 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Robustness and Uncertainty of Graph Models Under Structural Distributional Shifts
Paper and Code
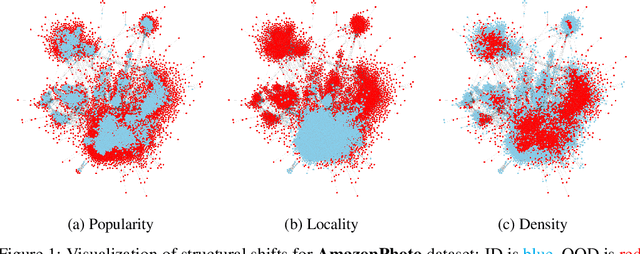
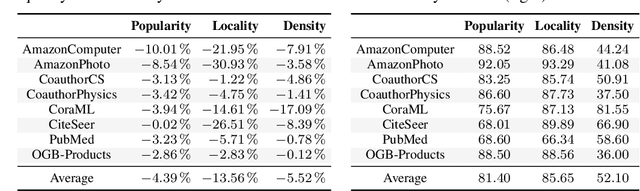

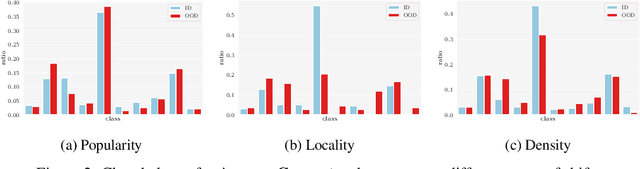
In reliable decision-making systems based on machine learning, models have to be robust to distributional shifts or provide the uncertainty of their predictions. In node-level problems of graph learning, distributional shifts can be especially complex since the samples are interdependent. To evaluate the performance of graph models, it is important to test them on diverse and meaningful distributional shifts. However, most graph benchmarks that consider distributional shifts for node-level problems focus mainly on node features, while data in graph problems is primarily defined by its structural properties. In this work, we propose a general approach for inducing diverse distributional shifts based on graph structure. We use this approach to create data splits according to several structural node properties: popularity, locality, and density. In our experiments, we thoroughly evaluate the proposed distributional shifts and show that they are quite challenging for existing graph models. We hope that the proposed approach will be helpful for the further development of reliable graph machine learning.