 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Large Language Models via Reinforcement Learning from Self-Feedback
Jul 29, 2025Large Language Models (LLMs) often produce plausible but poorly-calibrated answers, limiting their reliability on reasoning-intensive tasks. We present Reinforcement Learning from Self-Feedback (RLSF), a post-training stage that uses the model's own confidence as an intrinsic reward, mimicking how humans learn in the absence of external feedback. After a frozen LLM generates several chain-of-thought solutions, we define and compute the confidence of each final answer span and rank the traces accordingly. These synthetic preferences are then used to fine-tune the policy with standard preference optimization, similar to RLHF yet requiring no human labels, gold answers, or externally curated rewards. RLSF simultaneously (i) refines the model's probability estimates -- restoring well-behaved calibration -- and (ii) strengthens step-by-step reasoning, yielding improved performance on arithmetic reasoning and multiple-choice question answering. By turning a model's own uncertainty into useful self-feedback, RLSF affirms reinforcement learning on intrinsic model behaviour as a principled and data-efficient component of the LLM post-training pipeline and warrents further research in intrinsic rewards for LLM post-training.
Emotionally Intelligent Task-oriented Dialogue Systems: Architecture, Representation, and Optimisation
Jul 02, 2025Task-oriented dialogue (ToD) systems are designed to help users achieve specific goals through natural language interaction. While recent advances in large language models (LLMs) have significantly improved linguistic fluency and contextual understanding, building effective and emotionally intelligent ToD systems remains a complex challenge. Effective ToD systems must optimise for task success, emotional understanding and responsiveness, and precise information conveyance, all within inherently noisy and ambiguous conversational environments. In this work, we investigate architectural, representational, optimisational as well as emotional considerations of ToD systems. We set up systems covering these design considerations with a challenging evaluation environment composed of a natural-language user simulator coupled with an imperfect natural language understanding module. We propose \textbf{LUSTER}, an \textbf{L}LM-based \textbf{U}nified \textbf{S}ystem for \textbf{T}ask-oriented dialogue with \textbf{E}nd-to-end \textbf{R}einforcement learning with both short-term (user sentiment) and long-term (task success) rewards. Our findings demonstrate that combining LLM capability with structured reward modelling leads to more resilient and emotionally responsive ToD systems, offering a practical path forward for next-generation conversational agents.
Local Topology Measures of Contextual Language Model Latent Spaces With Applications to Dialogue Term Extraction
Aug 07, 2024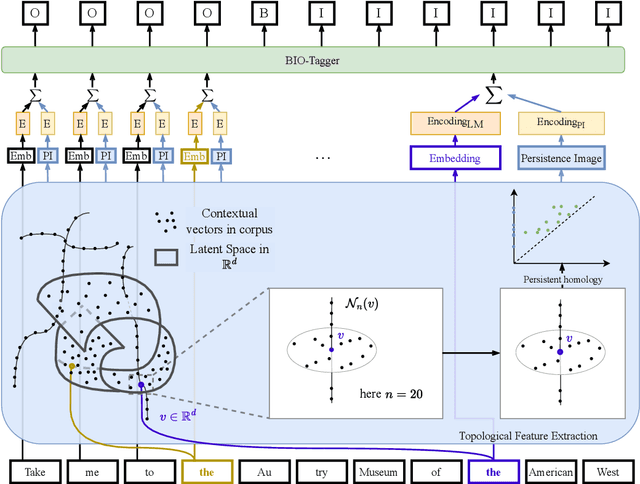

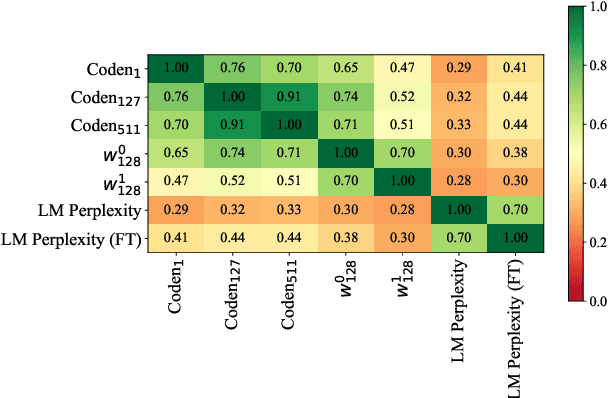

