 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffeomorphism-Equivariant Neural Networks
Feb 06, 2026Incorporating group symmetries via equivariance into neural networks has emerged as a robust approach for overcoming the efficiency and data demands of modern deep learning. While most existing approaches, such as group convolutions and averaging-based methods, focus on compact, finite, or low-dimensional groups with linear actions, this work explores how equivariance can be extended to infinite-dimensional groups. We propose a strategy designed to induce diffeomorphism equivariance in pre-trained neural networks via energy-based canonicalisation. Formulating equivariance as an optimisation problem allows us to access the rich toolbox of already established differentiable image registration methods. Empirical results on segmentation and classification tasks confirm that our approach achieves approximate equivariance and generalises to unseen transformations without relying on extensive data augmentation or retraining.
When is a System Discoverable from Data? Discovery Requires Chaos
Nov 12, 2025The deep learning revolution has spurred a rise in advances of using AI in sciences. Within physical sciences the main focus has been on discovery of dynamical systems from observational data. Yet the reliability of learned surrogates and symbolic models is often undermined by the fundamental problem of non-uniqueness. The resulting models may fit the available data perfectly, but lack genuine predictive power. This raises the question: under what conditions can the systems governing equations be uniquely identified from a finite set of observations? We show, counter-intuitively, that chaos, typically associated with unpredictability, is crucial for ensuring a system is discoverable in the space of continuous or analytic functions. The prevalence of chaotic systems in benchmark datasets may have inadvertently obscured this fundamental limitation. More concretely, we show that systems chaotic on their entire domain are discoverable from a single trajectory within the space of continuous functions, and systems chaotic on a strange attractor are analytically discoverable under a geometric condition on the attractor. As a consequence, we demonstrate for the first time that the classical Lorenz system is analytically discoverable. Moreover, we establish that analytic discoverability is impossible in the presence of first integrals, common in real-world systems. These findings help explain the success of data-driven methods in inherently chaotic domains like weather forecasting, while revealing a significant challenge for engineering applications like digital twins, where stable, predictable behavior is desired. For these non-chaotic systems, we find that while trajectory data alone is insufficient, certain prior physical knowledge can help ensure discoverability. These findings warrant a critical re-evaluation of the fundamental assumptions underpinning purely data-driven discovery.
Learning Regularization Functionals for Inverse Problems: A Comparative Study
Oct 02, 2025In recent years, a variety of learned regularization frameworks for solving inverse problems in imaging have emerged. These offer flexible modeling together with mathematical insights. The proposed methods differ in their architectural design and training strategies, making direct comparison challenging due to non-modular implementations. We address this gap by collecting and unifying the available code into a common framework. This unified view allows us to systematically compare the approaches and highlight their strengths and limitations, providing valuable insights into their future potential. We also provide concise descriptions of each method, complemented by practical guidelines.
Data-driven approaches to inverse problems
Jun 13, 2025Inverse problems are concerned with the reconstruction of unknown physical quantities using indirect measurements and are fundamental across diverse fields such as medical imaging, remote sensing, and material sciences. These problems serve as critical tools for visualizing internal structures beyond what is visible to the naked eye, enabling quantification, diagnosis, prediction, and discovery. However, most inverse problems are ill-posed, necessitating robust mathematical treatment to yield meaningful solutions. While classical approaches provide mathematically rigorous and computationally stable solutions, they are constrained by the ability to accurately model solution properties and implement them efficiently. A more recent paradigm considers deriving solutions to inverse problems in a data-driven manner. Instead of relying on classical mathematical modeling, this approach utilizes highly over-parameterized models, typically deep neural networks, which are adapted to specific inverse problems using carefully selected training data. Current approaches that follow this new paradigm distinguish themselves through solution accuracy paired with computational efficiency that was previously inconceivable. These notes offer an introduction to this data-driven paradigm for inverse problems. The first part of these notes will provide an introduction to inverse problems, discuss classical solution strategies, and present some applications. The second part will delve into modern data-driven approaches, with a particular focus on adversarial regularization and provably convergent linear plug-and-play denoisers. Throughout the presentation of these methodologies, their theoretical properties will be discussed, and numerical examples will be provided. The lecture series will conclude with a discussion of open problems and future perspectives in the field.
