 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Topology Measures of Contextual Language Model Latent Spaces With Applications to Dialogue Term Extraction
Aug 07, 2024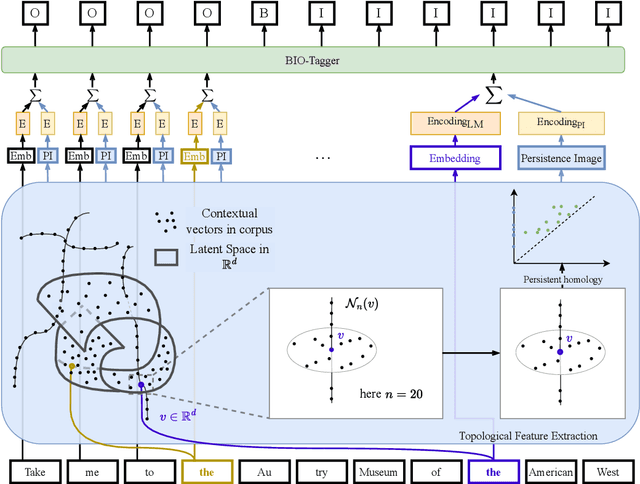


A common approach for sequence tagging tasks based on contextual word representations is to train a machine learning classifier directly on these embedding vectors. This approach has two shortcomings. First, such methods consider single input sequences in isolation and are unable to put an individual embedding vector in relation to vectors outside the current local context of use. Second, the high performance of these models relies on fine-tuning the embedding model in conjunction with the classifier, which may not always be feasible due to the size or inaccessibility of the underlying feature-generation model. It is thus desirable, given a collection of embedding vectors of a corpus, i.e., a datastore, to find features of each vector that describe its relation to other, similar vectors in the datastore. With this in mind, we introduce complexity measures of the local topology of the latent space of a contextual language model with respect to a given datastore. The effectiveness of our features is demonstrated through their application to dialogue term extraction. Our work continues a line of research that explores the manifold hypothesis for word embeddings, demonstrating that local structure in the space carved out by word embeddings can be exploited to infer semantic properties.
Dialogue Term Extraction using Transfer Learning and Topological Data Analysis
Aug 22, 2022
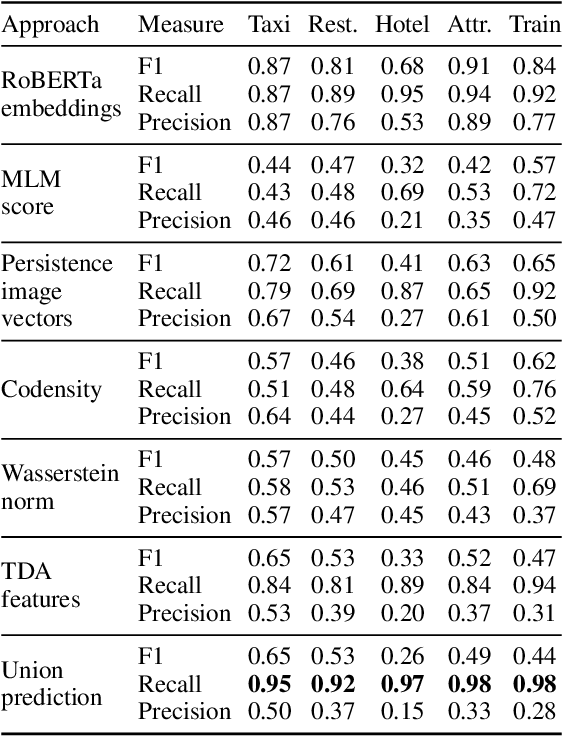