A common approach for sequence tagging tasks based on contextual word representations is to train a machine learning classifier directly on these embedding vectors. This approach has two shortcomings. First, such methods consider single input sequences in isolation and are unable to put an individual embedding vector in relation to vectors outside the current local context of use. Second, the high performance of these models relies on fine-tuning the embedding model in conjunction with the classifier, which may not always be feasible due to the size or inaccessibility of the underlying feature-generation model. It is thus desirable, given a collection of embedding vectors of a corpus, i.e., a datastore, to find features of each vector that describe its relation to other, similar vectors in the datastore. With this in mind, we introduce complexity measures of the local topology of the latent space of a contextual language model with respect to a given datastore. The effectiveness of our features is demonstrated through their application to dialogue term extraction. Our work continues a line of research that explores the manifold hypothesis for word embeddings, demonstrating that local structure in the space carved out by word embeddings can be exploited to infer semantic properties.
Infusing Emotions into Task-oriented Dialogue Systems: Understanding, Management, and Generation
Aug 05, 2024
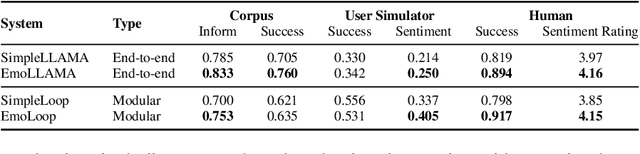
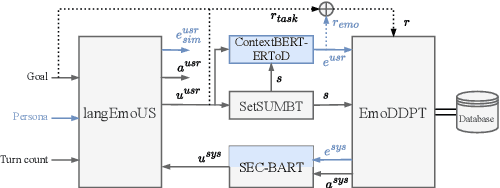
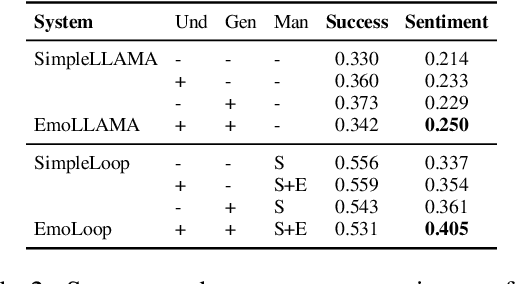
Emotions are indispensable in human communication, but are often overlooked in task-oriented dialogue (ToD) modelling, where the task success is the primary focus. While existing works have explored user emotions or similar concepts in some ToD tasks, none has so far included emotion modelling into a fully-fledged ToD system nor conducted interaction with human or simulated users. In this work, we incorporate emotion into the complete ToD processing loop, involving understanding, management, and generation. To this end, we extend the EmoWOZ dataset (Feng et al., 2022) with system affective behaviour labels. Through interactive experimentation involving both simulated and human users, we demonstrate that our proposed framework significantly enhances the user's emotional experience as well as the task success.
CAMELL: Confidence-based Acquisition Model for Efficient Self-supervised Active Learning with Label Validation
Oct 13, 2023Supervised neural approaches are hindered by their dependence on large, meticulously annotated datasets, a requirement that is particularly cumbersome for sequential tasks. The quality of annotations tends to deteriorate with the transition from expert-based to crowd-sourced labelling. To address these challenges, we present \textbf{CAMELL} (Confidence-based Acquisition Model for Efficient self-supervised active Learning with Label validation), a pool-based active learning framework tailored for sequential multi-output problems. CAMELL possesses three core features: (1) it requires expert annotators to label only a fraction of a chosen sequence, (2) it facilitates self-supervision for the remainder of the sequence, and (3) it employs a label validation mechanism to prevent erroneous labels from contaminating the dataset and harming model performance. We evaluate CAMELL on sequential tasks, with a special emphasis on dialogue belief tracking, a task plagued by the constraints of limited and noisy datasets. Our experiments demonstrate that CAMELL outperforms the baselines in terms of efficiency. Furthermore, the data corrections suggested by our method contribute to an overall improvement in the quality of the resulting datasets.
