 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Be Multimodal or Not to Be: Query-Adaptive Audio-Visual Person Retrieval via Active Modality Detection
Jun 04, 2026When retrieving a person from a video archive by voice and face, should the system be multimodal or not? In real-world broadcast archives, unlike curated benchmarks, a target may be heard but unseen, seen but unheard, or both. Fusing scores from an absent modality injects noise, degrading precision below the best unimodal system. We propose a query-adaptive framework that detects active modalities via cross-modal score consistency: when both modalities are active, files retrieved by one also score highly on the other; this agreement breaks down when a modality is absent. Classifiers driven by these cross-modal features achieve 89% detection accuracy. On the BBC Rewind corpus (with over 12,000 broadcast videos) the adaptive system attains 94.2% P@1, outperforming speaker-only (82.9%), face-only (93.4%), and fixed fusion (90.0%), recovering 64% of the gap to an oracle with ground-truth modality labels (96.6%).
The Impact of Editorial Intervention on Detecting Native Language Traces
May 11, 2026Native Language Identification (NLI) is the task of determining an author's native language (L1) from their non-native writings. With the advent of human-AI co-authorship, non-native texts are routinely corrected and rewritten by large language models, fundamentally altering the linguistic features NLI models depend on. In this paper, we investigate the robustness of L1 traces across increasing degrees of editorial intervention. By processing 450 essays from the Write & Improve 2024 corpus through varying levels of grammatical error correction (GEC) and paraphrasing, we demonstrate that L1 attribution does not entirely depend on surface-level errors. Instead, the detection models leverage deeper L1 features: unidiomatic lexico-semantic choices, pragmatic transfer, and the author's underlying cultural perspective. We find that minimal edits preserve these structural traces and maintain high profiling accuracy. In contrast, fluency edits and paraphrasing normalize these L1 features, leading to a severe degradation in performance.
Towards Self-Referential Analytic Assessment: A Profile-Based Approach to L2 Writing Evaluation with LLMs
May 05, 2026Automated essay scoring (AES) research often relies on rank-based correlation metrics to validate analytic assessment. However, such metrics obscure both intrinsic intercorrelations among analytic dimensions that arise from the structure of writing proficiency itself and halo effects, whereby holistic impressions bleed into fine-grained component scores. As a result, high correlations may mask a system's true diagnostic behaviour. In this study, we propose a novel self-referential assessment evaluation framework that focuses on identifying intra-learner strengths and weaknesses rather than assessing inter-learner rankings. We conduct experiments on the publicly available ICNALE GRA, a uniquely dense second-language writing dataset annotated holistically and analytically by up to 80 trained raters. To obtain reliable reference scores, we apply two-facet Rasch modelling to calibrate rater severity and derive fair average scores across ten analytic aspects and holistic proficiency. We compare the analytic scoring performance of human operational raters and three large language models (LLMs) in a zero-shot setting. Our results show that LLMs tend to outperform single human raters in identifying relative weaknesses (negative feedback) across several proficiency aspects, while human raters remain stronger at identifying relative strengths (positive feedback). Overall, our findings highlight the limitations of rank-based evaluation for analytic assessment and demonstrate the value of intra-learner, profile-based methods for assessing and deploying LLMs in AES.
Dual-Space Knowledge Distillation with Key-Query Matching for Large Language Models with Vocabulary Mismatch
Mar 23, 2026Large language models (LLMs) achieve state-of-the-art (SOTA) performance across language tasks, but are costly to deploy due to their size and resource demands. Knowledge Distillation (KD) addresses this by training smaller Student models to mimic larger Teacher models, improving efficiency without significant performance loss. Dual-Space Knowledge Distillation with Cross-Model Attention (DSKD-CMA) has emerged as a SOTA method for KD between LLMs with distinct tokenizers, yet its internal workings remain largely opaque. In this work, we systematically analyse the attention mechanism of DSKD-CMA through manual token alignment probing and heatmap visualisations, revealing both strengths and limitations. Building on this, we introduce a novel method, DSKD-CMA-GA, based on Generative Adversarial (GA) learning, to address the mismatched distributions between the keys and queries computed from distinct models. Experiments show modest but consistent ROUGE-L gains in text generation quality, particularly on out-of-distribution data (+0.37 on average), narrowing the gap between cross- and same-tokenizer KD.
