 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho can we trust? LLM-as-a-jury for Comparative Assessment
Feb 18, 2026Large language models (LLMs) are increasingly applied as automatic evaluators for natural language generation assessment often using pairwise comparative judgements. Existing approaches typically rely on single judges or aggregate multiple judges assuming equal reliability. In practice, LLM judges vary substantially in performance across tasks and aspects, and their judgment probabilities may be biased and inconsistent. Furthermore, human-labelled supervision for judge calibration may be unavailable. We first empirically demonstrate that inconsistencies in LLM comparison probabilities exist and show that it limits the effectiveness of direct probability-based ranking. To address this, we study the LLM-as-a-jury setting and propose BT-sigma, a judge-aware extension of the Bradley-Terry model that introduces a discriminator parameter for each judge to jointly infer item rankings and judge reliability from pairwise comparisons alone. Experiments on benchmark NLG evaluation datasets show that BT-sigma consistently outperforms averaging-based aggregation methods, and that the learned discriminator strongly correlates with independent measures of the cycle consistency of LLM judgments. Further analysis reveals that BT-sigma can be interpreted as an unsupervised calibration mechanism that improves aggregation by modelling judge reliability.
Assessment of L2 Oral Proficiency using Speech Large Language Models
May 27, 2025


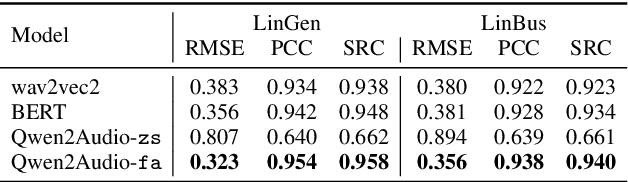
The growing population of L2 English speakers has increased the demand for developing automatic graders for spoken language assessment (SLA). Historically, statistical models, text encoders, and self-supervised speech models have been utilised for this task. However, cascaded systems suffer from the loss of information, while E2E graders also have limitations. With the recent advancements of multi-modal large language models (LLMs), we aim to explore their potential as L2 oral proficiency graders and overcome these issues. In this work, we compare various training strategies using regression and classification targets. Our results show that speech LLMs outperform all previous competitive baselines, achieving superior performance on two datasets. Furthermore, the trained grader demonstrates strong generalisation capabilities in the cross-part or cross-task evaluation, facilitated by the audio understanding knowledge acquired during LLM pre-training.
Scaling and Prompting for Improved End-to-End Spoken Grammatical Error Correction
May 27, 2025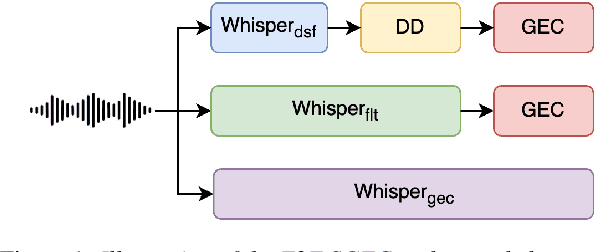
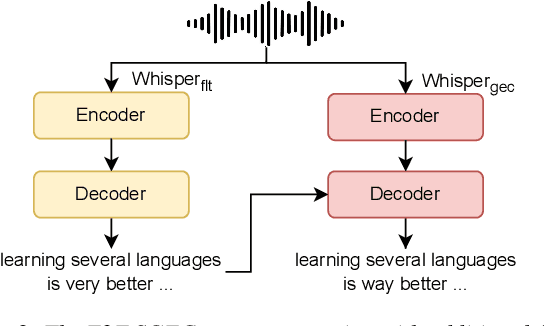
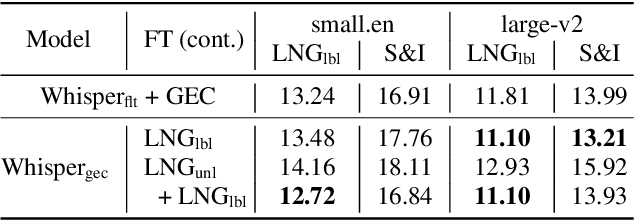
Spoken Grammatical Error Correction (SGEC) and Feedback (SGECF) are crucial for second language learners, teachers and test takers. Traditional SGEC systems rely on a cascaded pipeline consisting of an ASR, a module for disfluency detection (DD) and removal and one for GEC. With the rise of end-to-end (E2E) speech foundation models, we investigate their effectiveness in SGEC and feedback generation. This work introduces a pseudo-labelling process to address the challenge of limited labelled data, expanding the training data size from 77 hours to approximately 2500 hours, leading to improved performance. Additionally, we prompt an E2E Whisper-based SGEC model with fluent transcriptions, showing a slight improvement in SGEC performance, with more significant gains in feedback generation. Finally, we assess the impact of increasing model size, revealing that while pseudo-labelled data does not yield performance gain for a larger Whisper model, training with prompts proves beneficial.
Training Articulatory Inversion Models for Inter-Speaker Consistency
May 26, 2025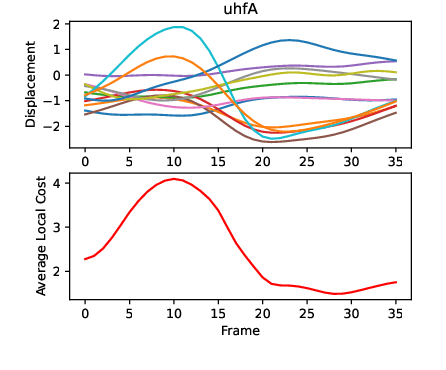