From Chatter to Matter: Addressing Critical Steps of Emotion Recognition Learning in Task-oriented Dialogue
Aug 24, 2023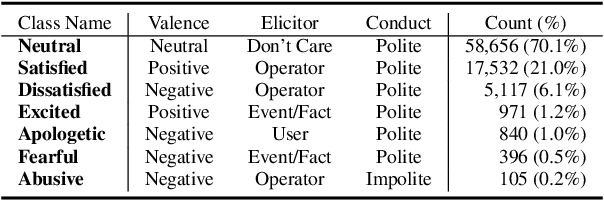
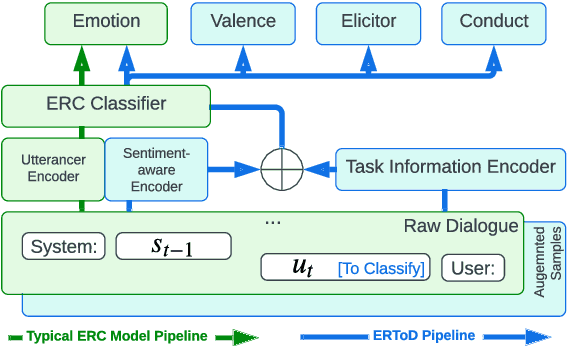
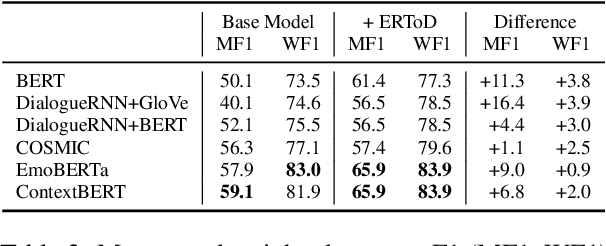
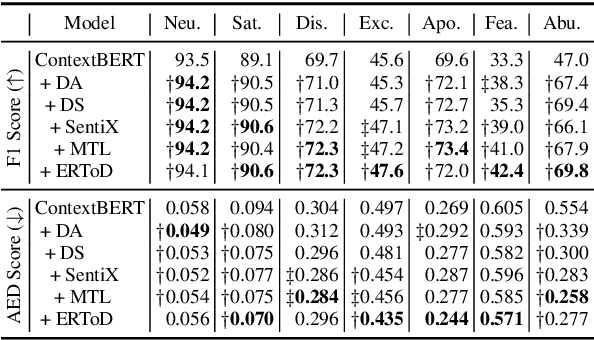
Emotion recognition in conversations (ERC) is a crucial task for building human-like conversational agents. While substantial efforts have been devoted to ERC for chit-chat dialogues, the task-oriented counterpart is largely left unattended. Directly applying chit-chat ERC models to task-oriented dialogues (ToDs) results in suboptimal performance as these models overlook key features such as the correlation between emotions and task completion in ToDs. In this paper, we propose a framework that turns a chit-chat ERC model into a task-oriented one, addressing three critical aspects: data, features and objective. First, we devise two ways of augmenting rare emotions to improve ERC performance. Second, we use dialogue states as auxiliary features to incorporate key information from the goal of the user. Lastly, we leverage a multi-aspect emotion definition in ToDs to devise a multi-task learning objective and a novel emotion-distance weighted loss function. Our framework yields significant improvements for a range of chit-chat ERC models on EmoWOZ, a large-scale dataset for user emotion in ToDs. We further investigate the generalisability of the best resulting model to predict user satisfaction in different ToD datasets. A comparison with supervised baselines shows a strong zero-shot capability, highlighting the potential usage of our framework in wider scenarios.
