 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning LLMs for Comparative Assessment Tasks
Sep 24, 2024



Automated assessment in natural language generation is a challenging task. Instruction-tuned large language models (LLMs) have shown promise in reference-free evaluation, particularly through comparative assessment. However, the quadratic computational complexity of pairwise comparisons limits its scalability. To address this, efficient comparative assessment has been explored by applying comparative strategies on zero-shot LLM probabilities. We propose a framework for finetuning LLMs for comparative assessment to align the model's output with the target distribution of comparative probabilities. By training on soft probabilities, our approach improves state-of-the-art performance while maintaining high performance with an efficient subset of comparisons.
Question-Based Retrieval using Atomic Units for Enterprise RAG
May 20, 2024Enterprise retrieval augmented generation (RAG) offers a highly flexible framework for combining powerful large language models (LLMs) with internal, possibly temporally changing, documents. In RAG, documents are first chunked. Relevant chunks are then retrieved for a specific user query, which are passed as context to a synthesizer LLM to generate the query response. However, the retrieval step can limit performance, as incorrect chunks can lead the synthesizer LLM to generate a false response. This work proposes a zero-shot adaptation of standard dense retrieval steps for more accurate chunk recall. Specifically, a chunk is first decomposed into atomic statements. A set of synthetic questions are then generated on these atoms (with the chunk as the context). Dense retrieval involves finding the closest set of synthetic questions, and associated chunks, to the user query. It is found that retrieval with the atoms leads to higher recall than retrieval with chunks. Further performance gain is observed with retrieval using the synthetic questions generated over the atoms. Higher recall at the retrieval step enables higher performance of the enterprise LLM using the RAG pipeline.
Efficient LLM Comparative Assessment: a Product of Experts Framework for Pairwise Comparisons
May 09, 2024



LLM-as-a-judge approaches are a practical and effective way of assessing a range of text tasks, aligning with human judgements especially when applied in a comparative assessment fashion. However, when using pairwise comparisons to rank a set of candidates the computational costs scale quadratically with the number of candidates, which can have practical limitations. This paper introduces a Product of Expert (PoE) framework for efficient LLM Comparative Assessment. Here individual comparisons are considered experts that provide information on a pair's score difference. The PoE framework combines the information from these experts to yield an expression that can be maximized with respect to the underlying set of candidates, and is highly flexible where any form of expert can be assumed. When Gaussian experts are used one can derive simple closed-form solutions for the optimal candidate ranking, as well as expressions for selecting which comparisons should be made to maximize the probability of this ranking. Our approach enables efficient comparative assessment, where by using only a small subset of the possible comparisons, one can generate score predictions that correlate as well to human judgements as the predictions when all comparisons are used. We evaluate the approach on multiple NLG tasks and demonstrate that our framework can yield considerable computational savings when performing pairwise comparative assessment. When N is large, with as few as 2% of comparisons the PoE solution can achieve similar performance to when all comparisons are used.
Question Difficulty Ranking for Multiple-Choice Reading Comprehension
Apr 16, 2024



