 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoLoRA: Geometric integration for parameter efficient fine-tuning
Oct 24, 2024Low-Rank Adaptation (LoRA) has become a widely used method for parameter-efficient fine-tuning of large-scale, pre-trained neural networks. However, LoRA and its extensions face several challenges, including the need for rank adaptivity, robustness, and computational efficiency during the fine-tuning process. We introduce GeoLoRA, a novel approach that addresses these limitations by leveraging dynamical low-rank approximation theory. GeoLoRA requires only a single backpropagation pass over the small-rank adapters, significantly reducing computational cost as compared to similar dynamical low-rank training methods and making it faster than popular baselines such as AdaLoRA. This allows GeoLoRA to efficiently adapt the allocated parameter budget across the model, achieving smaller low-rank adapters compared to heuristic methods like AdaLoRA and LoRA, while maintaining critical convergence, descent, and error-bound theoretical guarantees. The resulting method is not only more efficient but also more robust to varying hyperparameter settings. We demonstrate the effectiveness of GeoLoRA on several state-of-the-art benchmarks, showing that it outperforms existing methods in both accuracy and computational efficiency.
Low-Rank Adversarial PGD Attack
Oct 16, 2024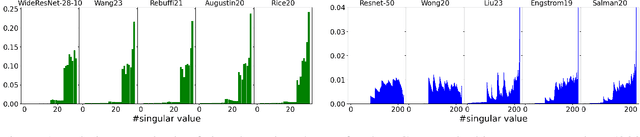
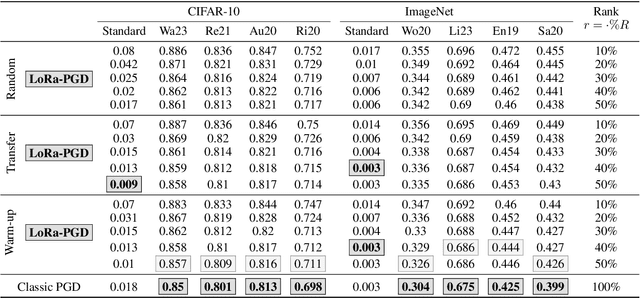
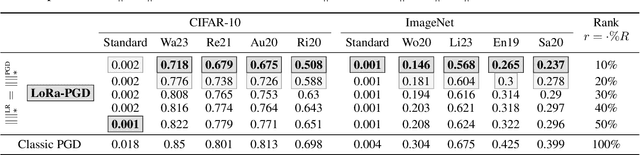
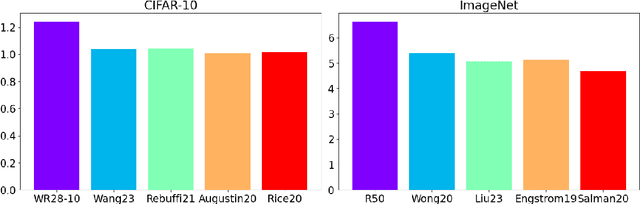
Adversarial attacks on deep neural network models have seen rapid development and are extensively used to study the stability of these networks. Among various adversarial strategies, Projected Gradient Descent (PGD) is a widely adopted method in computer vision due to its effectiveness and quick implementation, making it suitable for adversarial training. In this work, we observe that in many cases, the perturbations computed using PGD predominantly affect only a portion of the singular value spectrum of the original image, suggesting that these perturbations are approximately low-rank. Motivated by this observation, we propose a variation of PGD that efficiently computes a low-rank attack. We extensively validate our method on a range of standard models as well as robust models that have undergone adversarial training. Our analysis indicates that the proposed low-rank PGD can be effectively used in adversarial training due to its straightforward and fast implementation coupled with competitive performance. Notably, we find that low-rank PGD often performs comparably to, and sometimes even outperforms, the traditional full-rank PGD attack, while using significantly less memory.
Neural Rank Collapse: Weight Decay and Small Within-Class Variability Yield Low-Rank Bias
Feb 06, 2024Recent work in deep learning has shown strong empirical and theoretical evidence of an implicit low-rank bias: weight matrices in deep networks tend to be approximately low-rank and removing relatively small singular values during training or from available trained models may significantly reduce model size while maintaining or even improving model performance. However, the majority of the theoretical investigations around low-rank bias in neural networks deal with oversimplified deep linear networks. In this work, we consider general networks with nonlinear activations and the weight decay parameter, and we show the presence of an intriguing neural rank collapse phenomenon, connecting the low-rank bias of trained networks with networks' neural collapse properties: as the weight decay parameter grows, the rank of each layer in the network decreases proportionally to the within-class variability of the hidden-space embeddings of the previous layers. Our theoretical findings are supported by a range of experimental evaluations illustrating the phenomenon.
