 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural-Based Uncertainty in Deep Learning Across Anatomical Scales: Analysis in White Matter Lesion Segmentation
Nov 15, 2023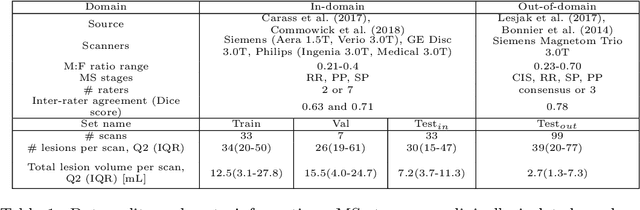


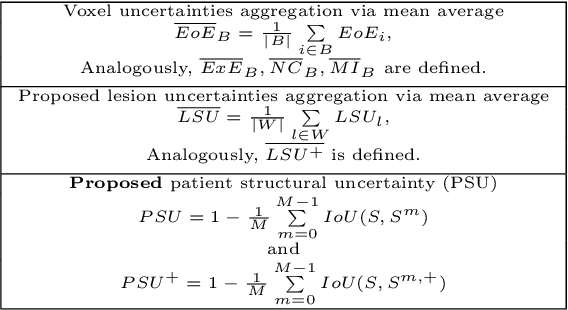
This paper explores uncertainty quantification (UQ) as an indicator of the trustworthiness of automated deep-learning (DL) tools in the context of white matter lesion (WML) segmentation from magnetic resonance imaging (MRI) scans of multiple sclerosis (MS) patients. Our study focuses on two principal aspects of uncertainty in structured output segmentation tasks. Firstly, we postulate that a good uncertainty measure should indicate predictions likely to be incorrect with high uncertainty values. Second, we investigate the merit of quantifying uncertainty at different anatomical scales (voxel, lesion, or patient). We hypothesize that uncertainty at each scale is related to specific types of errors. Our study aims to confirm this relationship by conducting separate analyses for in-domain and out-of-domain settings. Our primary methodological contributions are (i) the development of novel measures for quantifying uncertainty at lesion and patient scales, derived from structural prediction discrepancies, and (ii) the extension of an error retention curve analysis framework to facilitate the evaluation of UQ performance at both lesion and patient scales. The results from a multi-centric MRI dataset of 172 patients demonstrate that our proposed measures more effectively capture model errors at the lesion and patient scales compared to measures that average voxel-scale uncertainty values. We provide the UQ protocols code at https://github.com/Medical-Image-Analysis-Laboratory/MS_WML_uncs.
Evaluating Robustness and Uncertainty of Graph Models Under Structural Distributional Shifts
Feb 27, 2023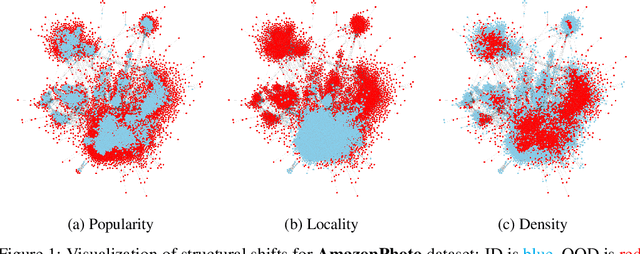
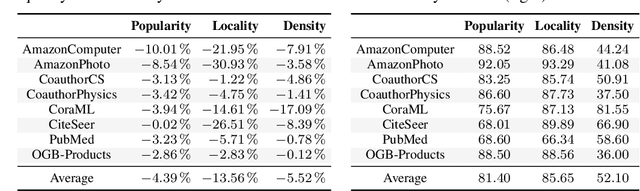

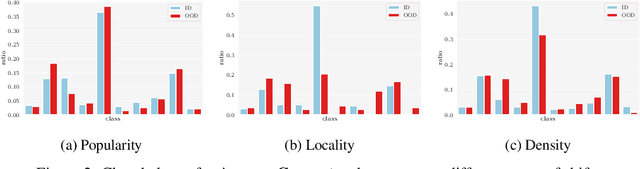
In reliable decision-making systems based on machine learning, models have to be robust to distributional shifts or provide the uncertainty of their predictions. In node-level problems of graph learning, distributional shifts can be especially complex since the samples are interdependent. To evaluate the performance of graph models, it is important to test them on diverse and meaningful distributional shifts. However, most graph benchmarks that consider distributional shifts for node-level problems focus mainly on node features, while data in graph problems is primarily defined by its structural properties. In this work, we propose a general approach for inducing diverse distributional shifts based on graph structure. We use this approach to create data splits according to several structural node properties: popularity, locality, and density. In our experiments, we thoroughly evaluate the proposed distributional shifts and show that they are quite challenging for existing graph models. We hope that the proposed approach will be helpful for the further development of reliable graph machine learning.