Symplectic Neural Flows for Modeling and Discovery
Dec 21, 2024Hamilton's equations are fundamental for modeling complex physical systems, where preserving key properties such as energy and momentum is crucial for reliable long-term simulations. Geometric integrators are widely used for this purpose, but neural network-based methods that incorporate these principles remain underexplored. This work introduces SympFlow, a time-dependent symplectic neural network designed using parameterized Hamiltonian flow maps. This design allows for backward error analysis and ensures the preservation of the symplectic structure. SympFlow allows for two key applications: (i) providing a time-continuous symplectic approximation of the exact flow of a Hamiltonian system--purely based on the differential equations it satisfies, and (ii) approximating the flow map of an unknown Hamiltonian system relying on trajectory data. We demonstrate the effectiveness of SympFlow on diverse problems, including chaotic and dissipative systems, showing improved energy conservation compared to general-purpose numerical methods and accurate
Benchmarking learned algorithms for computed tomography image reconstruction tasks
Dec 11, 2024



Computed tomography (CT) is a widely used non-invasive diagnostic method in various fields, and recent advances in deep learning have led to significant progress in CT image reconstruction. However, the lack of large-scale, open-access datasets has hindered the comparison of different types of learned methods. To address this gap, we use the 2DeteCT dataset, a real-world experimental computed tomography dataset, for benchmarking machine learning based CT image reconstruction algorithms. We categorize these methods into post-processing networks, learned/unrolled iterative methods, learned regularizer methods, and plug-and-play methods, and provide a pipeline for easy implementation and evaluation. Using key performance metrics, including SSIM and PSNR, our benchmarking results showcase the effectiveness of various algorithms on tasks such as full data reconstruction, limited-angle reconstruction, sparse-angle reconstruction, low-dose reconstruction, and beam-hardening corrected reconstruction. With this benchmarking study, we provide an evaluation of a range of algorithms representative for different categories of learned reconstruction methods on a recently published dataset of real-world experimental CT measurements. The reproducible setup of methods and CT image reconstruction tasks in an open-source toolbox enables straightforward addition and comparison of new methods later on. The toolbox also provides the option to load the 2DeteCT dataset differently for extensions to other problems and different CT reconstruction tasks.
Hamiltonian Matching for Symplectic Neural Integrators
Oct 23, 2024



Hamilton's equations of motion form a fundamental framework in various branches of physics, including astronomy, quantum mechanics, particle physics, and climate science. Classical numerical solvers are typically employed to compute the time evolution of these systems. However, when the system spans multiple spatial and temporal scales numerical errors can accumulate, leading to reduced accuracy. To address the challenges of evolving such systems over long timescales, we propose SympFlow, a novel neural network-based symplectic integrator, which is the composition of a sequence of exact flow maps of parametrised time-dependent Hamiltonian functions. This architecture allows for a backward error analysis: we can identify an underlying Hamiltonian function of the architecture and use it to define a Hamiltonian matching objective function, which we use for training. In numerical experiments, we show that SympFlow exhibits promising results, with qualitative energy conservation behaviour similar to that of time-stepping symplectic integrators.
Lie Algebra Canonicalization: Equivariant Neural Operators under arbitrary Lie Groups
Oct 03, 2024



The quest for robust and generalizable machine learning models has driven recent interest in exploiting symmetries through equivariant neural networks. In the context of PDE solvers, recent works have shown that Lie point symmetries can be a useful inductive bias for Physics-Informed Neural Networks (PINNs) through data and loss augmentation. Despite this, directly enforcing equivariance within the model architecture for these problems remains elusive. This is because many PDEs admit non-compact symmetry groups, oftentimes not studied beyond their infinitesimal generators, making them incompatible with most existing equivariant architectures. In this work, we propose Lie aLgebrA Canonicalization (LieLAC), a novel approach that exploits only the action of infinitesimal generators of the symmetry group, circumventing the need for knowledge of the full group structure. To achieve this, we address existing theoretical issues in the canonicalization literature, establishing connections with frame averaging in the case of continuous non-compact groups. Operating within the framework of canonicalization, LieLAC can easily be integrated with unconstrained pre-trained models, transforming inputs to a canonical form before feeding them into the existing model, effectively aligning the input for model inference according to allowed symmetries. LieLAC utilizes standard Lie group descent schemes, achieving equivariance in pre-trained models. Finally, we showcase LieLAC's efficacy on tasks of invariant image classification and Lie point symmetry equivariant neural PDE solvers using pre-trained models.
Score-based pullback Riemannian geometry
Oct 02, 2024



Data-driven Riemannian geometry has emerged as a powerful tool for interpretable representation learning, offering improved efficiency in downstream tasks. Moving forward, it is crucial to balance cheap manifold mappings with efficient training algorithms. In this work, we integrate concepts from pullback Riemannian geometry and generative models to propose a framework for data-driven Riemannian geometry that is scalable in both geometry and learning: score-based pullback Riemannian geometry. Focusing on unimodal distributions as a first step, we propose a score-based Riemannian structure with closed-form geodesics that pass through the data probability density. With this structure, we construct a Riemannian autoencoder (RAE) with error bounds for discovering the correct data manifold dimension. This framework can naturally be used with anisotropic normalizing flows by adopting isometry regularization during training. Through numerical experiments on various datasets, we demonstrate that our framework not only produces high-quality geodesics through the data support, but also reliably estimates the intrinsic dimension of the data manifold and provides a global chart of the manifold, even in high-dimensional ambient spaces.