Robust low-rank training via approximate orthonormal constraints
Jun 02, 2023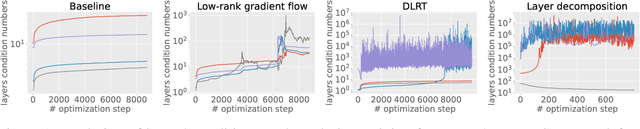
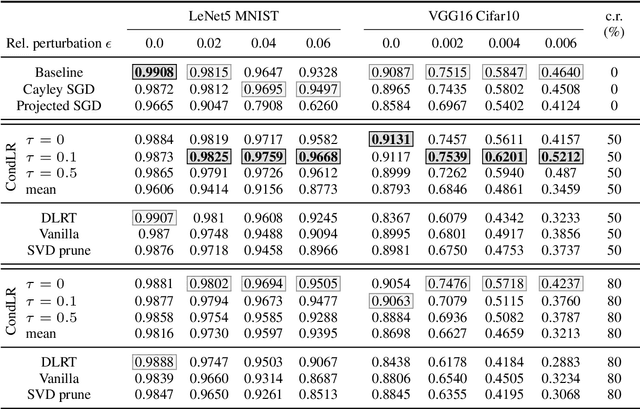

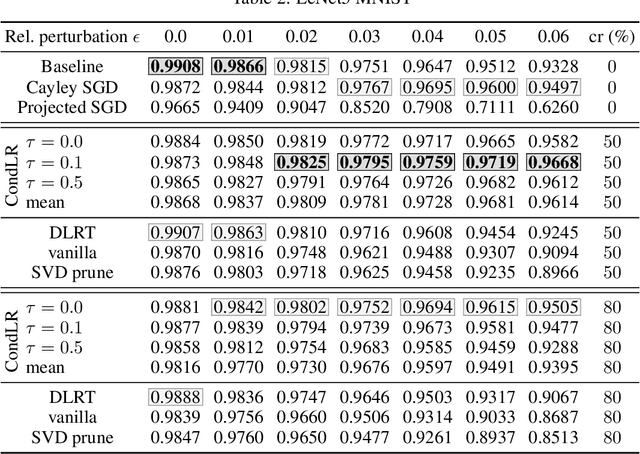
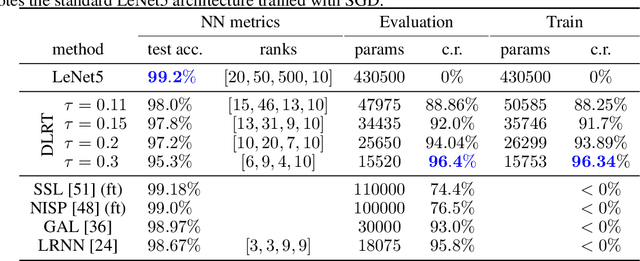
With the growth of model and data sizes, a broad effort has been made to design pruning techniques that reduce the resource demand of deep learning pipelines, while retaining model performance. In order to reduce both inference and training costs, a prominent line of work uses low-rank matrix factorizations to represent the network weights. Although able to retain accuracy, we observe that low-rank methods tend to compromise model robustness against adversarial perturbations. By modeling robustness in terms of the condition number of the neural network, we argue that this loss of robustness is due to the exploding singular values of the low-rank weight matrices. Thus, we introduce a robust low-rank training algorithm that maintains the network's weights on the low-rank matrix manifold while simultaneously enforcing approximate orthonormal constraints. The resulting model reduces both training and inference costs while ensuring well-conditioning and thus better adversarial robustness, without compromising model accuracy. This is shown by extensive numerical evidence and by our main approximation theorem that shows the computed robust low-rank network well-approximates the ideal full model, provided a highly performing low-rank sub-network exists.
Rank-adaptive spectral pruning of convolutional layers during training
May 30, 2023The computing cost and memory demand of deep learning pipelines have grown fast in recent years and thus a variety of pruning techniques have been developed to reduce model parameters. The majority of these techniques focus on reducing inference costs by pruning the network after a pass of full training. A smaller number of methods address the reduction of training costs, mostly based on compressing the network via low-rank layer factorizations. Despite their efficiency for linear layers, these methods fail to effectively handle convolutional filters. In this work, we propose a low-parametric training method that factorizes the convolutions into tensor Tucker format and adaptively prunes the Tucker ranks of the convolutional kernel during training. Leveraging fundamental results from geometric integration theory of differential equations on tensor manifolds, we obtain a robust training algorithm that provably approximates the full baseline performance and guarantees loss descent. A variety of experiments against the full model and alternative low-rank baselines are implemented, showing that the proposed method drastically reduces the training costs, while achieving high performance, comparable to or better than the full baseline, and consistently outperforms competing low-rank approaches.
Low-rank lottery tickets: finding efficient low-rank neural networks via matrix differential equations
May 26, 2022
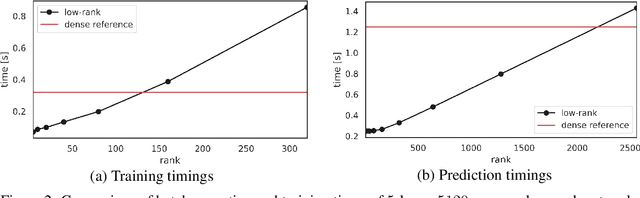
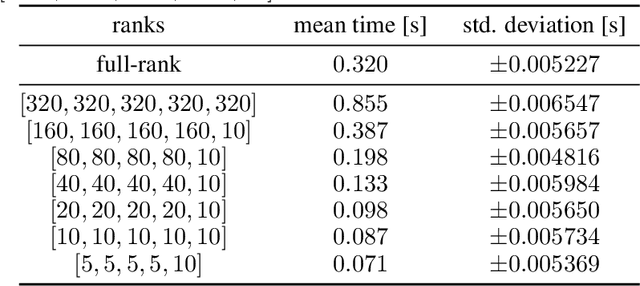
Neural networks have achieved tremendous success in a large variety of applications. However, their memory footprint and computational demand can render them impractical in application settings with limited hardware or energy resources. In this work, we propose a novel algorithm to find efficient low-rank subnetworks. Remarkably, these subnetworks are determined and adapted already during the training phase and the overall time and memory resources required by both training and evaluating them is significantly reduced. The main idea is to restrict the weight matrices to a low-rank manifold and to update the low-rank factors rather than the full matrix during training. To derive training updates that are restricted to the prescribed manifold, we employ techniques from dynamic model order reduction for matrix differential equations. Moreover, our method automatically and dynamically adapts the ranks during training to achieve a desired approximation accuracy. The efficiency of the proposed method is demonstrated through a variety of numerical experiments on fully-connected and convolutional networks.