 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTucker Attention: A generalization of approximate attention mechanisms
Mar 31, 2026The pursuit of reducing the memory footprint of the self-attention mechanism in multi-headed self attention (MHA) spawned a rich portfolio of methods, e.g., group-query attention (GQA) and multi-head latent attention (MLA). The methods leverage specialized low-rank factorizations across embedding dimensions or attention heads. From the point of view of classical low-rank approximation, these methods are unconventional and raise questions of which objects they really approximate and how to interpret the low-rank behavior of the resulting representations. To answer these questions, this work proposes a generalized view on the weight objects in the self-attention layer and a factorization strategy, which allows us to construct a parameter efficient scheme, called Tucker Attention. Tucker Attention requires an order of magnitude fewer parameters for comparable validation metrics, compared to GQA and MLA, as evaluated in LLM and ViT test cases. Additionally, Tucker Attention~encompasses GQA, MLA, MHA as special cases and is fully compatible with flash-attention and rotary position embeddings (RoPE). This generalization strategy yields insights of the actual ranks achieved by MHA, GQA, and MLA, and further enables simplifications for MLA.
An Augmented Backward-Corrected Projector Splitting Integrator for Dynamical Low-Rank Training
Feb 05, 2025Layer factorization has emerged as a widely used technique for training memory-efficient neural networks. However, layer factorization methods face several challenges, particularly a lack of robustness during the training process. To overcome this limitation, dynamical low-rank training methods have been developed, utilizing robust time integration techniques for low-rank matrix differential equations. Although these approaches facilitate efficient training, they still depend on computationally intensive QR and singular value decompositions of matrices with small rank. In this work, we introduce a novel low-rank training method that reduces the number of required QR decompositions. Our approach integrates an augmentation step into a projector-splitting scheme, ensuring convergence to a locally optimal solution. We provide a rigorous theoretical analysis of the proposed method and demonstrate its effectiveness across multiple benchmarks.
GeoLoRA: Geometric integration for parameter efficient fine-tuning
Oct 24, 2024Low-Rank Adaptation (LoRA) has become a widely used method for parameter-efficient fine-tuning of large-scale, pre-trained neural networks. However, LoRA and its extensions face several challenges, including the need for rank adaptivity, robustness, and computational efficiency during the fine-tuning process. We introduce GeoLoRA, a novel approach that addresses these limitations by leveraging dynamical low-rank approximation theory. GeoLoRA requires only a single backpropagation pass over the small-rank adapters, significantly reducing computational cost as compared to similar dynamical low-rank training methods and making it faster than popular baselines such as AdaLoRA. This allows GeoLoRA to efficiently adapt the allocated parameter budget across the model, achieving smaller low-rank adapters compared to heuristic methods like AdaLoRA and LoRA, while maintaining critical convergence, descent, and error-bound theoretical guarantees. The resulting method is not only more efficient but also more robust to varying hyperparameter settings. We demonstrate the effectiveness of GeoLoRA on several state-of-the-art benchmarks, showing that it outperforms existing methods in both accuracy and computational efficiency.
Rank-adaptive spectral pruning of convolutional layers during training
May 30, 2023The computing cost and memory demand of deep learning pipelines have grown fast in recent years and thus a variety of pruning techniques have been developed to reduce model parameters. The majority of these techniques focus on reducing inference costs by pruning the network after a pass of full training. A smaller number of methods address the reduction of training costs, mostly based on compressing the network via low-rank layer factorizations. Despite their efficiency for linear layers, these methods fail to effectively handle convolutional filters. In this work, we propose a low-parametric training method that factorizes the convolutions into tensor Tucker format and adaptively prunes the Tucker ranks of the convolutional kernel during training. Leveraging fundamental results from geometric integration theory of differential equations on tensor manifolds, we obtain a robust training algorithm that provably approximates the full baseline performance and guarantees loss descent. A variety of experiments against the full model and alternative low-rank baselines are implemented, showing that the proposed method drastically reduces the training costs, while achieving high performance, comparable to or better than the full baseline, and consistently outperforms competing low-rank approaches.
Low-rank lottery tickets: finding efficient low-rank neural networks via matrix differential equations
May 26, 2022
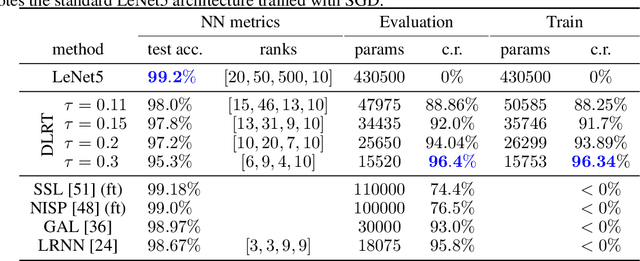
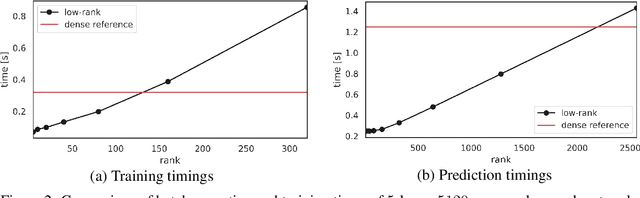
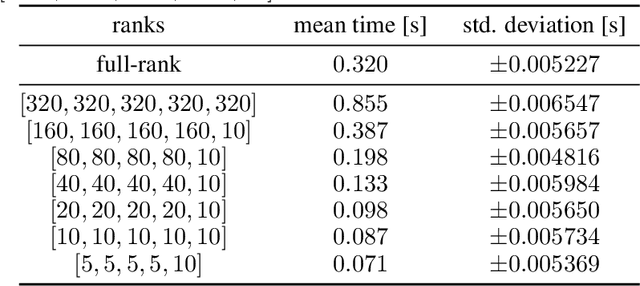
Neural networks have achieved tremendous success in a large variety of applications. However, their memory footprint and computational demand can render them impractical in application settings with limited hardware or energy resources. In this work, we propose a novel algorithm to find efficient low-rank subnetworks. Remarkably, these subnetworks are determined and adapted already during the training phase and the overall time and memory resources required by both training and evaluating them is significantly reduced. The main idea is to restrict the weight matrices to a low-rank manifold and to update the low-rank factors rather than the full matrix during training. To derive training updates that are restricted to the prescribed manifold, we employ techniques from dynamic model order reduction for matrix differential equations. Moreover, our method automatically and dynamically adapts the ranks during training to achieve a desired approximation accuracy. The efficiency of the proposed method is demonstrated through a variety of numerical experiments on fully-connected and convolutional networks.