 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBPE-Dropout: Simple and Effective Subword Regularization
Paper and Code
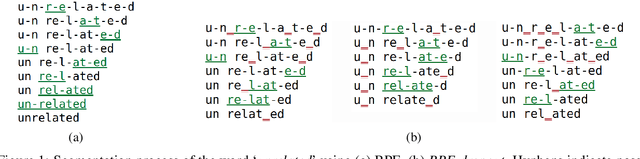
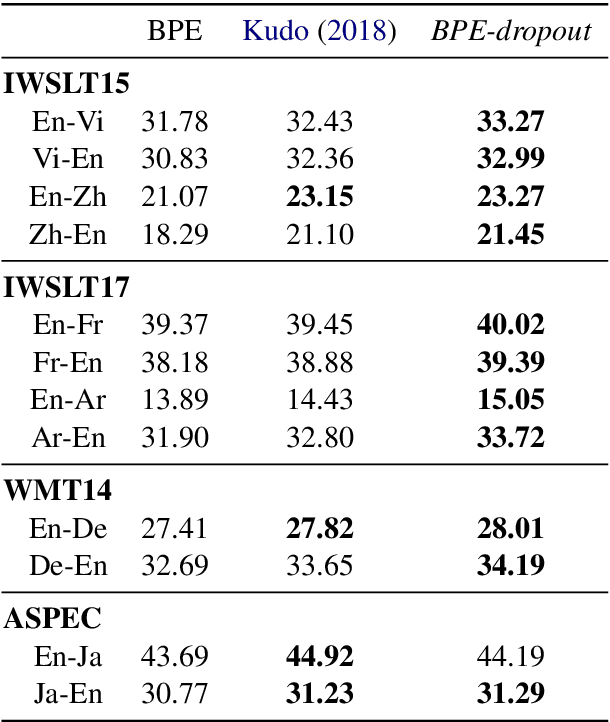
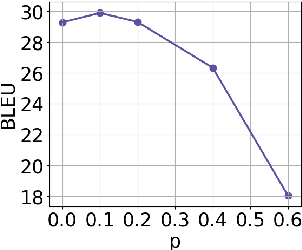
Subword segmentation is widely used to address the open vocabulary problem in machine translation. The dominant approach to subword segmentation is Byte Pair Encoding (BPE), which keeps the most frequent words intact while splitting the rare ones into multiple tokens. While multiple segmentations are possible even with the same vocabulary, BPE splits words into unique sequences; this may prevent a model from better learning the compositionality of words and being robust to segmentation errors. So far, the only way to overcome this BPE imperfection, its deterministic nature, was to create another subword segmentation algorithm (Kudo, 2018). In contrast, we show that BPE itself incorporates the ability to produce multiple segmentations of the same word. We introduce BPE-dropout - simple and effective subword regularization method based on and compatible with conventional BPE. It stochastically corrupts the segmentation procedure of BPE, which leads to producing multiple segmentations within the same fixed BPE framework. Using BPE-dropout during training and the standard BPE during inference improves translation quality up to 3 BLEU compared to BPE and up to 0.9 BLEU compared to the previous subword regularization.