 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning LLMs for Comparative Assessment Tasks
Sep 24, 2024



Automated assessment in natural language generation is a challenging task. Instruction-tuned large language models (LLMs) have shown promise in reference-free evaluation, particularly through comparative assessment. However, the quadratic computational complexity of pairwise comparisons limits its scalability. To address this, efficient comparative assessment has been explored by applying comparative strategies on zero-shot LLM probabilities. We propose a framework for finetuning LLMs for comparative assessment to align the model's output with the target distribution of comparative probabilities. By training on soft probabilities, our approach improves state-of-the-art performance while maintaining high performance with an efficient subset of comparisons.
CrossCheckGPT: Universal Hallucination Ranking for Multimodal Foundation Models
May 22, 2024Multimodal foundation models are prone to hallucination, generating outputs that either contradict the input or are not grounded by factual information. Given the diversity in architectures, training data and instruction tuning techniques, there can be large variations in systems' susceptibility to hallucinations. To assess system hallucination robustness, hallucination ranking approaches have been developed for specific tasks such as image captioning, question answering, summarization, or biography generation. However, these approaches typically compare model outputs to gold-standard references or labels, limiting hallucination benchmarking for new domains. This work proposes "CrossCheckGPT", a reference-free universal hallucination ranking for multimodal foundation models. The core idea of CrossCheckGPT is that the same hallucinated content is unlikely to be generated by different independent systems, hence cross-system consistency can provide meaningful and accurate hallucination assessment scores. CrossCheckGPT can be applied to any model or task, provided that the information consistency between outputs can be measured through an appropriate distance metric. Focusing on multimodal large language models that generate text, we explore two information consistency measures: CrossCheck-explicit and CrossCheck-implicit. We showcase the applicability of our method for hallucination ranking across various modalities, namely the text, image, and audio-visual domains. Further, we propose the first audio-visual hallucination benchmark, "AVHalluBench", and illustrate the effectiveness of CrossCheckGPT, achieving correlations of 98% and 89% with human judgements on MHaluBench and AVHalluBench, respectively.
Efficient LLM Comparative Assessment: a Product of Experts Framework for Pairwise Comparisons
May 09, 2024



LLM-as-a-judge approaches are a practical and effective way of assessing a range of text tasks, aligning with human judgements especially when applied in a comparative assessment fashion. However, when using pairwise comparisons to rank a set of candidates the computational costs scale quadratically with the number of candidates, which can have practical limitations. This paper introduces a Product of Expert (PoE) framework for efficient LLM Comparative Assessment. Here individual comparisons are considered experts that provide information on a pair's score difference. The PoE framework combines the information from these experts to yield an expression that can be maximized with respect to the underlying set of candidates, and is highly flexible where any form of expert can be assumed. When Gaussian experts are used one can derive simple closed-form solutions for the optimal candidate ranking, as well as expressions for selecting which comparisons should be made to maximize the probability of this ranking. Our approach enables efficient comparative assessment, where by using only a small subset of the possible comparisons, one can generate score predictions that correlate as well to human judgements as the predictions when all comparisons are used. We evaluate the approach on multiple NLG tasks and demonstrate that our framework can yield considerable computational savings when performing pairwise comparative assessment. When N is large, with as few as 2% of comparisons the PoE solution can achieve similar performance to when all comparisons are used.
WaterJudge: Quality-Detection Trade-off when Watermarking Large Language Models
Mar 28, 2024



Watermarking generative-AI systems, such as LLMs, has gained considerable interest, driven by their enhanced capabilities across a wide range of tasks. Although current approaches have demonstrated that small, context-dependent shifts in the word distributions can be used to apply and detect watermarks, there has been little work in analyzing the impact that these perturbations have on the quality of generated texts. Balancing high detectability with minimal performance degradation is crucial in terms of selecting the appropriate watermarking setting; therefore this paper proposes a simple analysis framework where comparative assessment, a flexible NLG evaluation framework, is used to assess the quality degradation caused by a particular watermark setting. We demonstrate that our framework provides easy visualization of the quality-detection trade-off of watermark settings, enabling a simple solution to find an LLM watermark operating point that provides a well-balanced performance. This approach is applied to two different summarization systems and a translation system, enabling cross-model analysis for a task, and cross-task analysis.
Teacher-Student Training for Debiasing: General Permutation Debiasing for Large Language Models
Mar 20, 2024



