 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Topology Measures of Contextual Language Model Latent Spaces With Applications to Dialogue Term Extraction
Paper and Code
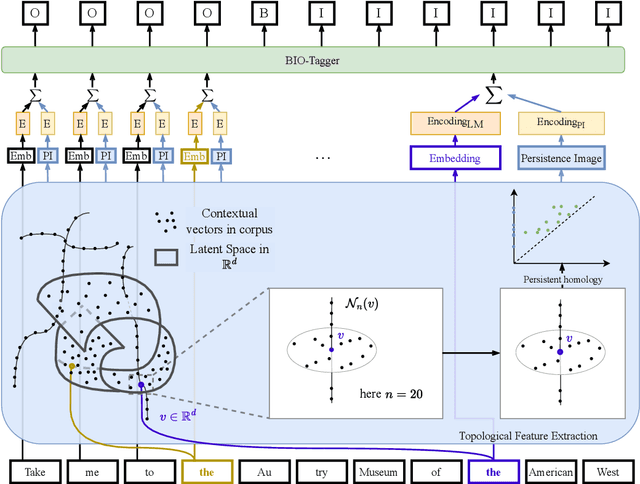


A common approach for sequence tagging tasks based on contextual word representations is to train a machine learning classifier directly on these embedding vectors. This approach has two shortcomings. First, such methods consider single input sequences in isolation and are unable to put an individual embedding vector in relation to vectors outside the current local context of use. Second, the high performance of these models relies on fine-tuning the embedding model in conjunction with the classifier, which may not always be feasible due to the size or inaccessibility of the underlying feature-generation model. It is thus desirable, given a collection of embedding vectors of a corpus, i.e., a datastore, to find features of each vector that describe its relation to other, similar vectors in the datastore. With this in mind, we introduce complexity measures of the local topology of the latent space of a contextual language model with respect to a given datastore. The effectiveness of our features is demonstrated through their application to dialogue term extraction. Our work continues a line of research that explores the manifold hypothesis for word embeddings, demonstrating that local structure in the space carved out by word embeddings can be exploited to infer semantic properties.