 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable neural networks and connections to continuous dynamical systems
Oct 25, 2025The existence of instabilities, for example in the form of adversarial examples, has given rise to a highly active area of research concerning itself with understanding and enhancing the stability of neural networks. We focus on a popular branch within this area which draws on connections to continuous dynamical systems and optimal control, giving a bird's eye view of this area. We identify and describe the fundamental concepts that underlie much of the existing work in this area. Following this, we go into more detail on a specific approach to designing stable neural networks, developing the theoretical background and giving a description of how these networks can be implemented. We provide code that implements the approach that can be adapted and extended by the reader. The code further includes a notebook with a fleshed-out toy example on adversarial robustness of image classification that can be run without heavy requirements on the reader's computer. We finish by discussing this toy example so that the reader can interactively follow along on their computer. This work will be included as a chapter of a book on scientific machine learning, which is currently under revision and aimed at students.
Approximation theory for 1-Lipschitz ResNets
May 17, 20251-Lipschitz neural networks are fundamental for generative modelling, inverse problems, and robust classifiers. In this paper, we focus on 1-Lipschitz residual networks (ResNets) based on explicit Euler steps of negative gradient flows and study their approximation capabilities. Leveraging the Restricted Stone-Weierstrass Theorem, we first show that these 1-Lipschitz ResNets are dense in the set of scalar 1-Lipschitz functions on any compact domain when width and depth are allowed to grow. We also show that these networks can exactly represent scalar piecewise affine 1-Lipschitz functions. We then prove a stronger statement: by inserting norm-constrained linear maps between the residual blocks, the same density holds when the hidden width is fixed. Because every layer obeys simple norm constraints, the resulting models can be trained with off-the-shelf optimisers. This paper provides the first universal approximation guarantees for 1-Lipschitz ResNets, laying a rigorous foundation for their practical use.
Approximation properties of neural ODEs
Mar 19, 2025We study the approximation properties of shallow neural networks whose activation function is defined as the flow of a neural ordinary differential equation (neural ODE) at the final time of the integration interval. We prove the universal approximation property (UAP) of such shallow neural networks in the space of continuous functions. Furthermore, we investigate the approximation properties of shallow neural networks whose parameters are required to satisfy some constraints. In particular, we constrain the Lipschitz constant of the flow of the neural ODE to increase the stability of the shallow neural network, and we restrict the norm of the weight matrices of the linear layers to one to make sure that the restricted expansivity of the flow is not compensated by the increased expansivity of the linear layers. For this setting, we prove approximation bounds that tell us the accuracy to which we can approximate a continuous function with a shallow neural network with such constraints. We prove that the UAP holds if we consider only the constraint on the Lipschitz constant of the flow or the unit norm constraint on the weight matrices of the linear layers.
Symplectic Neural Flows for Modeling and Discovery
Dec 21, 2024Hamilton's equations are fundamental for modeling complex physical systems, where preserving key properties such as energy and momentum is crucial for reliable long-term simulations. Geometric integrators are widely used for this purpose, but neural network-based methods that incorporate these principles remain underexplored. This work introduces SympFlow, a time-dependent symplectic neural network designed using parameterized Hamiltonian flow maps. This design allows for backward error analysis and ensures the preservation of the symplectic structure. SympFlow allows for two key applications: (i) providing a time-continuous symplectic approximation of the exact flow of a Hamiltonian system--purely based on the differential equations it satisfies, and (ii) approximating the flow map of an unknown Hamiltonian system relying on trajectory data. We demonstrate the effectiveness of SympFlow on diverse problems, including chaotic and dissipative systems, showing improved energy conservation compared to general-purpose numerical methods and accurate
Hamiltonian Matching for Symplectic Neural Integrators
Oct 23, 2024



Hamilton's equations of motion form a fundamental framework in various branches of physics, including astronomy, quantum mechanics, particle physics, and climate science. Classical numerical solvers are typically employed to compute the time evolution of these systems. However, when the system spans multiple spatial and temporal scales numerical errors can accumulate, leading to reduced accuracy. To address the challenges of evolving such systems over long timescales, we propose SympFlow, a novel neural network-based symplectic integrator, which is the composition of a sequence of exact flow maps of parametrised time-dependent Hamiltonian functions. This architecture allows for a backward error analysis: we can identify an underlying Hamiltonian function of the architecture and use it to define a Hamiltonian matching objective function, which we use for training. In numerical experiments, we show that SympFlow exhibits promising results, with qualitative energy conservation behaviour similar to that of time-stepping symplectic integrators.
Parallel-in-Time Solutions with Random Projection Neural Networks
Aug 19, 2024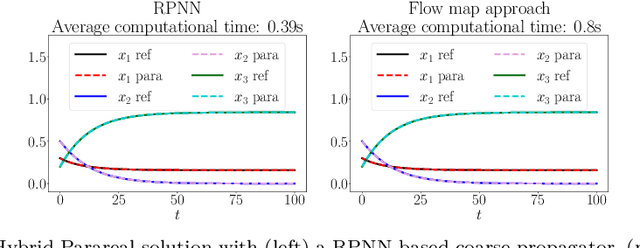


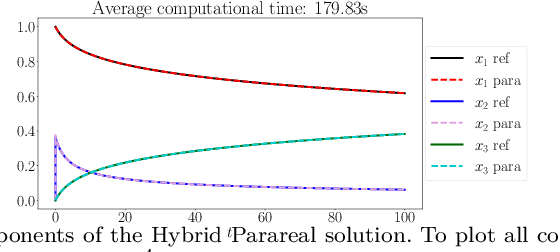
This paper considers one of the fundamental parallel-in-time methods for the solution of ordinary differential equations, Parareal, and extends it by adopting a neural network as a coarse propagator. We provide a theoretical analysis of the convergence properties of the proposed algorithm and show its effectiveness for several examples, including Lorenz and Burgers' equations. In our numerical simulations, we further specialize the underpinning neural architecture to Random Projection Neural Networks (RPNNs), a 2-layer neural network where the first layer weights are drawn at random rather than optimized. This restriction substantially increases the efficiency of fitting RPNN's weights in comparison to a standard feedforward network without negatively impacting the accuracy, as demonstrated in the SIR system example.