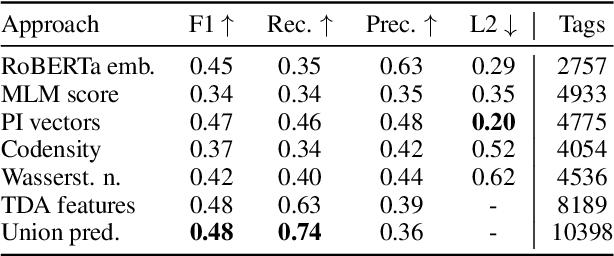
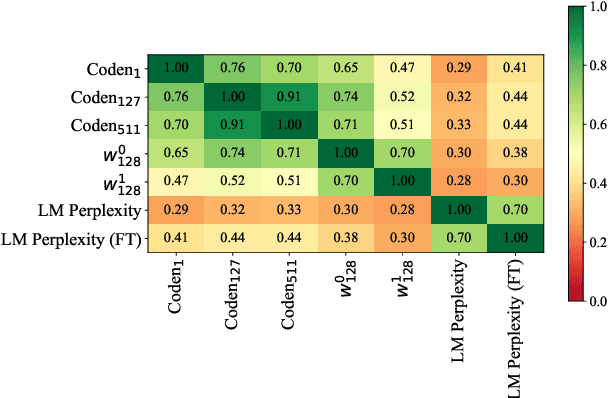
Goal oriented dialogue systems were originally designed as a natural language interface to a fixed data-set of entities that users might inquire about, further described by domain, slots, and values. As we move towards adaptable dialogue systems where knowledge about domains, slots, and values may change, there is an increasing need to automatically extract these terms from raw dialogues or related non-dialogue data on a large scale. In this paper, we take an important step in this direction by exploring different features that can enable systems to discover realizations of domains, slots, and values in dialogues in a purely data-driven fashion. The features that we examine stem from word embeddings, language modelling features, as well as topological features of the word embedding space. To examine the utility of each feature set, we train a seed model based on the widely used MultiWOZ data-set. Then, we apply this model to a different corpus, the Schema-Guided Dialogue data-set. Our method outperforms the previously proposed approach that relies solely on word embeddings. We also demonstrate that each of the features is responsible for discovering different kinds of content. We believe our results warrant further research towards ontology induction, and continued harnessing of topological data analysis for dialogue and natural language processing research.
Topology of Word Embeddings: Singularities Reflect Polysemy
Nov 18, 2020
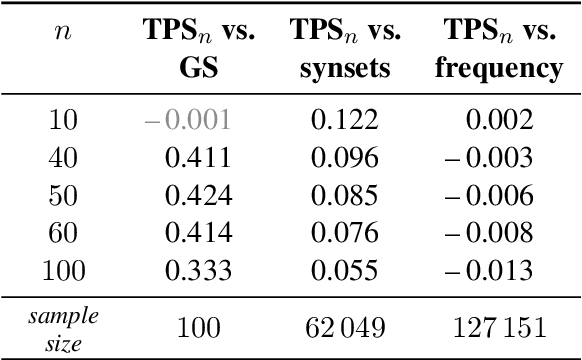

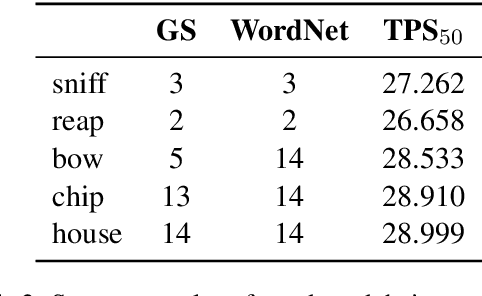
The manifold hypothesis suggests that word vectors live on a submanifold within their ambient vector space. We argue that we should, more accurately, expect them to live on a pinched manifold: a singular quotient of a manifold obtained by identifying some of its points. The identified, singular points correspond to polysemous words, i.e. words with multiple meanings. Our point of view suggests that monosemous and polysemous words can be distinguished based on the topology of their neighbourhoods. We present two kinds of empirical evidence to support this point of view: (1) We introduce a topological measure of polysemy based on persistent homology that correlates well with the actual number of meanings of a word. (2) We propose a simple, topologically motivated solution to the SemEval-2010 task on Word Sense Induction & Disambiguation that produces competitive results.