 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Acoustic Adversarial Attacks for Flexible Control of Speech-LLMs
May 20, 2025The combination of pre-trained speech encoders with large language models has enabled the development of speech LLMs that can handle a wide range of spoken language processing tasks. While these models are powerful and flexible, this very flexibility may make them more vulnerable to adversarial attacks. To examine the extent of this problem, in this work we investigate universal acoustic adversarial attacks on speech LLMs. Here a fixed, universal, adversarial audio segment is prepended to the original input audio. We initially investigate attacks that cause the model to either produce no output or to perform a modified task overriding the original prompt. We then extend the nature of the attack to be selective so that it activates only when specific input attributes, such as a speaker gender or spoken language, are present. Inputs without the targeted attribute should be unaffected, allowing fine-grained control over the model outputs. Our findings reveal critical vulnerabilities in Qwen2-Audio and Granite-Speech and suggest that similar speech LLMs may be susceptible to universal adversarial attacks. This highlights the need for more robust training strategies and improved resistance to adversarial attacks.
Unlearning vs. Obfuscation: Are We Truly Removing Knowledge?
May 05, 2025Unlearning has emerged as a critical capability for large language models (LLMs) to support data privacy, regulatory compliance, and ethical AI deployment. Recent techniques often rely on obfuscation by injecting incorrect or irrelevant information to suppress knowledge. Such methods effectively constitute knowledge addition rather than true removal, often leaving models vulnerable to probing. In this paper, we formally distinguish unlearning from obfuscation and introduce a probing-based evaluation framework to assess whether existing approaches genuinely remove targeted information. Moreover, we propose DF-MCQ, a novel unlearning method that flattens the model predictive distribution over automatically generated multiple-choice questions using KL-divergence, effectively removing knowledge about target individuals and triggering appropriate refusal behaviour. Experimental results demonstrate that DF-MCQ achieves unlearning with over 90% refusal rate and a random choice-level uncertainty that is much higher than obfuscation on probing questions.
Speaker Retrieval in the Wild: Challenges, Effectiveness and Robustness
Apr 29, 2025There is a growing abundance of publicly available or company-owned audio/video archives, highlighting the increasing importance of efficient access to desired content and information retrieval from these archives. This paper investigates the challenges, solutions, effectiveness, and robustness of speaker retrieval systems developed "in the wild" which involves addressing two primary challenges: extraction of task-relevant labels from limited metadata for system development and evaluation, as well as the unconstrained acoustic conditions encountered in the archive, ranging from quiet studios to adverse noisy environments. While we focus on the publicly-available BBC Rewind archive (spanning 1948 to 1979), our framework addresses the broader issue of speaker retrieval on extensive and possibly aged archives with no control over the content and acoustic conditions. Typically, these archives offer a brief and general file description, mostly inadequate for specific applications like speaker retrieval, and manual annotation of such large-scale archives is unfeasible. We explore various aspects of system development (e.g., speaker diarisation, embedding extraction, query selection) and analyse the challenges, possible solutions, and their functionality. To evaluate the performance, we conduct systematic experiments in both clean setup and against various distortions simulating real-world applications. Our findings demonstrate the effectiveness and robustness of the developed speaker retrieval systems, establishing the versatility and scalability of the proposed framework for a wide range of applications beyond the BBC Rewind corpus.
SkillAggregation: Reference-free LLM-Dependent Aggregation
Oct 14, 2024Large Language Models (LLMs) are increasingly used to assess NLP tasks due to their ability to generate human-like judgments. Single LLMs were used initially, however, recent work suggests using multiple LLMs as judges yields improved performance. An important step in exploiting multiple judgements is the combination stage, aggregation. Existing methods in NLP either assign equal weight to all LLM judgments or are designed for specific tasks such as hallucination detection. This work focuses on aggregating predictions from multiple systems where no reference labels are available. A new method called SkillAggregation is proposed, which learns to combine estimates from LLM judges without needing additional data or ground truth. It extends the Crowdlayer aggregation method, developed for image classification, to exploit the judge estimates during inference. The approach is compared to a range of standard aggregation methods on HaluEval-Dialogue, TruthfulQA and Chatbot Arena tasks. SkillAggregation outperforms Crowdlayer on all tasks, and yields the best performance over all approaches on the majority of tasks.
Finetuning LLMs for Comparative Assessment Tasks
Sep 24, 2024



Automated assessment in natural language generation is a challenging task. Instruction-tuned large language models (LLMs) have shown promise in reference-free evaluation, particularly through comparative assessment. However, the quadratic computational complexity of pairwise comparisons limits its scalability. To address this, efficient comparative assessment has been explored by applying comparative strategies on zero-shot LLM probabilities. We propose a framework for finetuning LLMs for comparative assessment to align the model's output with the target distribution of comparative probabilities. By training on soft probabilities, our approach improves state-of-the-art performance while maintaining high performance with an efficient subset of comparisons.
ASR Error Correction using Large Language Models
Sep 14, 2024Error correction (EC) models play a crucial role in refining Automatic Speech Recognition (ASR) transcriptions, enhancing the readability and quality of transcriptions. Without requiring access to the underlying code or model weights, EC can improve performance and provide domain adaptation for black-box ASR systems. This work investigates the use of large language models (LLMs) for error correction across diverse scenarios. 1-best ASR hypotheses are commonly used as the input to EC models. We propose building high-performance EC models using ASR N-best lists which should provide more contextual information for the correction process. Additionally, the generation process of a standard EC model is unrestricted in the sense that any output sequence can be generated. For some scenarios, such as unseen domains, this flexibility may impact performance. To address this, we introduce a constrained decoding approach based on the N-best list or an ASR lattice. Finally, most EC models are trained for a specific ASR system requiring retraining whenever the underlying ASR system is changed. This paper explores the ability of EC models to operate on the output of different ASR systems. This concept is further extended to zero-shot error correction using LLMs, such as ChatGPT. Experiments on three standard datasets demonstrate the efficacy of our proposed methods for both Transducer and attention-based encoder-decoder ASR systems. In addition, the proposed method can serve as an effective method for model ensembling.
Controlling Whisper: Universal Acoustic Adversarial Attacks to Control Speech Foundation Models
Jul 05, 2024