Exploiting the English Grammar Profile for L2 grammatical analysis with LLMs
Mar 17, 2026Evaluating the grammatical competence of second language (L2) learners is essential both for providing targeted feedback and for assessing proficiency. To achieve this, we propose a novel framework leveraging the English Grammar Profile (EGP), a taxonomy of grammatical constructs mapped to the proficiency levels of the Common European Framework of Reference (CEFR), to detect learners' attempts at grammatical constructs and classify them as successful or unsuccessful. This detection can then be used to provide fine-grained feedback. Moreover, the grammatical constructs are used as predictors of proficiency assessment by using automatically detected attempts as predictors of holistic CEFR proficiency. For the selection of grammatical constructs derived from the EGP, rule-based and LLM-based classifiers are compared. We show that LLMs outperform rule-based methods on semantically and pragmatically nuanced constructs, while rule-based approaches remain competitive for constructs that rely purely on morphological or syntactic features and do not require semantic interpretation. For proficiency assessment, we evaluate both rule-based and hybrid pipelines and show that a hybrid approach combining a rule-based pre-filter with an LLM consistently yields the strongest performance. Since our framework operates on pairs of original learner sentences and their corrected counterparts, we also evaluate a fully automated pipeline using automatic grammatical error correction. This pipeline closely approaches the performance of semi-automated systems based on manual corrections, particularly for the detection of successful attempts at grammatical constructs. Overall, our framework emphasises learners' successful attempts in addition to unsuccessful ones, enabling positive, formative feedback and providing actionable insights into grammatical development.
Detect, Attend and Extract: Keyword Guided Target Speaker Extraction
Feb 08, 2026Target speaker extraction (TSE) aims to extract the speech of a target speaker from mixtures containing multiple competing speakers. Conventional TSE systems predominantly rely on speaker cues, such as pre-enrolled speech, to identify and isolate the target speaker. However, in many practical scenarios, clean enrollment utterances are unavailable, limiting the applicability of existing approaches. In this work, we propose DAE-TSE, a keyword-guided TSE framework that specifies the target speaker through distinct keywords they utter. By leveraging keywords (i.e., partial transcriptions) as cues, our approach provides a flexible and practical alternative to enrollment-based TSE. DAE-TSE follows the Detect-Attend-Extract (DAE) paradigm: it first detects the presence of the given keywords, then attends to the corresponding speaker based on the keyword content, and finally extracts the target speech. Experimental results demonstrate that DAE-TSE outperforms standard TSE systems that rely on clean enrollment speech. To the best of our knowledge, this is the first study to utilize partial transcription as a cue for specifying the target speaker in TSE, offering a flexible and practical solution for real-world scenarios. Our code and demo page are now publicly available.
Effectiveness of Chain-of-Thought in Distilling Reasoning Capability from Large Language Models
Nov 07, 2025Chain-of-Thought (CoT) prompting is a widely used method to improve the reasoning capability of Large Language Models (LLMs). More recently, CoT has been leveraged in Knowledge Distillation (KD) to transfer reasoning capability from a larger LLM to a smaller one. This paper examines the role of CoT in distilling the reasoning capability from larger LLMs to smaller LLMs using white-box KD, analysing its effectiveness in improving the performance of the distilled models for various natural language reasoning and understanding tasks. We conduct white-box KD experiments using LLMs from the Qwen and Llama2 families, employing CoT data from the CoT-Collection dataset. The distilled models are then evaluated on natural language reasoning and understanding tasks from the BIG-Bench-Hard (BBH) benchmark, which presents complex challenges for smaller LLMs. Experimental results demonstrate the role of CoT in improving white-box KD effectiveness, enabling the distilled models to achieve better average performance in natural language reasoning and understanding tasks from BBH.