Multiple-choice (MC) tests are an efficient method to assess English learners. It is useful for test creators to rank candidate MC questions by difficulty during exam curation. Typically, the difficulty is determined by having human test takers trial the questions in a pretesting stage. However, this is expensive and not scalable. Therefore, we explore automated approaches to rank MC questions by difficulty. However, there is limited data for explicit training of a system for difficulty scores. Hence, we compare task transfer and zero-shot approaches: task transfer adapts level classification and reading comprehension systems for difficulty ranking while zero-shot prompting of instruction finetuned language models contrasts absolute assessment against comparative. It is found that level classification transfers better than reading comprehension. Additionally, zero-shot comparative assessment is more effective at difficulty ranking than the absolute assessment and even the task transfer approaches at question difficulty ranking with a Spearman's correlation of 40.4%. Combining the systems is observed to further boost the correlation.
An Information-Theoretic Approach to Analyze NLP Classification Tasks
Feb 01, 2024Understanding the importance of the inputs on the output is useful across many tasks. This work provides an information-theoretic framework to analyse the influence of inputs for text classification tasks. Natural language processing (NLP) tasks take either a single element input or multiple element inputs to predict an output variable, where an element is a block of text. Each text element has two components: an associated semantic meaning and a linguistic realization. Multiple-choice reading comprehension (MCRC) and sentiment classification (SC) are selected to showcase the framework. For MCRC, it is found that the context influence on the output compared to the question influence reduces on more challenging datasets. In particular, more challenging contexts allow a greater variation in complexity of questions. Hence, test creators need to carefully consider the choice of the context when designing multiple-choice questions for assessment. For SC, it is found the semantic meaning of the input text dominates (above 80\% for all datasets considered) compared to its linguistic realisation when determining the sentiment. The framework is made available at: https://github.com/WangLuran/nlp-element-influence
Structural-Based Uncertainty in Deep Learning Across Anatomical Scales: Analysis in White Matter Lesion Segmentation
Nov 15, 2023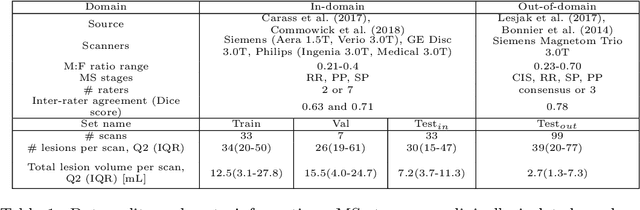


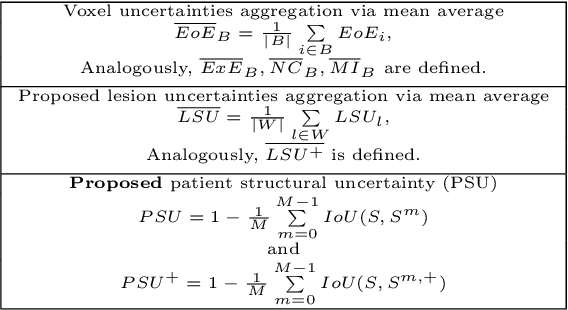
This paper explores uncertainty quantification (UQ) as an indicator of the trustworthiness of automated deep-learning (DL) tools in the context of white matter lesion (WML) segmentation from magnetic resonance imaging (MRI) scans of multiple sclerosis (MS) patients. Our study focuses on two principal aspects of uncertainty in structured output segmentation tasks. Firstly, we postulate that a good uncertainty measure should indicate predictions likely to be incorrect with high uncertainty values. Second, we investigate the merit of quantifying uncertainty at different anatomical scales (voxel, lesion, or patient). We hypothesize that uncertainty at each scale is related to specific types of errors. Our study aims to confirm this relationship by conducting separate analyses for in-domain and out-of-domain settings. Our primary methodological contributions are (i) the development of novel measures for quantifying uncertainty at lesion and patient scales, derived from structural prediction discrepancies, and (ii) the extension of an error retention curve analysis framework to facilitate the evaluation of UQ performance at both lesion and patient scales. The results from a multi-centric MRI dataset of 172 patients demonstrate that our proposed measures more effectively capture model errors at the lesion and patient scales compared to measures that average voxel-scale uncertainty values. We provide the UQ protocols code at https://github.com/Medical-Image-Analysis-Laboratory/MS_WML_uncs.
Assessing Distractors in Multiple-Choice Tests
Nov 08, 2023