Contractive Systems Improve Graph Neural Networks Against Adversarial Attacks
Nov 12, 2023Graph Neural Networks (GNNs) have established themselves as a key component in addressing diverse graph-based tasks. Despite their notable successes, GNNs remain susceptible to input perturbations in the form of adversarial attacks. This paper introduces an innovative approach to fortify GNNs against adversarial perturbations through the lens of contractive dynamical systems. Our method introduces graph neural layers based on differential equations with contractive properties, which, as we show, improve the robustness of GNNs. A distinctive feature of the proposed approach is the simultaneous learned evolution of both the node features and the adjacency matrix, yielding an intrinsic enhancement of model robustness to perturbations in the input features and the connectivity of the graph. We mathematically derive the underpinnings of our novel architecture and provide theoretical insights to reason about its expected behavior. We demonstrate the efficacy of our method through numerous real-world benchmarks, reading on par or improved performance compared to existing methods.
Designing Stable Neural Networks using Convex Analysis and ODEs
Jun 29, 2023Motivated by classical work on the numerical integration of ordinary differential equations we present a ResNet-styled neural network architecture that encodes non-expansive (1-Lipschitz) operators, as long as the spectral norms of the weights are appropriately constrained. This is to be contrasted with the ordinary ResNet architecture which, even if the spectral norms of the weights are constrained, has a Lipschitz constant that, in the worst case, grows exponentially with the depth of the network. Further analysis of the proposed architecture shows that the spectral norms of the weights can be further constrained to ensure that the network is an averaged operator, making it a natural candidate for a learned denoiser in Plug-and-Play algorithms. Using a novel adaptive way of enforcing the spectral norm constraints, we show that, even with these constraints, it is possible to train performant networks. The proposed architecture is applied to the problem of adversarially robust image classification, to image denoising, and finally to the inverse problem of deblurring.
Predictions Based on Pixel Data: Insights from PDEs and Finite Differences
May 01, 2023Neural networks are the state-of-the-art for many approximation tasks in high-dimensional spaces, as supported by an abundance of experimental evidence. However, we still need a solid theoretical understanding of what they can approximate and, more importantly, at what cost and accuracy. One network architecture of practical use, especially for approximation tasks involving images, is convolutional (residual) networks. However, due to the locality of the linear operators involved in these networks, their analysis is more complicated than for generic fully connected neural networks. This paper focuses on sequence approximation tasks, where a matrix or a higher-order tensor represents each observation. We show that when approximating sequences arising from space-time discretisations of PDEs we may use relatively small networks. We constructively derive these results by exploiting connections between discrete convolution and finite difference operators. Throughout, we design our network architecture to, while having guarantees, be similar to those typically adopted in practice for sequence approximation tasks. Our theoretical results are supported by numerical experiments which simulate linear advection, the heat equation, and the Fisher equation. The implementation used is available at the repository associated to the paper.
Dynamical systems' based neural networks
Oct 05, 2022
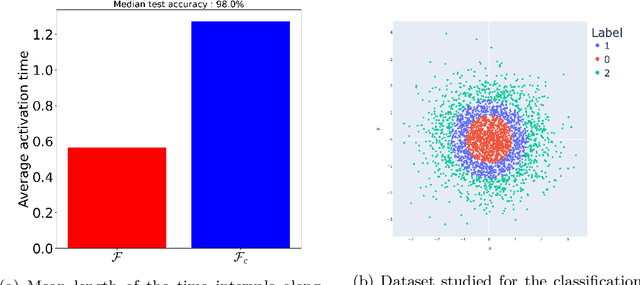
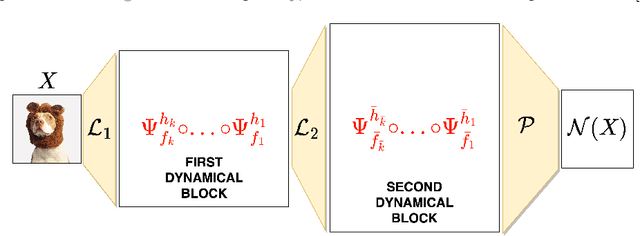
Neural networks have gained much interest because of their effectiveness in many applications. However, their mathematical properties are generally not well understood. If there is some underlying geometric structure inherent to the data or to the function to approximate, it is often desirable to take this into account in the design of the neural network. In this work, we start with a non-autonomous ODE and build neural networks using a suitable, structure-preserving, numerical time-discretisation. The structure of the neural network is then inferred from the properties of the ODE vector field. Besides injecting more structure into the network architectures, this modelling procedure allows a better theoretical understanding of their behaviour. We present two universal approximation results and demonstrate how to impose some particular properties on the neural networks. A particular focus is on 1-Lipschitz architectures including layers that are not 1-Lipschitz. These networks are expressive and robust against adversarial attacks, as shown for the CIFAR-10 dataset.