Large Language Models (LLMs) have demonstrated impressive zero-shot capabilities and versatility in NLP tasks, however they sometimes fail to maintain crucial invariances for specific tasks. One example is permutation sensitivity, where LLMs' outputs may significantly vary depending on the order of the input options. While debiasing techniques can mitigate these issues, and yield better performance and reliability, they often come with a high computational cost at inference. This paper addresses this inefficiency at inference time. The aim is to distill the capabilities of a computationally intensive, debiased, teacher model into a more compact student model. We explore two variants of student models: one based on pure distillation, and the other on an error-correction approach for more complex tasks, where the student corrects a single biased decision from the teacher to achieve a debiased output. Our approach is general and can be applied to both black-box and white-box LLMs. Furthermore, we demonstrate that our compact, encoder-only student models can outperform their larger, biased teacher counterparts, achieving better results with significantly fewer parameters.
Is LLM-as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment
Feb 21, 2024



Large Language Models (LLMs) are powerful zero-shot assessors and are increasingly used in real-world situations such as for written exams or benchmarking systems. Despite this, no existing work has analyzed the vulnerability of judge-LLMs against adversaries attempting to manipulate outputs. This work presents the first study on the adversarial robustness of assessment LLMs, where we search for short universal phrases that when appended to texts can deceive LLMs to provide high assessment scores. Experiments on SummEval and TopicalChat demonstrate that both LLM-scoring and pairwise LLM-comparative assessment are vulnerable to simple concatenation attacks, where in particular LLM-scoring is very susceptible and can yield maximum assessment scores irrespective of the input text quality. Interestingly, such attacks are transferable and phrases learned on