Tackling Bias in the Dice Similarity Coefficient: Introducing nDSC for White Matter Lesion Segmentation
Feb 10, 2023The development of automatic segmentation techniques for medical imaging tasks requires assessment metrics to fairly judge and rank such approaches on benchmarks. The Dice Similarity Coefficient (DSC) is a popular choice for comparing the agreement between the predicted segmentation against a ground-truth mask. However, the DSC metric has been shown to be biased to the occurrence rate of the positive class in the ground-truth, and hence should be considered in combination with other metrics. This work describes a detailed analysis of the recently proposed normalised Dice Similarity Coefficient (nDSC) for binary segmentation tasks as an adaptation of DSC which scales the precision at a fixed recall rate to tackle this bias. White matter lesion segmentation on magnetic resonance images of multiple sclerosis patients is selected as a case study task to empirically assess the suitability of nDSC. We validate the normalised DSC using two different models across 59 subject scans with a wide range of lesion loads. It is found that the nDSC is less biased than DSC with lesion load on standard white matter lesion segmentation benchmarks measured using standard rank correlation coefficients. An implementation of nDSC is made available at: https://github.com/NataliiaMolch/nDSC .
Novel structural-scale uncertainty measures and error retention curves: application to multiple sclerosis
Nov 11, 2022This paper focuses on the uncertainty estimation for white matter lesions (WML) segmentation in magnetic resonance imaging (MRI). On one side, voxel-scale segmentation errors cause the erroneous delineation of the lesions; on the other side, lesion-scale detection errors lead to wrong lesion counts. Both of these factors are clinically relevant for the assessment of multiple sclerosis patients. This work aims to compare the ability of different voxel- and lesion-scale uncertainty measures to capture errors related to segmentation and lesion detection, respectively. Our main contributions are (i) proposing new measures of lesion-scale uncertainty that do not utilise voxel-scale uncertainties; (ii) extending an error retention curves analysis framework for evaluation of lesion-scale uncertainty measures. Our results obtained on the multi-center testing set of 58 patients demonstrate that the proposed lesion-scale measure achieves the best performance among the analysed measures. All code implementations are provided at https://github.com/NataliiaMolch/MS_WML_uncs
Shifts 2.0: Extending The Dataset of Real Distributional Shifts
Jun 30, 2022



Distributional shift, or the mismatch between training and deployment data, is a significant obstacle to the usage of machine learning in high-stakes industrial applications, such as autonomous driving and medicine. This creates a need to be able to assess how robustly ML models generalize as well as the quality of their uncertainty estimates. Standard ML baseline datasets do not allow these properties to be assessed, as the training, validation and test data are often identically distributed. Recently, a range of dedicated benchmarks have appeared, featuring both distributionally matched and shifted data. Among these benchmarks, the Shifts dataset stands out in terms of the diversity of tasks as well as the data modalities it features. While most of the benchmarks are heavily dominated by 2D image classification tasks, Shifts contains tabular weather forecasting, machine translation, and vehicle motion prediction tasks. This enables the robustness properties of models to be assessed on a diverse set of industrial-scale tasks and either universal or directly applicable task-specific conclusions to be reached. In this paper, we extend the Shifts Dataset with two datasets sourced from industrial, high-risk applications of high societal importance. Specifically, we consider the tasks of segmentation of white matter Multiple Sclerosis lesions in 3D magnetic resonance brain images and the estimation of power consumption in marine cargo vessels. Both tasks feature ubiquitous distributional shifts and a strict safety requirement due to the high cost of errors. These new datasets will allow researchers to further explore robust generalization and uncertainty estimation in new situations. In this work, we provide a description of the dataset and baseline results for both tasks.