Universal Acoustic Adversarial Attacks for Flexible Control of Speech-LLMs
May 20, 2025The combination of pre-trained speech encoders with large language models has enabled the development of speech LLMs that can handle a wide range of spoken language processing tasks. While these models are powerful and flexible, this very flexibility may make them more vulnerable to adversarial attacks. To examine the extent of this problem, in this work we investigate universal acoustic adversarial attacks on speech LLMs. Here a fixed, universal, adversarial audio segment is prepended to the original input audio. We initially investigate attacks that cause the model to either produce no output or to perform a modified task overriding the original prompt. We then extend the nature of the attack to be selective so that it activates only when specific input attributes, such as a speaker gender or spoken language, are present. Inputs without the targeted attribute should be unaffected, allowing fine-grained control over the model outputs. Our findings reveal critical vulnerabilities in Qwen2-Audio and Granite-Speech and suggest that similar speech LLMs may be susceptible to universal adversarial attacks. This highlights the need for more robust training strategies and improved resistance to adversarial attacks.
Speaker Retrieval in the Wild: Challenges, Effectiveness and Robustness
Apr 29, 2025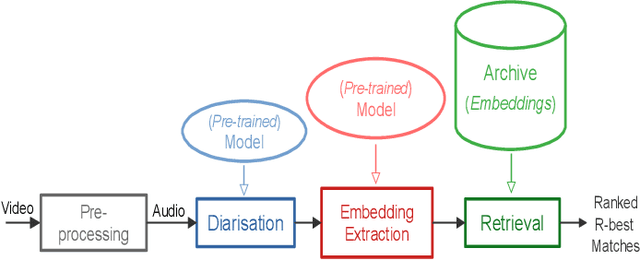
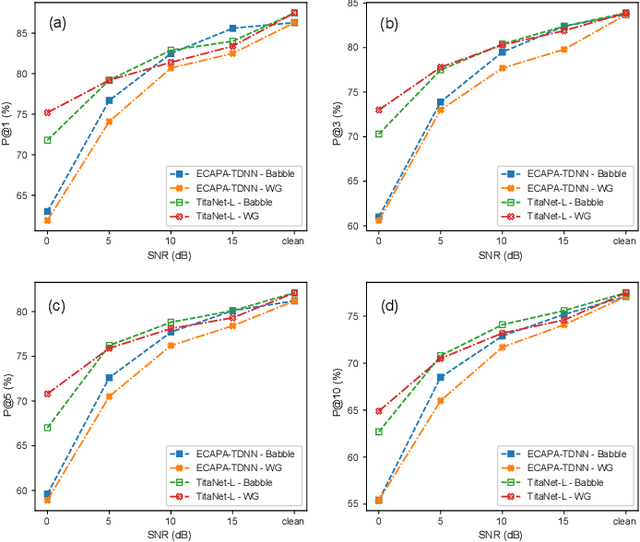
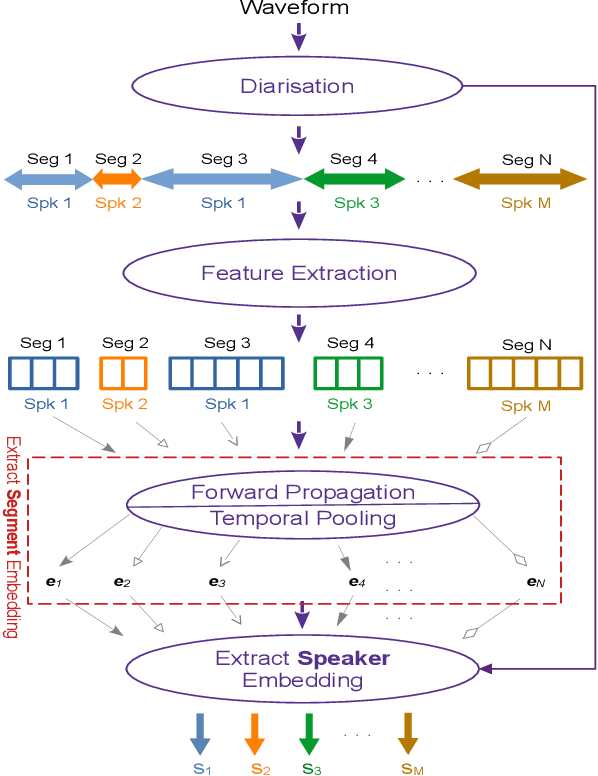
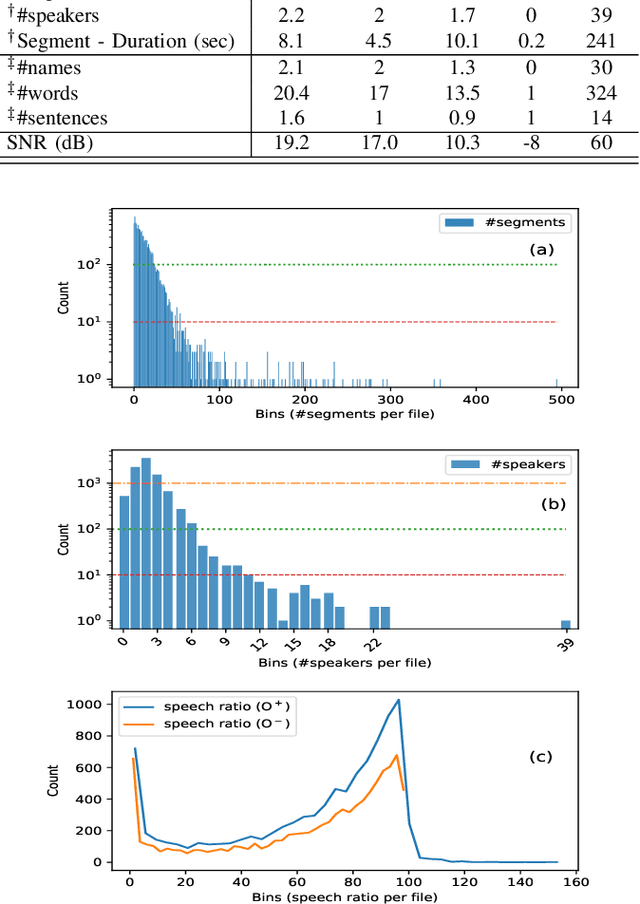
There is a growing abundance of publicly available or company-owned audio/video archives, highlighting the increasing importance of efficient access to desired content and information retrieval from these archives. This paper investigates the challenges, solutions, effectiveness, and robustness of speaker retrieval systems developed "in the wild" which involves addressing two primary challenges: extraction of task-relevant labels from limited metadata for system development and evaluation, as well as the unconstrained acoustic conditions encountered in the archive, ranging from quiet studios to adverse noisy environments. While we focus on the publicly-available BBC Rewind archive (spanning 1948 to 1979), our framework addresses the broader issue