 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Message-passing and spectral GNNs are two sides of the same coin
Feb 10, 2026Graph neural networks (GNNs) are commonly divided into message-passing neural networks (MPNNs) and spectral graph neural networks, reflecting two largely separate research traditions in machine learning and signal processing. This paper argues that this divide is mostly artificial, hindering progress in the field. We propose a viewpoint in which both MPNNs and spectral GNNs are understood as different parametrizations of permutation-equivariant operators acting on graph signals. From this perspective, many popular architectures are equivalent in expressive power, while genuine gaps arise only in specific regimes. We further argue that MPNNs and spectral GNNs offer complementary strengths. That is, MPNNs provide a natural language for discrete structure and expressivity analysis using tools from logic and graph isomorphism research, while the spectral perspective provides principled tools for understanding smoothing, bottlenecks, stability, and community structure. Overall, we posit that progress in graph learning will be accelerated by clearly understanding the key similarities and differences between these two types of GNNs, and by working towards unifying these perspectives within a common theoretical and conceptual framework rather than treating them as competing paradigms.
Global Ground Metric Learning with Applications to scRNA data
Jun 18, 2025Optimal transport provides a robust framework for comparing probability distributions. Its effectiveness is significantly influenced by the choice of the underlying ground metric. Traditionally, the ground metric has either been (i) predefined, e.g., as the Euclidean distance, or (ii) learned in a supervised way, by utilizing labeled data to learn a suitable ground metric for enhanced task-specific performance. Yet, predefined metrics typically cannot account for the inherent structure and varying importance of different features in the data, and existing supervised approaches to ground metric learning often do not generalize across multiple classes or are restricted to distributions with shared supports. To address these limitations, we propose a novel approach for learning metrics for arbitrary distributions over a shared metric space. Our method provides a distance between individual points like a global metric, but requires only class labels on a distribution-level for training. The learned global ground metric enables more accurate optimal transport distances, leading to improved performance in embedding, clustering and classification tasks. We demonstrate the effectiveness and interpretability of our approach using patient-level scRNA-seq data spanning multiple diseases.
* This method is provided as a Python package on PyPI, see https://github.com/DaminK/ggml-ot
Don't be Afraid of Cell Complexes! An Introduction from an Applied Perspective
Jun 11, 2025Cell complexes (CCs) are a higher-order network model deeply rooted in algebraic topology that has gained interest in signal processing and network science recently. However, while the processing of signals supported on CCs can be described in terms of easily-accessible algebraic or combinatorial notions, the commonly presented definition of CCs is grounded in abstract concepts from topology and remains disconnected from the signal processing methods developed for CCs. In this paper, we aim to bridge this gap by providing a simplified definition of CCs that is accessible to a wider audience and can be used in practical applications. Specifically, we first introduce a simplified notion of abstract regular cell complexes (ARCCs). These ARCCs only rely on notions from algebra and can be shown to be equivalent to regular cell complexes for most practical applications. Second, using this new definition we provide an accessible introduction to (abstract) cell complexes from a perspective of network science and signal processing. Furthermore, as many practical applications work with CCs of dimension 2 and below, we provide an even simpler definition for this case that significantly simplifies understanding and working with CCs in practice.
HLSAD: Hodge Laplacian-based Simplicial Anomaly Detection
May 30, 2025In this paper, we propose HLSAD, a novel method for detecting anomalies in time-evolving simplicial complexes. While traditional graph anomaly detection techniques have been extensively studied, they often fail to capture changes in higher-order interactions that are crucial for identifying complex structural anomalies. These higher-order interactions can arise either directly from the underlying data itself or through graph lifting techniques. Our approach leverages the spectral properties of Hodge Laplacians of simplicial complexes to effectively model multi-way interactions among data points. By incorporating higher-dimensional simplicial structures into our method, our method enhances both detection accuracy and computational efficiency. Through comprehensive experiments on both synthetic and real-world datasets, we demonstrate that our approach outperforms existing graph methods in detecting both events and change points.
A Bayesian Perspective on Uncertainty Quantification for Estimated Graph Signals
Feb 18, 2025We present a Bayesian perspective on quantifying the uncertainty of graph signals estimated or reconstructed from imperfect observations. We show that many conventional methods of graph signal estimation, reconstruction and imputation, can be reinterpreted as finding the mean of a posterior Gaussian distribution, with a covariance matrix shaped by the graph structure. In this perspective, assumptions of signal smoothness as well as bandlimitedness are naturally expressible as the choice of certain prior distributions; noisy, noise-free or partial observations are expressible in terms of certain likelihood models. In addition to providing a point estimate, as most standard estimation strategies do, our probabilistic framework enables us to characterize the shape of the estimated signal distribution around the estimate in terms of the posterior covariance matrix.