Multi-Sentence Resampling: A Simple Approach to Alleviate Dataset Length Bias and Beam-Search Degradation
Sep 13, 2021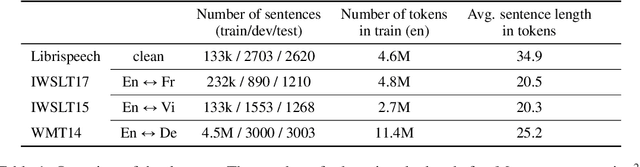
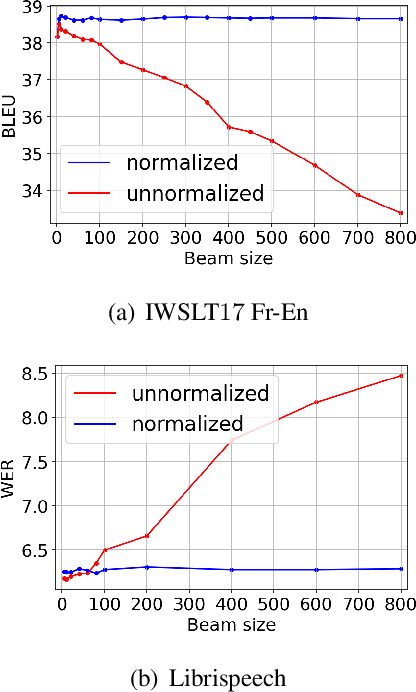

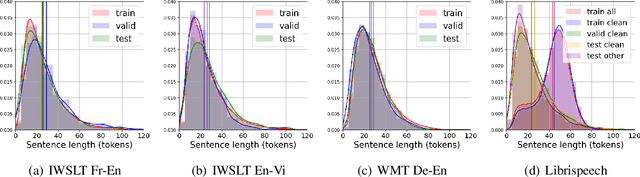
Neural Machine Translation (NMT) is known to suffer from a beam-search problem: after a certain point, increasing beam size causes an overall drop in translation quality. This effect is especially pronounced for long sentences. While much work was done analyzing this phenomenon, primarily for autoregressive NMT models, there is still no consensus on its underlying cause. In this work, we analyze errors that cause major quality degradation with large beams in NMT and Automatic Speech Recognition (ASR). We show that a factor that strongly contributes to the quality degradation with large beams is \textit{dataset length-bias} - \textit{NMT datasets are strongly biased towards short sentences}. To mitigate this issue, we propose a new data augmentation technique -- \textit{Multi-Sentence Resampling (MSR)}. This technique extends the training examples by concatenating several sentences from the original dataset to make a long training example. We demonstrate that MSR significantly reduces degradation with growing beam size and improves final translation quality on the IWSTL$15$ En-Vi, IWSTL$17$ En-Fr, and WMT$14$ En-De datasets.
