 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Urban Traffic Forecasting on Metropolis-Scale Road Networks
Oct 02, 2025Traffic forecasting on road networks is a complex task of significant practical importance that has recently attracted considerable attention from the machine learning community, with spatiotemporal graph neural networks (GNNs) becoming the most popular approach. The proper evaluation of traffic forecasting methods requires realistic datasets, but current publicly available benchmarks have significant drawbacks, including the absence of information about road connectivity for road graph construction, limited information about road properties, and a relatively small number of road segments that falls short of real-world applications. Further, current datasets mostly contain information about intercity highways with sparsely located sensors, while city road networks arguably present a more challenging forecasting task due to much denser roads and more complex urban traffic patterns. In this work, we provide a more complete, realistic, and challenging benchmark for traffic forecasting by releasing datasets representing the road networks of two major cities, with the largest containing almost 100,000 road segments (more than a 10-fold increase relative to existing datasets). Our datasets contain rich road features and provide fine-grained data about both traffic volume and traffic speed, allowing for building more holistic traffic forecasting systems. We show that most current implementations of neural spatiotemporal models for traffic forecasting have problems scaling to datasets of our size. To overcome this issue, we propose an alternative approach to neural traffic forecasting that uses a GNN without a dedicated module for temporal sequence processing, thus achieving much better scalability, while also demonstrating stronger forecasting performance. We hope our datasets and modeling insights will serve as a valuable resource for research in traffic forecasting.
Turning Tabular Foundation Models into Graph Foundation Models
Aug 28, 2025While foundation models have revolutionized such fields as natural language processing and computer vision, their application and potential within graph machine learning remain largely unexplored. One of the key challenges in designing graph foundation models (GFMs) is handling diverse node features that can vary across different graph datasets. Although many works on GFMs have been focused exclusively on text-attributed graphs, the problem of handling arbitrary features of other types in GFMs has not been fully addressed. However, this problem is not unique to the graph domain, as it also arises in the field of machine learning for tabular data. In this work, motivated by the recent success of tabular foundation models like TabPFNv2, we propose G2T-FM, a simple graph foundation model that employs TabPFNv2 as a backbone. Specifically, G2T-FM augments the original node features with neighborhood feature aggregation, adds structural embeddings, and then applies TabPFNv2 to the constructed node representations. Even in a fully in-context regime, our model achieves strong results, significantly outperforming publicly available GFMs and performing on par with well-tuned GNNs trained from scratch. Moreover, after finetuning, G2T-FM surpasses well-tuned GNN baselines, highlighting the potential of the proposed approach. More broadly, our paper reveals a previously overlooked direction of utilizing tabular foundation models for graph machine learning tasks.
TabGraphs: A Benchmark and Strong Baselines for Learning on Graphs with Tabular Node Features
Sep 26, 2024



Tabular machine learning is an important field for industry and science. In this field, table rows are usually treated as independent data samples, but additional information about relations between them is sometimes available and can be used to improve predictive performance. Such information can be naturally modeled with a graph, thus tabular machine learning may benefit from graph machine learning methods. However, graph machine learning models are typically evaluated on datasets with homogeneous node features, which have little in common with heterogeneous mixtures of numerical and categorical features present in tabular datasets. Thus, there is a critical difference between the data used in tabular and graph machine learning studies, which does not allow one to understand how successfully graph models can be transferred to tabular data. To bridge this gap, we propose a new benchmark of diverse graphs with heterogeneous tabular node features and realistic prediction tasks. We use this benchmark to evaluate a vast set of models, including simple methods previously overlooked in the literature. Our experiments show that graph neural networks (GNNs) can indeed often bring gains in predictive performance for tabular data, but standard tabular models also can be adapted to work with graph data by using simple feature preprocessing, which sometimes enables them to compete with and even outperform GNNs. Based on our empirical study, we provide insights for researchers and practitioners in both tabular and graph machine learning fields.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023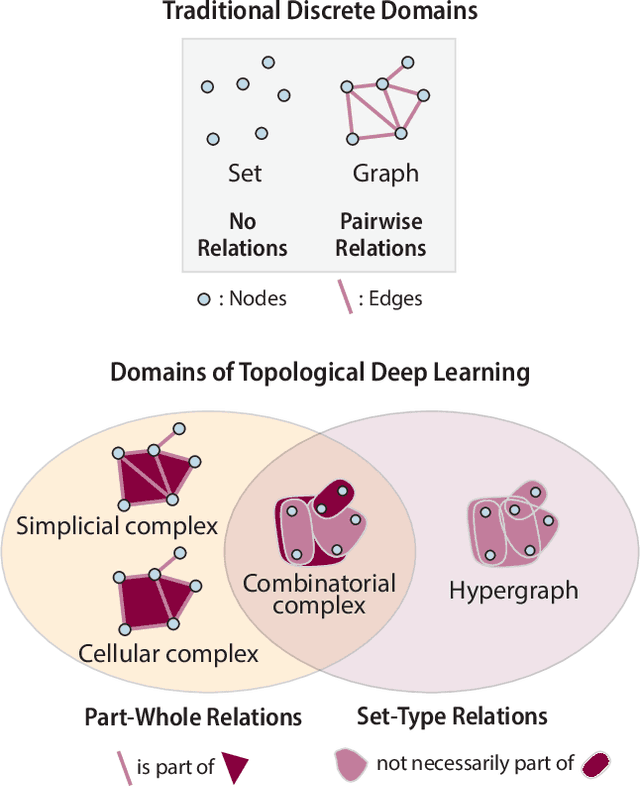
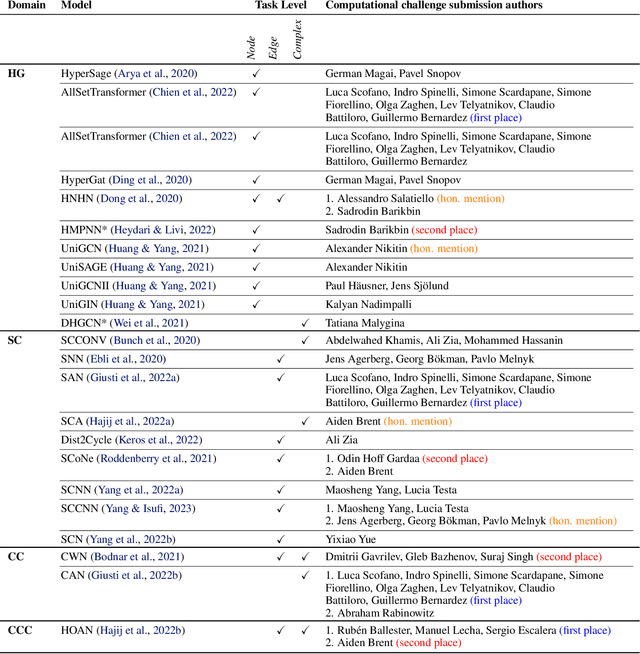
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Evaluating Robustness and Uncertainty of Graph Models Under Structural Distributional Shifts
Feb 27, 2023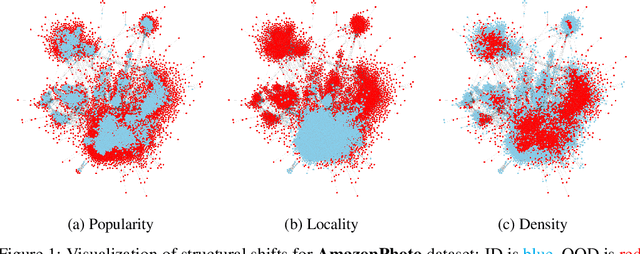
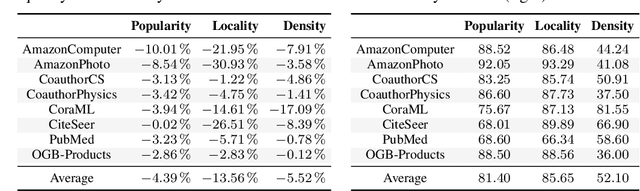

