 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Sentence Resampling: A Simple Approach to Alleviate Dataset Length Bias and Beam-Search Degradation
Sep 13, 2021
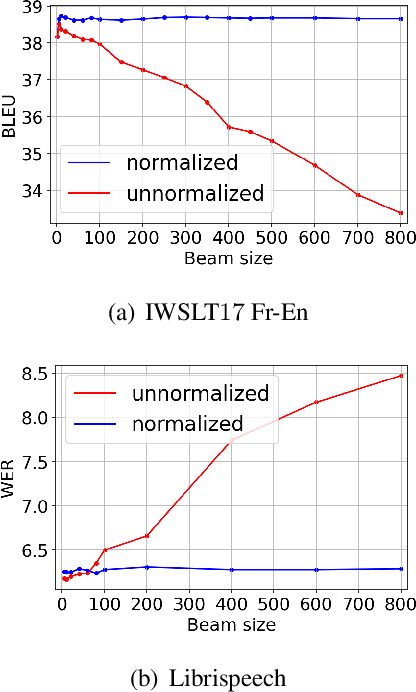

Neural Machine Translation (NMT) is known to suffer from a beam-search problem: after a certain point, increasing beam size causes an overall drop in translation quality. This effect is especially pronounced for long sentences. While much work was done analyzing this phenomenon, primarily for autoregressive NMT models, there is still no consensus on its underlying cause. In this work, we analyze errors that cause major quality degradation with large beams in NMT and Automatic Speech Recognition (ASR). We show that a factor that strongly contributes to the quality degradation with large beams is \textit{dataset length-bias} - \textit{NMT datasets are strongly biased towards short sentences}. To mitigate this issue, we propose a new data augmentation technique -- \textit{Multi-Sentence Resampling (MSR)}. This technique extends the training examples by concatenating several sentences from the original dataset to make a long training example. We demonstrate that MSR significantly reduces degradation with growing beam size and improves final translation quality on the IWSTL$15$ En-Vi, IWSTL$17$ En-Fr, and WMT$14$ En-De datasets.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021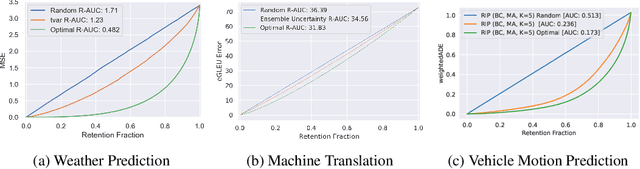
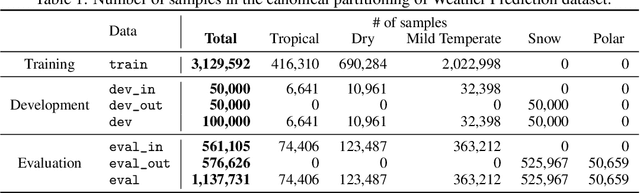
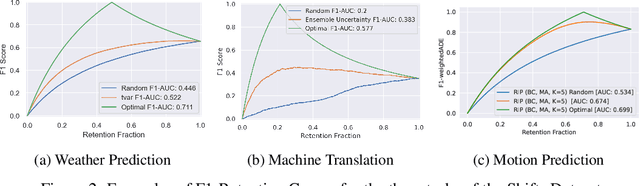
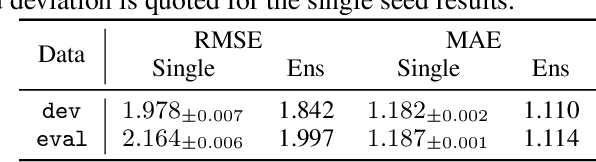
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
Regression Prior Networks
Jun 20, 2020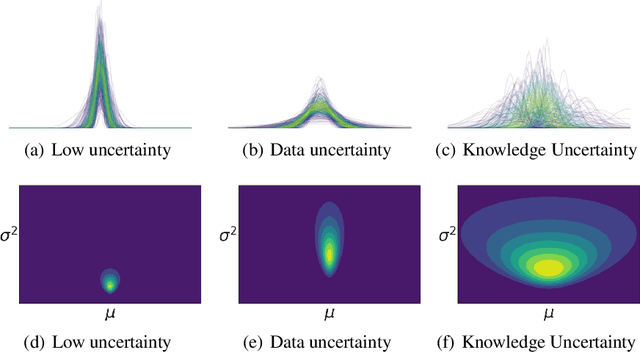

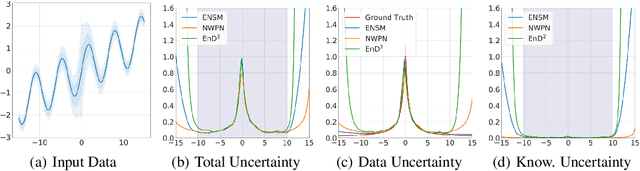
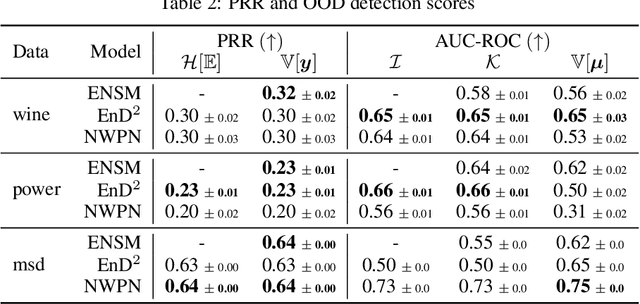