smaller open-source LLMs can be applied to larger closed-source models, such as GPT3.5. This highlights the pervasive nature of the adversarial vulnerabilities across different judge-LLM sizes, families and methods. Our findings raise significant concerns on the reliability of LLMs-as-a-judge methods, and underscore the importance of addressing vulnerabilities in LLM assessment methods before deployment in high-stakes real-world scenarios.
Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
Jan 09, 2024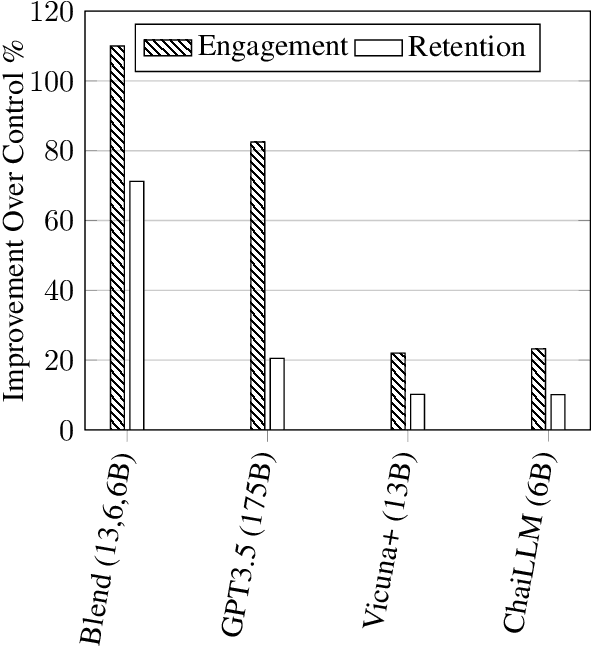
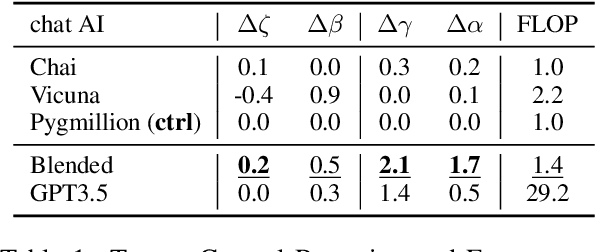
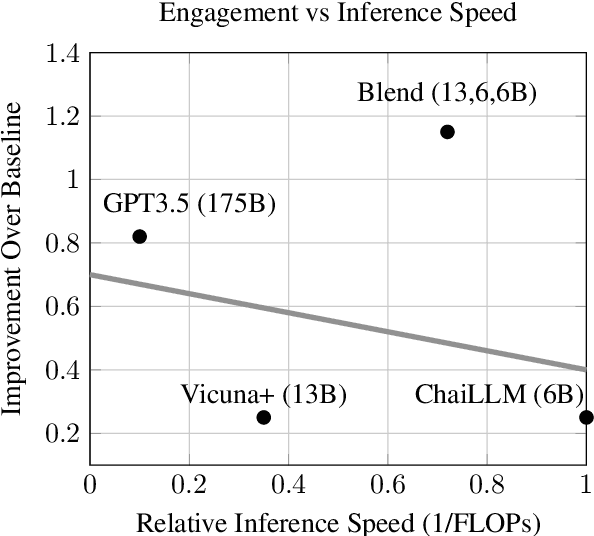
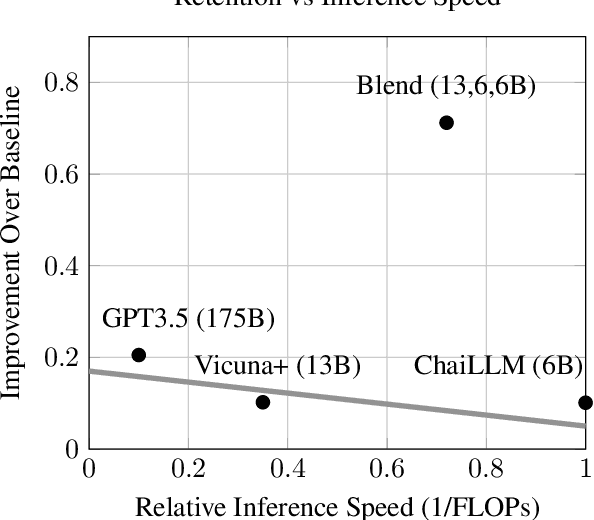
In conversational AI research, there's a noticeable trend towards developing models with a larger number of parameters, exemplified by models like ChatGPT. While these expansive models tend to generate increasingly better chat responses, they demand significant computational resources and memory. This study explores a pertinent question: Can a combination of smaller models collaboratively achieve comparable or enhanced performance relative to a singular large model? We introduce an approach termed "blending", a straightforward yet effective method of integrating multiple chat AIs. Our empirical evidence suggests that when specific smaller models are synergistically blended, they can potentially outperform or match the capabilities of much larger counterparts. For instance, integrating just three models of moderate size (6B/13B paramaeters) can rival or even surpass the performance metrics of a substantially larger model like ChatGPT (175B+ paramaters). This hypothesis is rigorously tested using A/B testing methodologies with a large user base on the Chai research platform over a span of thirty days. The findings underscore the potential of the "blending" strategy as a viable approach for enhancing chat AI efficacy without a corresponding surge in computational demands.
Investigating the Emergent Audio Classification Ability of ASR Foundation Models
Nov 15, 2023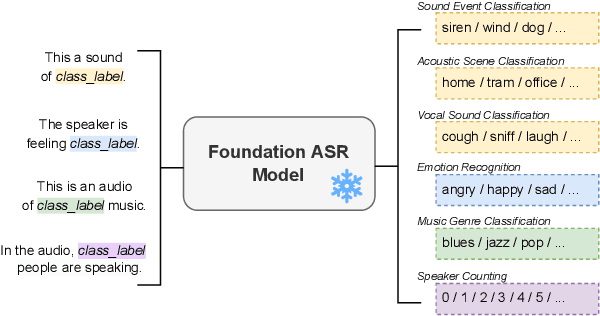
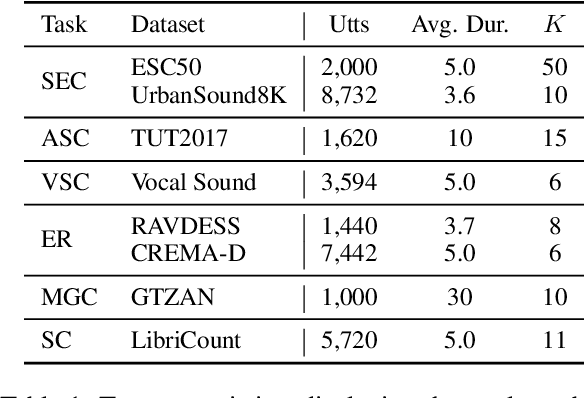


