIVE Livestream database is being made publicly available for these purposes at https://live.ece.utexas.edu/research/LIVE_APV_Study/apv_index.html.
Detection of Audio-Video Synchronization Errors Via Event Detection
Apr 20, 2021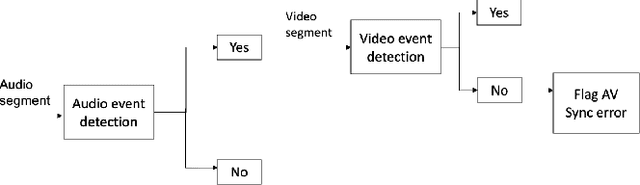
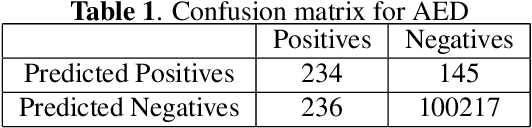
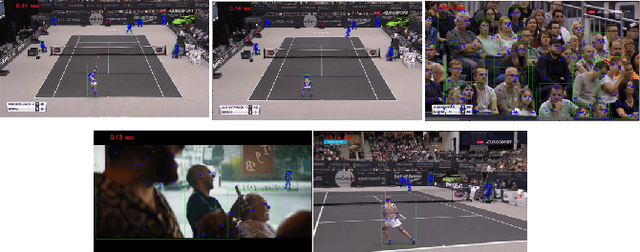

We present a new method and a large-scale database to detect audio-video synchronization(A/V sync) errors in tennis videos. A deep network is trained to detect the visual signature of the tennis ball being hit by the racquet in the video stream. Another deep network is trained to detect the auditory signature of the same event in the audio stream. During evaluation, the audio stream is searched by the audio network for the audio event of the ball being hit. If the event is found in audio, the neighboring interval in video is searched for the corresponding visual signature. If the event is not found in the video stream but is found in the audio stream, A/V sync error is flagged. We developed a large-scaled database of 504,300 frames from 6 hours of videos of tennis events, simulated A/V sync errors, and found our method achieves high accuracy on the task.