Uncertainty Measures in Neural Belief Tracking and the Effects on Dialogue Policy Performance
Sep 09, 2021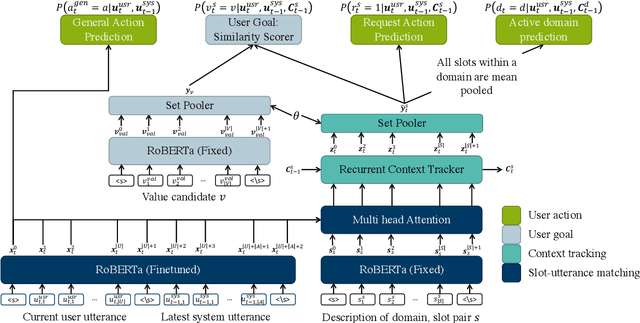
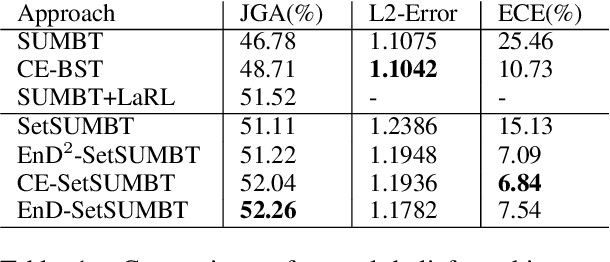
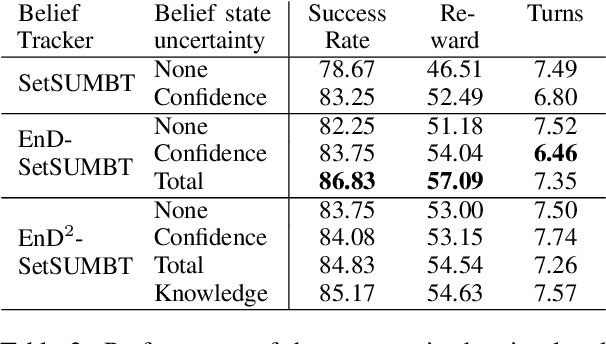
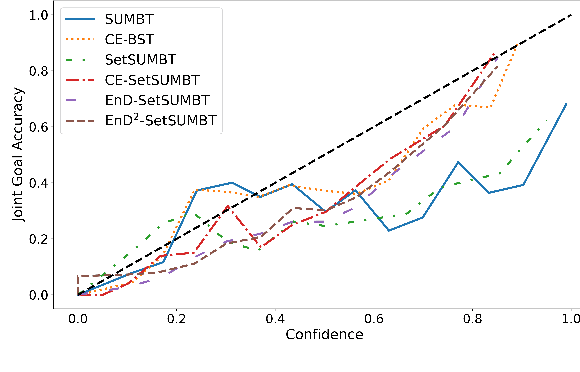
The ability to identify and resolve uncertainty is crucial for the robustness of a dialogue system. Indeed, this has been confirmed empirically on systems that utilise Bayesian approaches to dialogue belief tracking. However, such systems consider only confidence estimates and have difficulty scaling to more complex settings. Neural dialogue systems, on the other hand, rarely take uncertainties into account. They are therefore overconfident in their decisions and less robust. Moreover, the performance of the tracking task is often evaluated in isolation, without consideration of its effect on the downstream policy optimisation. We propose the use of different uncertainty measures in neural belief tracking. The effects of these measures on the downstream task of policy optimisation are evaluated by adding selected measures of uncertainty to the feature space of the policy and training policies through interaction with a user simulator. Both human and simulated user results show that incorporating these measures leads to improvements both of the performance and of the robustness of the downstream dialogue policy. This highlights the importance of developing neural dialogue belief trackers that take uncertainty into account.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021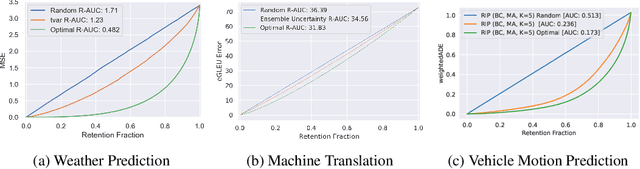
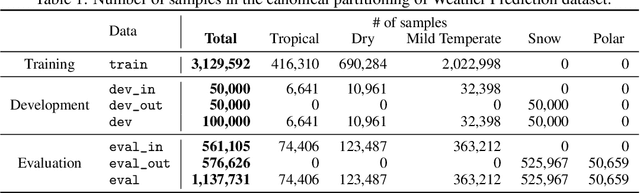
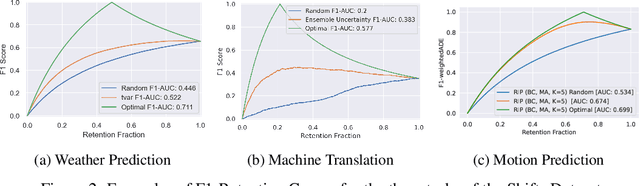
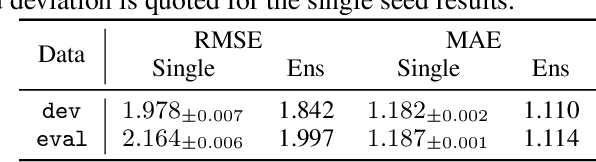
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
On the Periodic Behavior of Neural Network Training with Batch Normalization and Weight Decay
Jun 29, 2021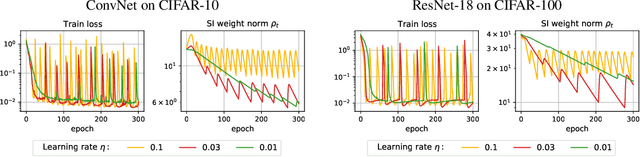

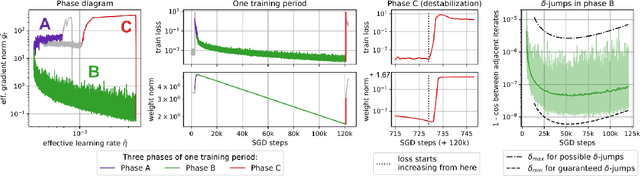
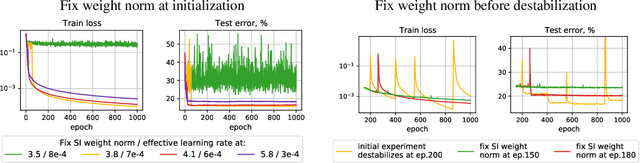