ConvLab-3: A Flexible Dialogue System Toolkit Based on a Unified Data Format
Nov 30, 2022Diverse data formats and ontologies of task-oriented dialogue (TOD) datasets hinder us from developing general dialogue models that perform well on many datasets and studying knowledge transfer between datasets. To address this issue, we present ConvLab-3, a flexible dialogue system toolkit based on a unified TOD data format. In ConvLab-3, different datasets are transformed into one unified format and loaded by models in the same way. As a result, the cost of adapting a new model or dataset is significantly reduced. Compared to the previous releases of ConvLab (Lee et al., 2019b; Zhu et al., 2020b), ConvLab-3 allows developing dialogue systems with much more datasets and enhances the utility of the reinforcement learning (RL) toolkit for dialogue policies. To showcase the use of ConvLab-3 and inspire future work, we present a comprehensive study with various settings. We show the benefit of pre-training on other datasets for few-shot fine-tuning and RL, and encourage evaluating policy with diverse user simulators.
What Does The User Want? Information Gain for Hierarchical Dialogue Policy Optimisation
Sep 15, 2021
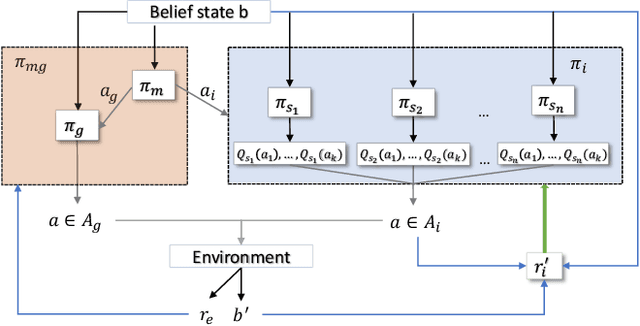
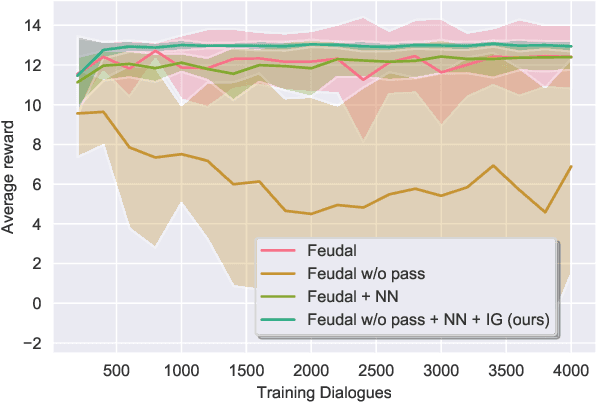
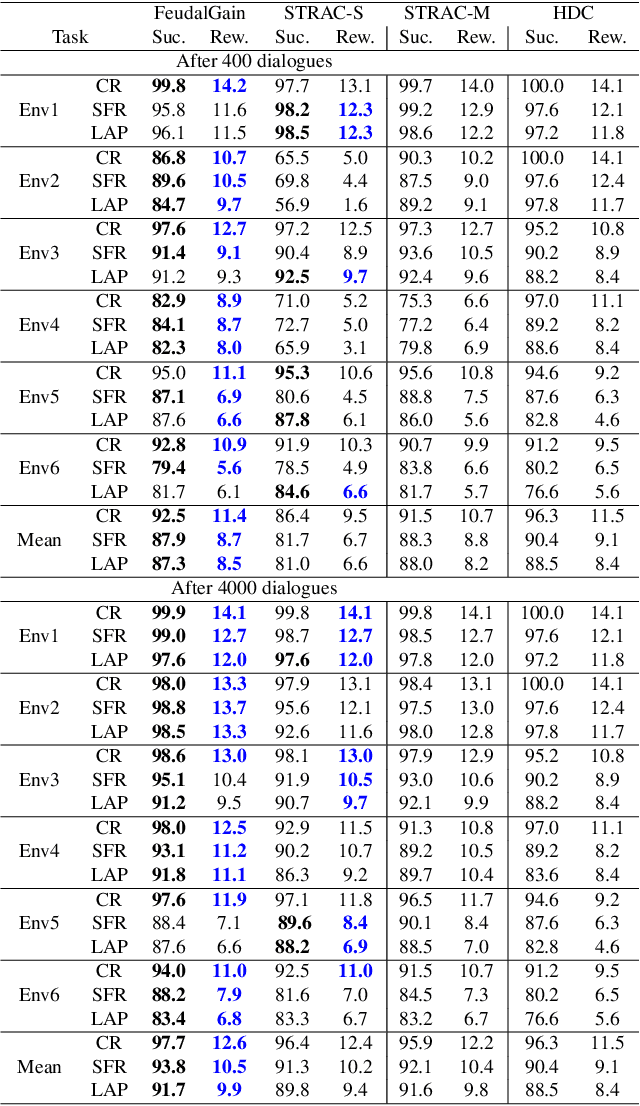
The dialogue management component of a task-oriented dialogue system is typically optimised via reinforcement learning (RL). Optimisation via RL is highly susceptible to sample inefficiency and instability. The hierarchical approach called Feudal Dialogue Management takes a step towards more efficient learning by decomposing the action space. However, it still suffers from instability due to the reward only being provided at the end of the dialogue. We propose the usage of an intrinsic reward based on information gain to address this issue. Our proposed reward favours actions that resolve uncertainty or query the user whenever necessary. It