 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Sentence Resampling: A Simple Approach to Alleviate Dataset Length Bias and Beam-Search Degradation
Paper and Code
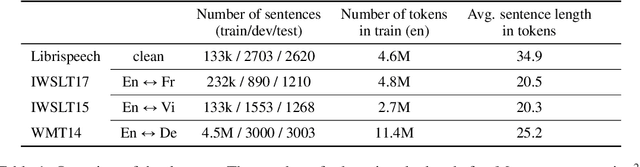
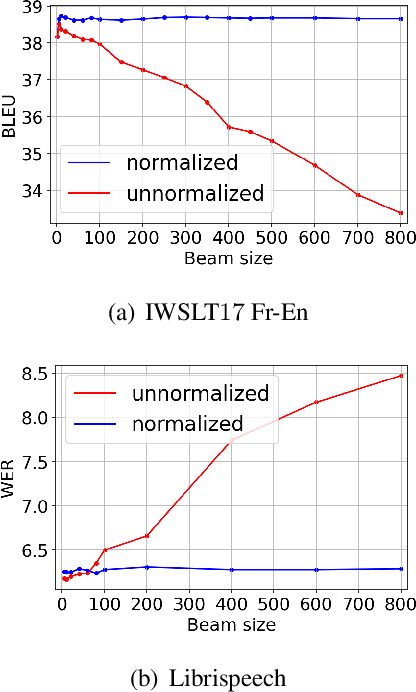

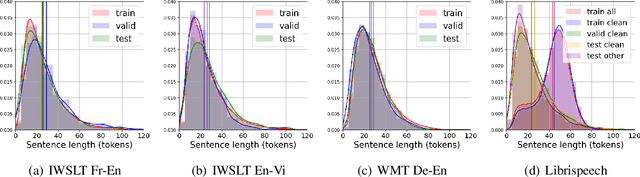
Neural Machine Translation (NMT) is known to suffer from a beam-search problem: after a certain point, increasing beam size causes an overall drop in translation quality. This effect is especially pronounced for long sentences. While much work was done analyzing this phenomenon, primarily for autoregressive NMT models, there is still no consensus on its underlying cause. In this work, we analyze errors that cause major quality degradation with large beams in NMT and Automatic Speech Recognition (ASR). We show that a factor that strongly contributes to the quality degradation with large beams is \textit{dataset length-bias} - \textit{NMT datasets are strongly biased towards short sentences}. To mitigate this issue, we propose a new data augmentation technique -- \textit{Multi-Sentence Resampling (MSR)}. This technique extends the training examples by concatenating several sentences from the original dataset to make a long training example. We demonstrate that MSR significantly reduces degradation with growing beam size and improves final translation quality on the IWSTL$15$ En-Vi, IWSTL$17$ En-Fr, and WMT$14$ En-De datasets.