 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAVA: Latent Action Spaces via Variational Auto-encoding for Dialogue Policy Optimization
Paper and Code

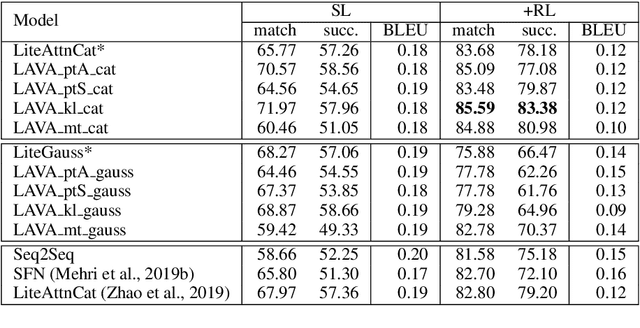
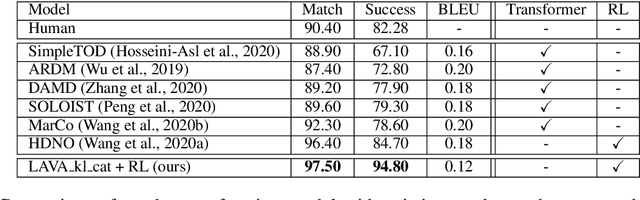

Reinforcement learning (RL) can enable task-oriented dialogue systems to steer the conversation towards successful task completion. In an end-to-end setting, a response can be constructed in a word-level sequential decision making process with the entire system vocabulary as action space. Policies trained in such a fashion do not require expert-defined action spaces, but they have to deal with large action spaces and long trajectories, making RL impractical. Using the latent space of a variational model as action space alleviates this problem. However, current approaches use an uninformed prior for training and optimize the latent distribution solely on the context. It is therefore unclear whether the latent representation truly encodes the characteristics of different actions. In this paper, we explore three ways of leveraging an auxiliary task to shape the latent variable distribution: via pre-training, to obtain an informed prior, and via multitask learning. We choose response auto-encoding as the auxiliary task, as this captures the generative factors of dialogue responses while requiring low computational cost and neither additional data nor labels. Our approach yields a more action-characterized latent representations which support end-to-end dialogue policy optimization and achieves state-of-the-art success rates. These results warrant a more wide-spread use of RL in end-to-end dialogue models.