Multiple-choice tests are a common approach for assessing candidates' comprehension skills. Standard multiple-choice reading comprehension exams require candidates to select the correct answer option from a discrete set based on a question in relation to a contextual passage. For appropriate assessment, the distractor answer options must by definition be incorrect but plausible and diverse. However, generating good quality distractors satisfying these criteria is a challenging task for content creators. We propose automated assessment metrics for the quality of distractors in multiple-choice reading comprehension tests. Specifically, we define quality in terms of the incorrectness, plausibility and diversity of the distractor options. We assess incorrectness using the classification ability of a binary multiple-choice reading comprehension system. Plausibility is assessed by considering the distractor confidence - the probability mass associated with the distractor options for a standard multi-class multiple-choice reading comprehension system. Diversity is assessed by pairwise comparison of an embedding-based equivalence metric between the distractors of a question. To further validate the plausibility metric we compare against candidate distributions over multiple-choice questions and agreement with a ChatGPT model's interpretation of distractor plausibility and diversity.
Is it Possible to Modify Text to a Target Readability Level? An Initial Investigation Using Zero-Shot Large Language Models
Sep 22, 2023
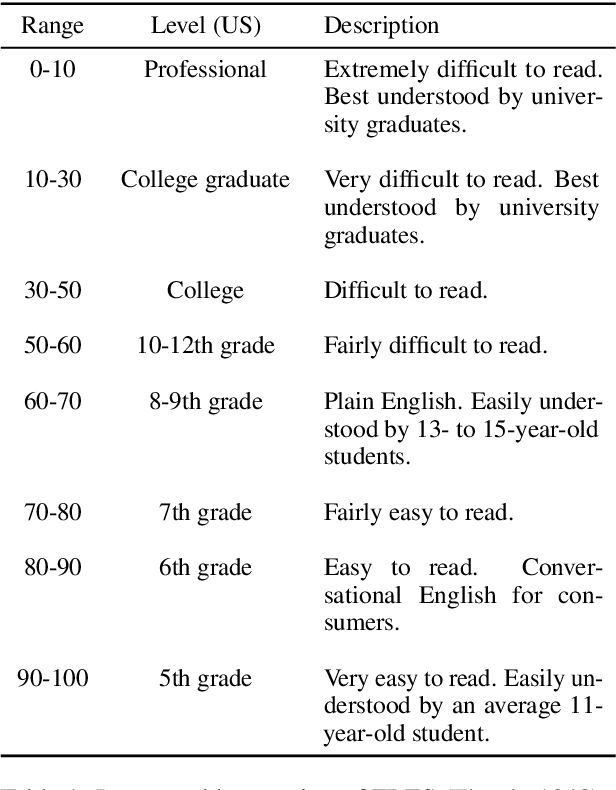
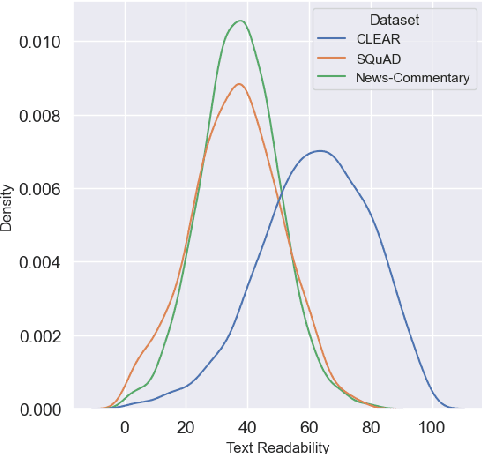
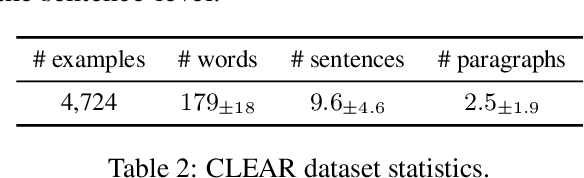
Text simplification is a common task where the text is adapted to make it easier to understand. Similarly, text elaboration can make a passage more sophisticated, offering a method to control the complexity of reading comprehension tests. However, text simplification and elaboration tasks are limited to only relatively alter the readability of texts. It is useful to directly modify the readability of any text to an absolute target readability level to cater to a diverse audience. Ideally, the readability of readability-controlled generated text should be independent of the source text. Therefore, we propose a novel readability-controlled text modification task. The task requires the generation of 8 versions at various target readability levels for each input text. We introduce novel readability-controlled text modification metrics. The baselines for this task use ChatGPT and Llama-2, with an extension approach introducing a two-step process (generating paraphrases by passing through the language model twice). The zero-shot approaches are able to push the readability of the paraphrases in the desired direction but the final readability remains correlated with the original text's readability. We also find greater drops in semantic and lexical similarity between the source and target texts with greater shifts in the readability.
Analyzing Multiple-Choice Reading and Listening Comprehension Tests
Jul 03, 2023