Efficient Sparsification of Simplicial Complexes via Local Densities of States
Feb 11, 2025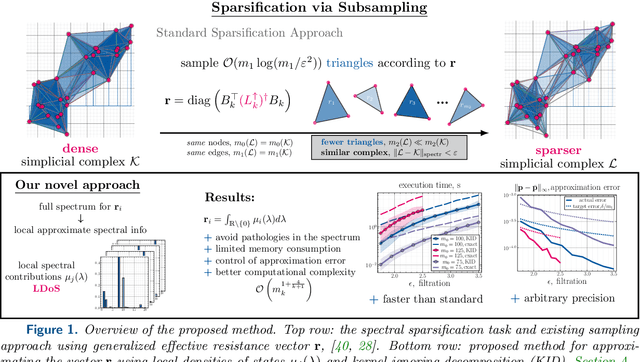



Simplicial complexes (SCs), a generalization of graph models for relational data that account for higher-order relations between data items, have become a popular abstraction for analyzing complex data using tools from topological data analysis or topological signal processing. However, the analysis of many real-world datasets leads to dense SCs with a large number of higher-order interactions. Unfortunately, analyzing such large SCs often has a prohibitive cost in terms of computation time and memory consumption. The sparsification of such complexes, i.e., the approximation of an original SC with a sparser simplicial complex with only a log-linear number of high-order simplices while maintaining a spectrum close to the original SC, is of broad interest. In this work, we develop a novel method for a probabilistic sparsifaction of SCs. At its core lies the efficient computation of sparsifying sampling probability through local densities of states as functional descriptors of the spectral information. To avoid pathological structures in the spectrum of the corresponding Hodge Laplacian operators, we suggest a "kernel-ignoring" decomposition for approximating the sampling probability; additionally, we exploit error estimates to show asymptotically prevailing algorithmic complexity of the developed method. The performance of the framework is demonstrated on the family of Vietoris--Rips filtered simplicial complexes.
Convergence of gradient based training for linear Graph Neural Networks
Jan 24, 2025Graph Neural Networks (GNNs) are powerful tools for addressing learning problems on graph structures, with a wide range of applications in molecular biology and social networks. However, the theoretical foundations underlying their empirical performance are not well understood. In this article, we examine the convergence of gradient dynamics in the training of linear GNNs. Specifically, we prove that the gradient flow training of a linear GNN with mean squared loss converges to the global minimum at an exponential rate. The convergence rate depends explicitly on the initial weights and the graph shift operator, which we validate on synthetic datasets from well-known graph models and real-world datasets. Furthermore, we discuss the gradient flow that minimizes the total weights at the global minimum. In addition to the gradient flow, we study the convergence of linear GNNs under gradient descent training, an iterative scheme viewed as a discretization of gradient flow.
Improving the Noise Estimation of Latent Neural Stochastic Differential Equations
Dec 23, 2024
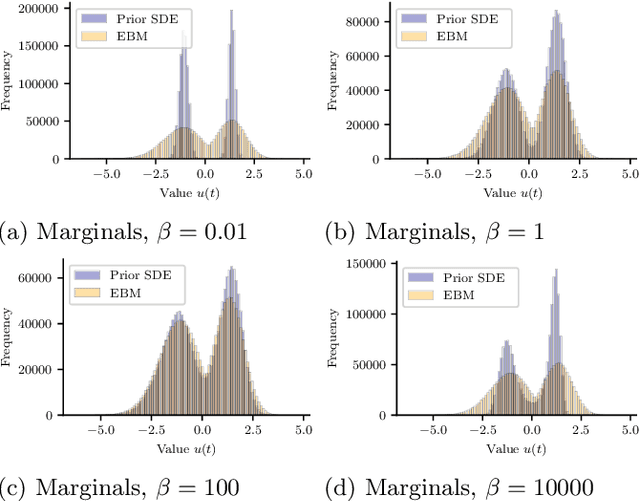


Latent neural stochastic differential equations (SDEs) have recently emerged as a promising approach for learning generative models from stochastic time series data. However, they systematically underestimate the noise level inherent in such data, limiting their ability to capture stochastic dynamics accurately. We investigate this underestimation in detail and propose a straightforward solution: by including an explicit additional noise regularization in the loss function, we are able to learn a model that accurately captures the diffusion component of the data. We demonstrate our results on a conceptual model system that highlights the improved latent neural SDE's capability to model stochastic bistable dynamics.
Topological Trajectory Classification and Landmark Inference on Simplicial Complexes
Dec 04, 2024We consider the problem of classifying trajectories on a discrete or discretised 2-dimensional manifold modelled by a simplicial complex. Previous works have proposed to project the trajectories into the harmonic eigenspace of the Hodge Laplacian, and then cluster the resulting embeddings. However, if the considered space has vanishing homology (i.e., no "holes"), then the harmonic space of the 1-Hodge Laplacian is trivial and thus the approach fails. Here we propose to view this issue akin to a sensor placement problem and present an algorithm that aims to learn "optimal holes" to distinguish a set of given trajectory classes. Specifically, given a set of labelled trajectories, which we interpret as edge-flows on the underlying simplicial complex, we search for 2-simplices whose deletion results in an optimal separation of the trajectory labels according to the corresponding spectral embedding of the trajectories into the harmonic space. Finally, we generalise this approach to the unsupervised setting.
Graph Neural Networks Do Not Always Oversmooth
Jun 04, 2024Graph neural networks (GNNs) have emerged as powerful tools for processing relational data in applications. However, GNNs suffer from the problem of oversmoothing, the property that the features of all nodes exponentially converge to the same vector over layers, prohibiting the design of deep GNNs. In this work we study oversmoothing in graph convolutional networks (GCNs) by using their Gaussian process (GP) equivalence in the limit of infinitely many hidden features. By generalizing methods from conventional deep neural networks (DNNs), we can describe the distribution of features at the output layer of deep GCNs in terms of a GP: as expected, we find that typical parameter choices from the literature lead to oversmoothing. The theory, however, allows us to identify a new, nonoversmoothing phase: if the initial weights of the network have sufficiently large variance, GCNs do not oversmooth, and node features remain informative even at large depth. We demonstrate the validity of this prediction in finite-size GCNs by training a linear classifier on their output. Moreover, using the linearization of the GCN GP, we generalize the concept of propagation depth of information from DNNs to GCNs. This propagation depth diverges at the transition between the oversmoothing and non-oversmoothing phase. We test the predictions of our approach and find good agreement with finite-size GCNs. Initializing GCNs near the transition to the non-oversmoothing phase, we obtain networks which are both deep and expressive.