 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStuart-Landau Oscillatory Graph Neural Network
Nov 11, 2025Oscillatory Graph Neural Networks (OGNNs) are an emerging class of physics-inspired architectures designed to mitigate oversmoothing and vanishing gradient problems in deep GNNs. In this work, we introduce the Complex-Valued Stuart-Landau Graph Neural Network (SLGNN), a novel architecture grounded in Stuart-Landau oscillator dynamics. Stuart-Landau oscillators are canonical models of limit-cycle behavior near Hopf bifurcations, which are fundamental to synchronization theory and are widely used in e.g. neuroscience for mesoscopic brain modeling. Unlike harmonic oscillators and phase-only Kuramoto models, Stuart-Landau oscillators retain both amplitude and phase dynamics, enabling rich phenomena such as amplitude regulation and multistable synchronization. The proposed SLGNN generalizes existing phase-centric Kuramoto-based OGNNs by allowing node feature amplitudes to evolve dynamically according to Stuart-Landau dynamics, with explicit tunable hyperparameters (such as the Hopf-parameter and the coupling strength) providing additional control over the interplay between feature amplitudes and network structure. We conduct extensive experiments across node classification, graph classification, and graph regression tasks, demonstrating that SLGNN outperforms existing OGNNs and establishes a novel, expressive, and theoretically grounded framework for deep oscillatory architectures on graphs.
Rethinking Oversmoothing in Graph Neural Networks: A Rank-Based Perspective
Feb 07, 2025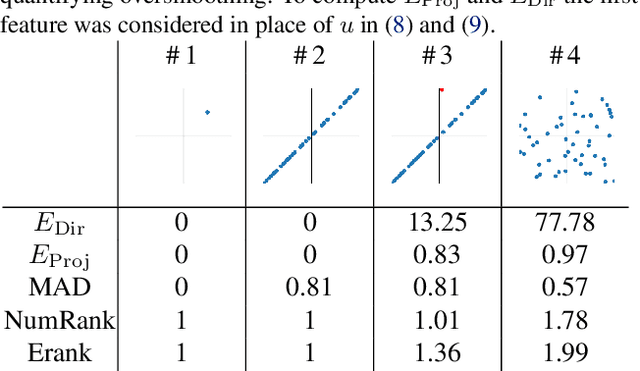
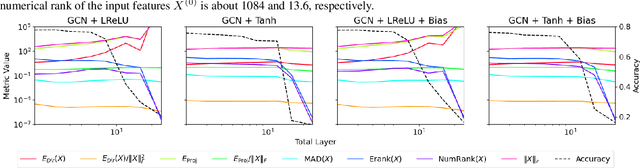
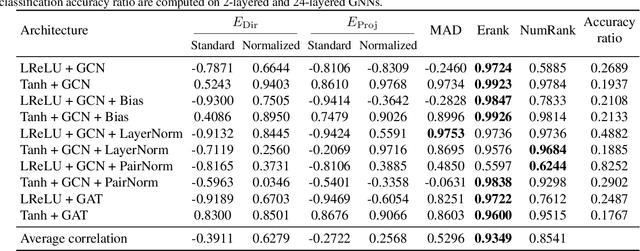
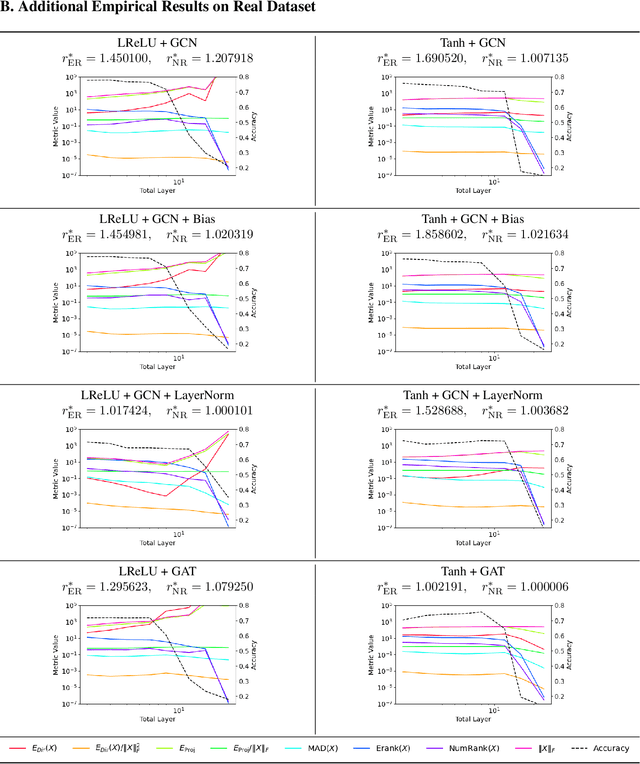
Oversmoothing is a fundamental challenge in graph neural networks (GNNs): as the number of layers increases, node embeddings become increasingly similar, and model performance drops sharply. Traditionally, oversmoothing has been quantified using metrics that measure the similarity of neighbouring node features, such as the Dirichlet energy. While these metrics are related to oversmoothing, we argue they have critical limitations and fail to reliably capture oversmoothing in realistic scenarios. For instance, they provide meaningful insights only for very deep networks and under somewhat strict conditions on the norm of network weights and feature representations. As an alternative, we propose measuring oversmoothing by examining the numerical or effective rank of the feature representations. We provide theoretical support for this approach, demonstrating that the numerical rank of feature representations converges to one for a broad family of nonlinear activation functions under the assumption of nonnegative trained weights. To the best of our knowledge, this is the first result that proves the occurrence of oversmoothing without assumptions on the boundedness of the weight matrices. Along with the theoretical findings, we provide extensive numerical evaluation across diverse graph architectures. Our results show that rank-based metrics consistently capture oversmoothing, whereas energy-based metrics often fail. Notably, we reveal that a significant drop in the rank aligns closely with performance degradation, even in scenarios where energy metrics remain unchanged.
Neural Rank Collapse: Weight Decay and Small Within-Class Variability Yield Low-Rank Bias
Feb 06, 2024Recent work in deep learning has shown strong empirical and theoretical evidence of an implicit low-rank bias: weight matrices in deep networks tend to be approximately low-rank and removing relatively small singular values during training or from available trained models may significantly reduce model size while maintaining or even improving model performance. However, the majority of the theoretical investigations around low-rank bias in neural networks deal with oversimplified deep linear networks. In this work, we consider general networks with nonlinear activations and the weight decay parameter, and we show the presence of an intriguing neural rank collapse phenomenon, connecting the low-rank bias of trained networks with networks' neural collapse properties: as the weight decay parameter grows, the rank of each layer in the network decreases proportionally to the within-class variability of the hidden-space embeddings of the previous layers. Our theoretical findings are supported by a range of experimental evaluations illustrating the phenomenon.