enables the policy to learn how to retrieve the users' needs efficiently, which is an integral aspect in every task-oriented conversation. Our algorithm, which we call FeudalGain, achieves state-of-the-art results in most environments of the PyDial framework, outperforming much more complex approaches. We confirm the sample efficiency and stability of our algorithm through experiments in simulation and a human trial.
EmoWOZ: A Large-Scale Corpus and Labelling Scheme for Emotion in Task-Oriented Dialogue Systems
Sep 10, 2021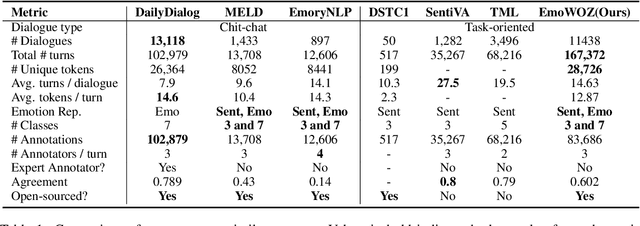

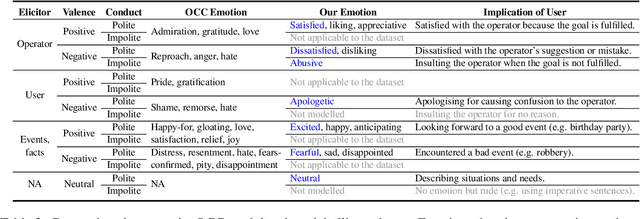

The ability to recognise emotions lends a conversational artificial intelligence a human touch. While emotions in chit-chat dialogues have received substantial attention, emotions in task-oriented dialogues have been largely overlooked despite having an equally important role, such as to signal failure or success. Existing emotion-annotated task-oriented corpora are limited in size, label richness, and public availability, creating a bottleneck for downstream tasks. To lay a foundation for studies on emotions in task-oriented dialogues, we introduce EmoWOZ, a large-scale manually emotion-annotated corpus of task-oriented dialogues. EmoWOZ is based on MultiWOZ, a multi-domain task-oriented dialogue dataset. It contains more than 11K dialogues with more than 83K emotion annotations of user utterances. In addition to Wizzard-of-Oz dialogues from MultiWOZ, we collect human-machine dialogues within the same set of domains to sufficiently cover the space of various emotions that can happen during the lifetime of a data-driven dialogue system. To the best of our knowledge, this is the first large-scale open-source corpus of its kind. We propose a novel emotion labelling scheme, which is tailored to task-oriented dialogues. We report a set of experimental results to show the usability of this corpus for emotion recognition and state tracking in task-oriented dialogues.