Prior Networks are a recently developed class of models which yield interpretable measures of uncertainty and have been shown to outperform state-of-the-art ensemble approaches on a range of tasks. They can also be used to distill an ensemble of models via Ensemble Distribution Distillation (EnD$^2$), such that its accuracy, calibration and uncertainty estimates are retained within a single model. However, Prior Networks have so far been developed only for classification tasks. This work extends Prior Networks and EnD$^2$ to regression tasks by considering the Normal-Wishart distribution. The properties of Regression Prior Networks are demonstrated on synthetic data, selected UCI datasets and a monocular depth estimation task, where they yield performance competitive with ensemble approaches.
BPE-Dropout: Simple and Effective Subword Regularization
Oct 29, 2019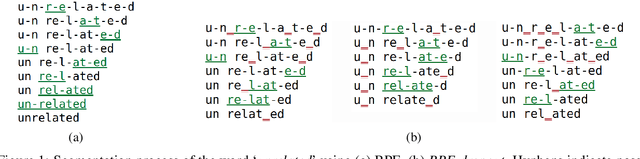
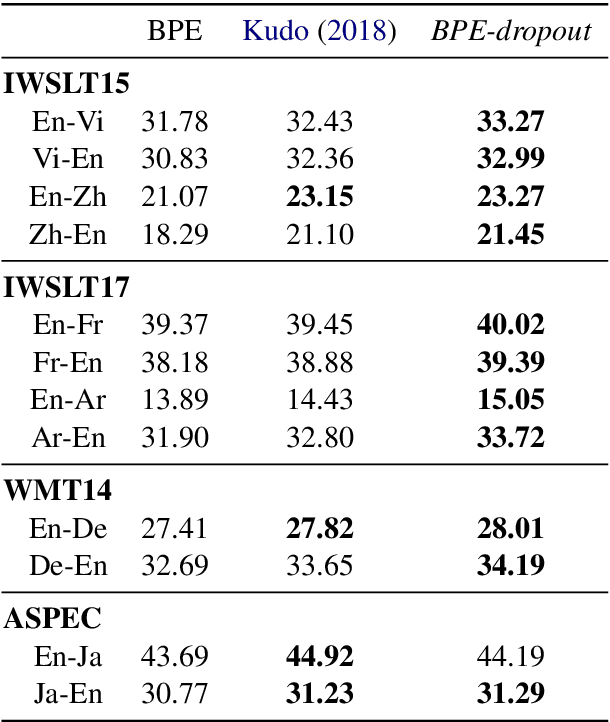
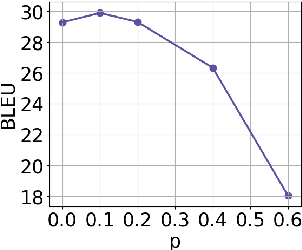
Subword segmentation is widely used to address the open vocabulary problem in machine translation. The dominant approach to subword segmentation is Byte Pair Encoding (BPE), which keeps the most frequent words intact while splitting the rare ones into multiple tokens. While multiple segmentations are possible even with the same vocabulary, BPE splits words into unique sequences; this may prevent a model from better learning the compositionality of words and being robust to segmentation errors. So far, the only way to overcome this BPE imperfection, its deterministic nature, was to create another subword segmentation algorithm (Kudo, 2018). In contrast, we show that BPE itself incorporates the ability to produce multiple segmentations of the same word. We introduce BPE-dropout - simple and effective subword regularization method based on and compatible with conventional BPE. It stochastically corrupts the segmentation procedure of BPE, which leads to producing multiple segmentations within the same fixed BPE framework. Using BPE-dropout during training and the standard BPE during inference improves translation quality up to 3 BLEU compared to BPE and up to 0.9 BLEU compared to the previous subword regularization.