of speaker retrieval on extensive and possibly aged archives with no control over the content and acoustic conditions. Typically, these archives offer a brief and general file description, mostly inadequate for specific applications like speaker retrieval, and manual annotation of such large-scale archives is unfeasible. We explore various aspects of system development (e.g., speaker diarisation, embedding extraction, query selection) and analyse the challenges, possible solutions, and their functionality. To evaluate the performance, we conduct systematic experiments in both clean setup and against various distortions simulating real-world applications. Our findings demonstrate the effectiveness and robustness of the developed speaker retrieval systems, establishing the versatility and scalability of the proposed framework for a wide range of applications beyond the BBC Rewind corpus.
Speak & Improve Challenge 2025: Tasks and Baseline Systems
Dec 17, 2024



This paper presents the "Speak & Improve Challenge 2025: Spoken Language Assessment and Feedback" -- a challenge associated with the ISCA SLaTE 2025 Workshop. The goal of the challenge is to advance research on spoken language assessment and feedback, with tasks associated with both the underlying technology and language learning feedback. Linked with the challenge, the Speak & Improve (S&I) Corpus 2025 is being pre-released, a dataset of L2 learner English data with holistic scores and language error annotation, collected from open (spontaneous) speaking tests on the Speak & Improve learning platform. The corpus consists of approximately 315 hours of audio data from second language English learners with holistic scores, and a 55-hour subset with manual transcriptions and error labels. The Challenge has four shared tasks: Automatic Speech Recognition (ASR), Spoken Language Assessment (SLA), Spoken Grammatical Error Correction (SGEC), and Spoken Grammatical Error Correction Feedback (SGECF). Each of these tasks has a closed track where a predetermined set of models and data sources are allowed to be used, and an open track where any public resource may be used. Challenge participants may do one or more of the tasks. This paper describes the challenge, the S&I Corpus 2025, and the baseline systems released for the Challenge.