Uncertainty Measures in Neural Belief Tracking and the Effects on Dialogue Policy Performance
Sep 09, 2021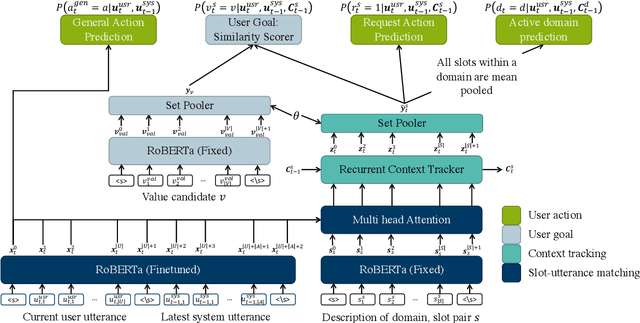
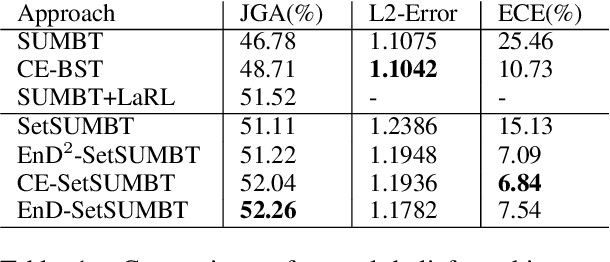
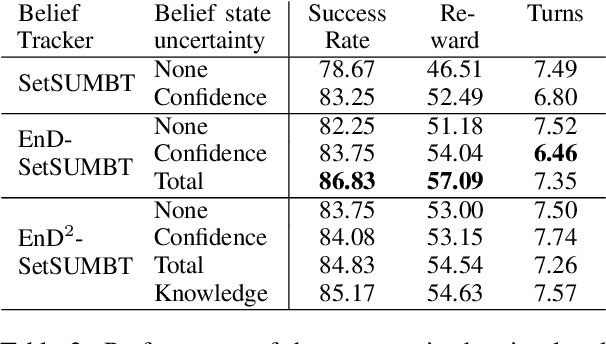
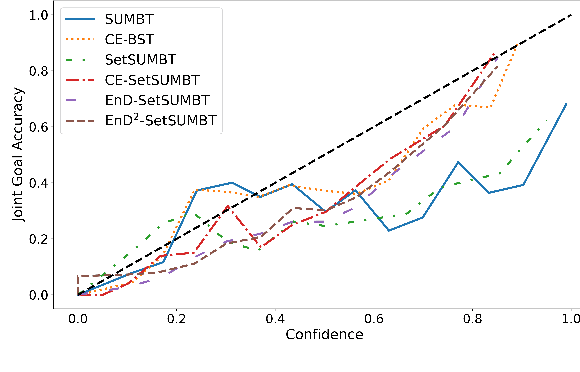
The ability to identify and resolve uncertainty is crucial for the robustness of a dialogue system. Indeed, this has been confirmed empirically on systems that utilise Bayesian approaches to dialogue belief tracking. However, such systems consider only confidence estimates and have difficulty scaling to more complex settings. Neural dialogue systems, on the other hand, rarely take uncertainties into account. They are therefore overconfident in their decisions and less robust. Moreover, the performance of the tracking task is often evaluated in isolation, without consideration of its effect on the downstream policy optimisation. We propose the use of different uncertainty measures in neural belief tracking. The effects of these measures on the downstream task of policy optimisation are evaluated by adding selected measures of uncertainty to the feature space of the policy and training policies through interaction with a user simulator. Both human and simulated user results show that incorporating these measures leads to improvements both of the performance and of the robustness of the downstream dialogue policy. This highlights the importance of developing neural dialogue belief trackers that take uncertainty into account.