 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation properties of neural ODEs
Mar 19, 2025We study the approximation properties of shallow neural networks whose activation function is defined as the flow of a neural ordinary differential equation (neural ODE) at the final time of the integration interval. We prove the universal approximation property (UAP) of such shallow neural networks in the space of continuous functions. Furthermore, we investigate the approximation properties of shallow neural networks whose parameters are required to satisfy some constraints. In particular, we constrain the Lipschitz constant of the flow of the neural ODE to increase the stability of the shallow neural network, and we restrict the norm of the weight matrices of the linear layers to one to make sure that the restricted expansivity of the flow is not compensated by the increased expansivity of the linear layers. For this setting, we prove approximation bounds that tell us the accuracy to which we can approximate a continuous function with a shallow neural network with such constraints. We prove that the UAP holds if we consider only the constraint on the Lipschitz constant of the flow or the unit norm constraint on the weight matrices of the linear layers.
Efficient Sparsification of Simplicial Complexes via Local Densities of States
Feb 11, 2025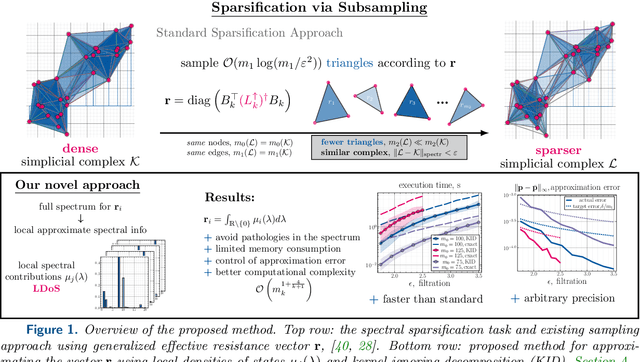



Simplicial complexes (SCs), a generalization of graph models for relational data that account for higher-order relations between data items, have become a popular abstraction for analyzing complex data using tools from topological data analysis or topological signal processing. However, the analysis of many real-world datasets leads to dense SCs with a large number of higher-order interactions. Unfortunately, analyzing such large SCs often has a prohibitive cost in terms of computation time and memory consumption. The sparsification of such complexes, i.e., the approximation of an original SC with a sparser simplicial complex with only a log-linear number of high-order simplices while maintaining a spectrum close to the original SC, is of broad interest. In this work, we develop a novel method for a probabilistic sparsifaction of SCs. At its core lies the efficient computation of sparsifying sampling probability through local densities of states as functional descriptors of the spectral information. To avoid pathological structures in the spectrum of the corresponding Hodge Laplacian operators, we suggest a "kernel-ignoring" decomposition for approximating the sampling probability; additionally, we exploit error estimates to show asymptotically prevailing algorithmic complexity of the developed method. The performance of the framework is demonstrated on the family of Vietoris--Rips filtered simplicial complexes.
Neural Rank Collapse: Weight Decay and Small Within-Class Variability Yield Low-Rank Bias
Feb 06, 2024Recent work in deep learning has shown strong empirical and theoretical evidence of an implicit low-rank bias: weight matrices in deep networks tend to be approximately low-rank and removing relatively small singular values during training or from available trained models may significantly reduce model size while maintaining or even improving model performance. However, the majority of the theoretical investigations around low-rank bias in neural networks deal with oversimplified deep linear networks. In this work, we consider general networks with nonlinear activations and the weight decay parameter, and we show the presence of an intriguing neural rank collapse phenomenon, connecting the low-rank bias of trained networks with networks' neural collapse properties: as the weight decay parameter grows, the rank of each layer in the network decreases proportionally to the within-class variability of the hidden-space embeddings of the previous layers. Our theoretical findings are supported by a range of experimental evaluations illustrating the phenomenon.