Weakly Convex Regularisers for Inverse Problems: Convergence of Critical Points and Primal-Dual Optimisation
Feb 01, 2024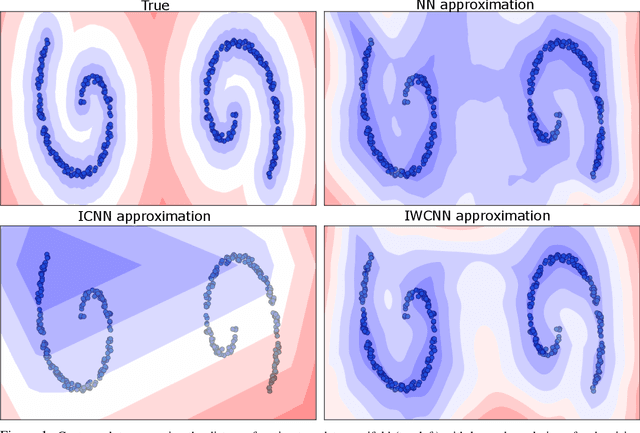
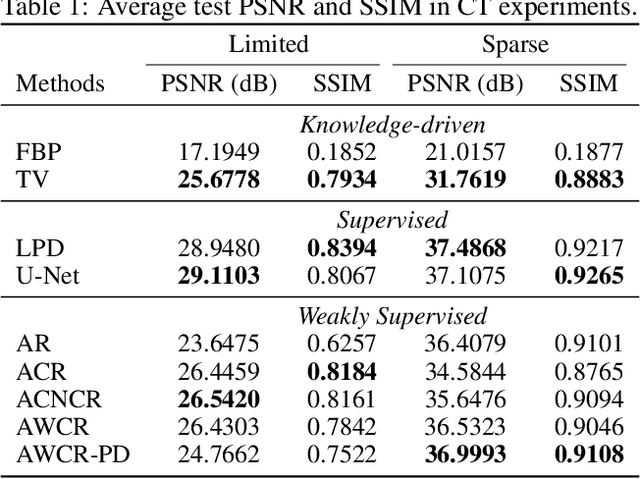
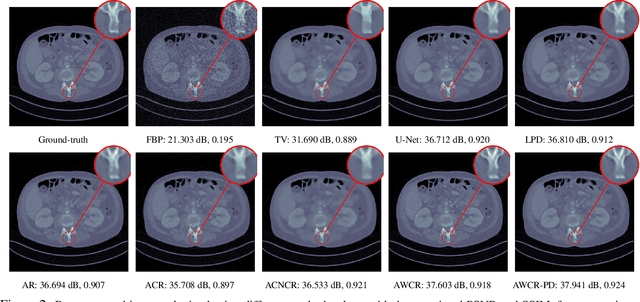
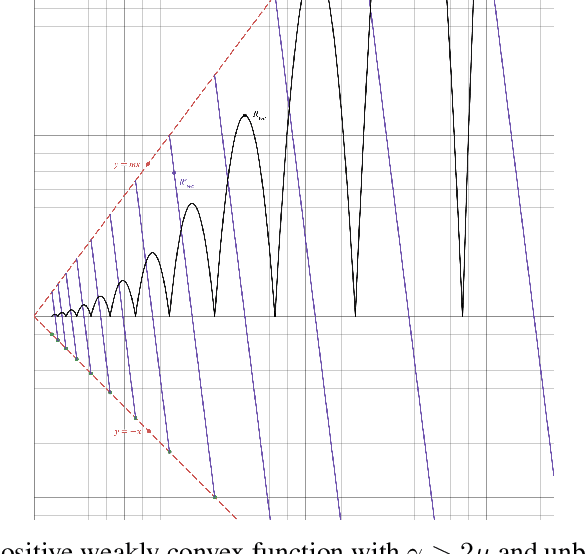
Variational regularisation is the primary method for solving inverse problems, and recently there has been considerable work leveraging deeply learned regularisation for enhanced performance. However, few results exist addressing the convergence of such regularisation, particularly within the context of critical points as opposed to global minima. In this paper, we present a generalised formulation of convergent regularisation in terms of critical points, and show that this is achieved by a class of weakly convex regularisers. We prove convergence of the primal-dual hybrid gradient method for the associated variational problem, and, given a Kurdyka-Lojasiewicz condition, an $\mathcal{O}(\log{k}/k)$ ergodic convergence rate. Finally, applying this theory to learned regularisation, we prove universal approximation for input weakly convex neural networks (IWCNN), and show empirically that IWCNNs can lead to improved performance of learned adversarial regularisers for computed tomography (CT) reconstruction.