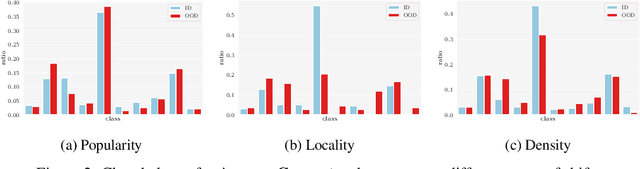
In reliable decision-making systems based on machine learning, models have to be robust to distributional shifts or provide the uncertainty of their predictions. In node-level problems of graph learning, distributional shifts can be especially complex since the samples are interdependent. To evaluate the performance of graph models, it is important to test them on diverse and meaningful distributional shifts. However, most graph benchmarks that consider distributional shifts for node-level problems focus mainly on node features, while data in graph problems is primarily defined by its structural properties. In this work, we propose a general approach for inducing diverse distributional shifts based on graph structure. We use this approach to create data splits according to several structural node properties: popularity, locality, and density. In our experiments, we thoroughly evaluate the proposed distributional shifts and show that they are quite challenging for existing graph models. We hope that the proposed approach will be helpful for the further development of reliable graph machine learning.
Towards OOD Detection in Graph Classification from Uncertainty Estimation Perspective
Jun 21, 2022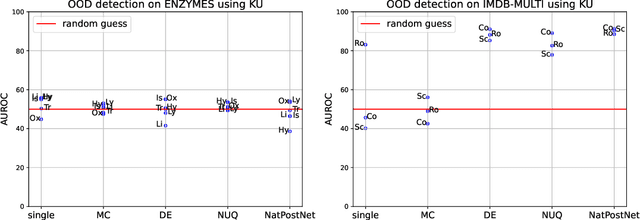
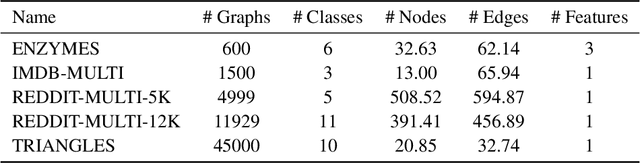
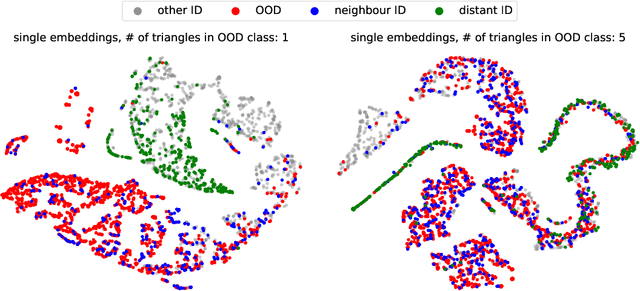

The problem of out-of-distribution detection for graph classification is far from being solved. The existing models tend to be overconfident about OOD examples or completely ignore the detection task. In this work, we consider this problem from the uncertainty estimation perspective and perform the comparison of several recently proposed methods. In our experiment, we find that there is no universal approach for OOD detection, and it is important to consider both graph representations and predictive categorical distribution.