Speech enabled foundation models, either in the form of flexible speech recognition based systems or audio-prompted large language models (LLMs), are becoming increasingly popular. One of the interesting aspects of these models is their ability to perform tasks other than automatic speech recognition (ASR) using an appropriate prompt. For example, the OpenAI Whisper model can perform both speech transcription and speech translation. With the development of audio-prompted LLMs there is the potential for even greater control options. In this work we demonstrate that with this greater flexibility the systems can be susceptible to model-control adversarial attacks. Without any access to the model prompt it is possible to modify the behaviour of the system by appropriately changing the audio input. To illustrate this risk, we demonstrate that it is possible to prepend a short universal adversarial acoustic segment to any input speech signal to override the prompt setting of an ASR foundation model. Specifically, we successfully use a universal adversarial acoustic segment to control Whisper to always perform speech translation, despite being set to perform speech transcription. Overall, this work demonstrates a new form of adversarial attack on multi-tasking speech enabled foundation models that needs to be considered prior to the deployment of this form of model.
Cross-Lingual Transfer Learning for Speech Translation
Jul 01, 2024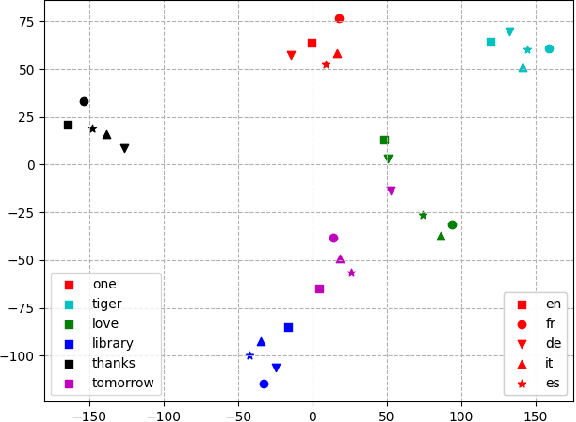



There has been increasing interest in building multilingual foundation models for NLP and speech research. Zero-shot cross-lingual transfer has been demonstrated on a range of NLP tasks where a model fine-tuned on task-specific data in one language yields performance gains in other languages. Here, we explore whether speech-based models exhibit the same transfer capability. Using Whisper as an example of a multilingual speech foundation model, we examine the utterance representation generated by the speech encoder. Despite some language-sensitive information being preserved in the audio embedding, words from different languages are mapped to a similar semantic space, as evidenced by a high recall rate in a speech-to-speech retrieval task. Leveraging this shared embedding space, zero-shot cross-lingual transfer is demonstrated in speech translation. When the Whisper model is fine-tuned solely on English-to-Chinese translation data, performance improvements are observed for input utterances in other languages. Additionally, experiments on low-resource languages show that Whisper can perform speech translation for utterances from languages unseen during pre-training by utilizing cross-lingual representations.
CrossCheckGPT: Universal Hallucination Ranking for Multimodal Foundation Models
May 22, 2024Multimodal foundation models are prone to hallucination, generating outputs that either contradict the input or are not grounded by factual information. Given the diversity in architectures, training data and instruction tuning techniques, there can be large variations in systems' susceptibility to hallucinations. To assess system hallucination robustness, hallucination ranking approaches have been developed for specific tasks such as image captioning, question answering, summarization, or biography generation. However, these approaches typically compare model outputs to gold-standard references or labels, limiting hallucination benchmarking for new domains. This work proposes "CrossCheckGPT", a reference-free universal hallucination ranking for multimodal foundation models. The core idea of CrossCheckGPT is that the same hallucinated content is unlikely to be generated by different independent systems, hence cross-system consistency can provide meaningful and accurate hallucination assessment scores. CrossCheckGPT can be applied to any model or task, provided that the information consistency between outputs can be measured through an appropriate distance metric. Focusing on multimodal large language models that generate text, we explore two information consistency measures: CrossCheck-explicit and CrossCheck-implicit. We showcase the applicability of our method for hallucination ranking across various modalities, namely the text, image, and audio-visual domains. Further, we propose the first audio-visual hallucination benchmark, "AVHalluBench", and illustrate the effectiveness of CrossCheckGPT, achieving correlations of 98% and 89% with human judgements on MHaluBench and AVHalluBench, respectively.
Question-Based Retrieval using Atomic Units for Enterprise RAG
May 20, 2024Enterprise retrieval augmented generation (RAG) offers a highly flexible framework for combining powerful large language models (LLMs) with internal, possibly temporally changing, documents. In RAG, documents are first chunked. Relevant chunks are then retrieved for a specific user query, which are passed as context to a synthesizer LLM to generate the query response. However, the retrieval step can limit performance, as incorrect chunks can lead the synthesizer LLM to generate a false response. This work proposes a zero-shot adaptation of standard dense retrieval steps for more accurate chunk recall. Specifically, a chunk is first decomposed into atomic statements. A set of synthetic questions are then generated on these atoms (with the chunk as the context). Dense retrieval involves finding the closest set of synthetic questions, and associated chunks, to the user query. It is found that retrieval with the atoms leads to higher recall than retrieval with chunks. Further performance gain is observed with retrieval using the synthetic questions generated over the atoms. Higher recall at the retrieval step enables higher performance of the enterprise LLM using the RAG pipeline.