Text and vision foundation models can perform many tasks in a zero-shot setting, a desirable property that enables these systems to be applied in general and low-resource settings. However, there has been significantly less work on the zero-shot abilities of ASR foundation models, with these systems typically fine-tuned to specific tasks or constrained to applications that match their training criterion and data annotation. In this work we investigate the ability of Whisper and MMS, ASR foundation models trained primarily for speech recognition, to perform zero-shot audio classification. We use simple template-based text prompts at the decoder and use the resulting decoding probabilities to generate zero-shot predictions. Without training the model on extra data or adding any new parameters, we demonstrate that Whisper shows promising zero-shot classification performance on a range of 8 audio-classification datasets, outperforming existing state-of-the-art zero-shot baseline's accuracy by an average of 9%. One important step to unlock the emergent ability is debiasing, where a simple unsupervised reweighting method of the class probabilities yields consistent significant performance gains. We further show that performance increases with model size, implying that as ASR foundation models scale up, they may exhibit improved zero-shot performance.
Assessing Distractors in Multiple-Choice Tests
Nov 08, 2023



Multiple-choice tests are a common approach for assessing candidates' comprehension skills. Standard multiple-choice reading comprehension exams require candidates to select the correct answer option from a discrete set based on a question in relation to a contextual passage. For appropriate assessment, the distractor answer options must by definition be incorrect but plausible and diverse. However, generating good quality distractors satisfying these criteria is a challenging task for content creators. We propose automated assessment metrics for the quality of distractors in multiple-choice reading comprehension tests. Specifically, we define quality in terms of the incorrectness, plausibility and diversity of the distractor options. We assess incorrectness using the classification ability of a binary multiple-choice reading comprehension system. Plausibility is assessed by considering the distractor confidence - the probability mass associated with the distractor options for a standard multi-class multiple-choice reading comprehension system. Diversity is assessed by pairwise comparison of an embedding-based equivalence metric between the distractors of a question. To further validate the plausibility metric we compare against candidate distributions over multiple-choice questions and agreement with a ChatGPT model's interpretation of distractor plausibility and diversity.
Zero-shot Audio Topic Reranking using Large Language Models
Sep 14, 2023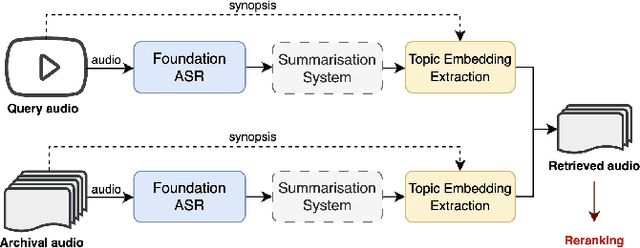

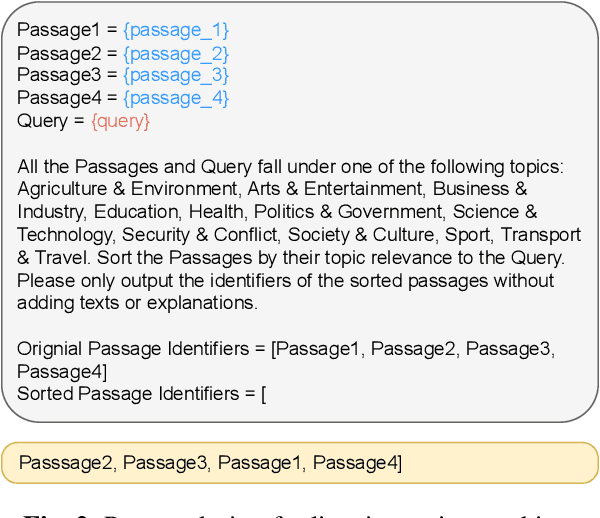

The Multimodal Video Search by Examples (MVSE) project investigates using video clips as the query term for information retrieval, rather than the more traditional text query. This enables far richer search modalities such as images, speaker, content, topic, and emotion. A key element for this process is highly rapid, flexible, search to support large archives, which in MVSE is facilitated by representing video attributes by embeddings. This work aims to mitigate any performance loss from this rapid archive search by examining reranking approaches. In particular, zero-shot reranking methods using large language models are investigated as these are applicable to any video archive audio content. Performance is evaluated for topic-based retrieval on a publicly available video archive, the BBC Rewind corpus. Results demonstrate that reranking can achieve improved retrieval ranking without the need for any task-specific training data.