Despite the conventional wisdom that using batch normalization with weight decay may improve neural network training, some recent works show their joint usage may cause instabilities at the late stages of training. Other works, in contrast, show convergence to the equilibrium, i.e., the stabilization of training metrics. In this paper, we study this contradiction and show that instead of converging to a stable equilibrium, the training dynamics converge to consistent periodic behavior. That is, the training process regularly exhibits instabilities which, however, do not lead to complete training failure, but cause a new period of training. We rigorously investigate the mechanism underlying this discovered periodic behavior both from an empirical and theoretical point of view and show that this periodic behavior is indeed caused by the interaction between batch normalization and weight decay.
Scaling Ensemble Distribution Distillation to Many Classes with Proxy Targets
May 14, 2021



Ensembles of machine learning models yield improved system performance as well as robust and interpretable uncertainty estimates; however, their inference costs may often be prohibitively high. \emph{Ensemble Distribution Distillation} is an approach that allows a single model to efficiently capture both the predictive performance and uncertainty estimates of an ensemble. For classification, this is achieved by training a Dirichlet distribution over the ensemble members' output distributions via the maximum likelihood criterion. Although theoretically principled, this criterion exhibits poor convergence when applied to large-scale tasks where the number of classes is very high. In our work, we analyze this effect and show that the Dirichlet log-likelihood criterion classes with low probability induce larger gradients than high-probability classes. This forces the model to focus on the distribution of the ensemble tail-class probabilities. We propose a new training objective that minimizes the reverse KL-divergence to a \emph{Proxy-Dirichlet} target derived from the ensemble. This loss resolves the gradient issues of Ensemble Distribution Distillation, as we demonstrate both theoretically and empirically on the ImageNet and WMT17 En-De datasets containing 1000 and 40,000 classes, respectively.