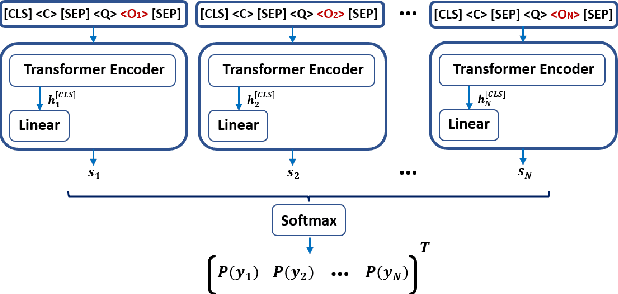
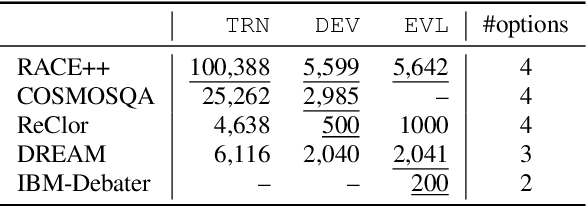
Multiple-choice reading and listening comprehension tests are an important part of language assessment. Content creators for standard educational tests need to carefully curate questions that assess the comprehension abilities of candidates taking the tests. However, recent work has shown that a large number of questions in general multiple-choice reading comprehension datasets can be answered without comprehension, by leveraging world knowledge instead. This work investigates how much of a contextual passage needs to be read in multiple-choice reading based on conversation transcriptions and listening comprehension tests to be able to work out the correct answer. We find that automated reading comprehension systems can perform significantly better than random with partial or even no access to the context passage. These findings offer an approach for content creators to automatically capture the trade-off between comprehension and world knowledge required for their proposed questions.
CamChoice: A Corpus of Multiple Choice Questions and Candidate Response Distributions
Jun 22, 2023

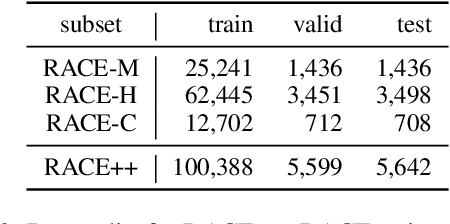

Multiple Choice examinations are a ubiquitous form of assessment that is used to measure the ability of candidates across various domains and tasks. Maintaining the quality of proposed questions is of great importance to test designers, and therefore newly proposed questions go through several pre-test evaluation stages before they can be deployed into real-world exams. This process is currently quite manual, which can lead to time lags in the question development cycle. Automating this process would lead to a large improvement in efficiency, however, current datasets do not contain sufficient pre-test analysis information. In this paper, we introduce CamChoice; a multiple-choice comprehension dataset with questions at different target levels, where questions have the true candidate selected options distributions. We introduce the task of candidate distribution matching, propose several evaluation metrics for the task, and demonstrate that automatic systems trained on RACE++ can be leveraged as baselines for our task. We further demonstrate that these automatic systems can be used for practical pre-test evaluation tasks such as detecting underperforming distractors, where our detection systems can automatically identify poor distractors that few candidates select. We release the data publicly for future research.