 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Transfer Learning for Speech Translation
Paper and Code
Jul 01, 2024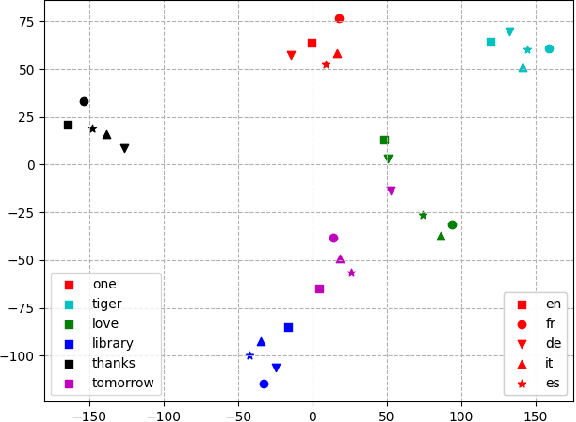



There has been increasing interest in building multilingual foundation models for NLP and speech research. Zero-shot cross-lingual transfer has been demonstrated on a range of NLP tasks where a model fine-tuned on task-specific data in one language yields performance gains in other languages. Here, we explore whether speech-based models exhibit the same transfer capability. Using Whisper as an example of a multilingual speech foundation model, we examine the utterance representation generated by the speech encoder. Despite some language-sensitive information being preserved in the audio embedding, words from different languages are mapped to a similar semantic space, as evidenced by a high recall rate in a speech-to-speech retrieval task. Leveraging this shared embedding space, zero-shot cross-lingual transfer is demonstrated in speech translation. When the Whisper model is fine-tuned solely on English-to-Chinese translation data, performance improvements are observed for input utterances in other languages. Additionally, experiments on low-resource languages show that Whisper can perform speech translation for utterances from languages unseen during pre-training by utilizing cross-lingual representations.