Acoustic-to-Articulatory Inversion (AAI) attempts to model the inverse mapping from speech to articulation. Exact articulatory prediction from speech alone may be impossible, as speakers can choose different forms of articulation seemingly without reference to their vocal tract structure. However, once a speaker has selected an articulatory form, their productions vary minimally. Recent works in AAI have proposed adapting Self-Supervised Learning (SSL) models to single-speaker datasets, claiming that these single-speaker models provide a universal articulatory template. In this paper, we investigate whether SSL-adapted models trained on single and multi-speaker data produce articulatory targets which are consistent across speaker identities for English and Russian. We do this through the use of a novel evaluation method which extracts articulatory targets using minimal pair sets. We also present a training method which can improve inter-speaker consistency using only speech data.
Generalised Probabilistic Modelling and Improved Uncertainty Estimation in Comparative LLM-as-a-judge
May 21, 2025



This paper explores generalised probabilistic modelling and uncertainty estimation in comparative LLM-as-a-judge frameworks. We show that existing Product-of-Experts methods are specific cases of a broader framework, enabling diverse modelling options. Furthermore, we propose improved uncertainty estimates for individual comparisons, enabling more efficient selection and achieving strong performance with fewer evaluations. We also introduce a method for estimating overall ranking uncertainty. Finally, we demonstrate that combining absolute and comparative scoring improves performance. Experiments show that the specific expert model has a limited impact on final rankings but our proposed uncertainty estimates, especially the probability of reordering, significantly improve the efficiency of systems reducing the number of needed comparisons by ~50%. Furthermore, ranking-level uncertainty metrics can be used to identify low-performing predictions, where the nature of the probabilistic model has a notable impact on the quality of the overall uncertainty.
Speak & Improve Corpus 2025: an L2 English Speech Corpus for Language Assessment and Feedback
Dec 17, 2024We introduce the Speak & Improve Corpus 2025, a dataset of L2 learner English data with holistic scores and language error annotation, collected from open (spontaneous) speaking tests on the Speak & Improve learning platform. The aim of the corpus release is to address a major challenge to developing L2 spoken language processing systems, the lack of publicly available data with high-quality annotations. It is being made available for non-commercial use on the ELiT website. In designing this corpus we have sought to make it cover a wide-range of speaker attributes, from their L1 to their speaking ability, as well as providing manual annotations. This enables a range of language-learning tasks to be examined, such as assessing speaking proficiency or providing feedback on grammatical errors in a learner's speech. Additionally the data supports research into the underlying technology required for these tasks including automatic speech recognition (ASR) of low resource L2 learner English, disfluency detection or spoken grammatical error correction (GEC). The corpus consists of around 315 hours of L2 English learners audio with holistic scores, and a subset of audio annotated with transcriptions and error labels.
Speak & Improve Challenge 2025: Tasks and Baseline Systems
Dec 17, 2024



This paper presents the "Speak & Improve Challenge 2025: Spoken Language Assessment and Feedback" -- a challenge associated with the ISCA SLaTE 2025 Workshop. The goal of the challenge is to advance research on spoken language assessment and feedback, with tasks associated with both the underlying technology and language learning feedback. Linked with the challenge, the Speak & Improve (S&I) Corpus 2025 is being pre-released, a dataset of L2 learner English data with holistic scores and language error annotation, collected from open (spontaneous) speaking tests on the Speak & Improve learning platform. The corpus consists of approximately 315 hours of audio data from second language English learners with holistic scores, and a 55-hour subset with manual transcriptions and error labels. The Challenge has four shared tasks: Automatic Speech Recognition (ASR), Spoken Language Assessment (SLA), Spoken Grammatical Error Correction (SGEC), and Spoken Grammatical Error Correction Feedback (SGECF). Each of these tasks has a closed track where a predetermined set of models and data sources are allowed to be used, and an open track where any public resource may be used. Challenge participants may do one or more of the tasks. This paper describes the challenge, the S&I Corpus 2025, and the baseline systems released for the Challenge.
Grammatical Error Feedback: An Implicit Evaluation Approach
Aug 18, 2024Grammatical feedback is crucial for consolidating second language (L2) learning. Most research in computer-assisted language learning has focused on feedback through grammatical error correction (GEC) systems, rather than examining more holistic feedback that may be more useful for learners. This holistic feedback will be referred to as grammatical error feedback (GEF). In this paper, we present a novel implicit evaluation approach to GEF that eliminates the need for manual feedback annotations. Our method adopts a grammatical lineup approach where the task is to pair feedback and essay representations from a set of possible alternatives. This matching process can be performed by appropriately prompting a large language model (LLM). An important aspect of this process, explored here, is the form of the lineup, i.e., the selection of foils. This paper exploits this framework to examine the quality and need for GEC to generate feedback, as well as the system used to generate feedback, using essays from the Cambridge Learner Corpus.
Learn and Don't Forget: Adding a New Language to ASR Foundation Models
Jul 09, 2024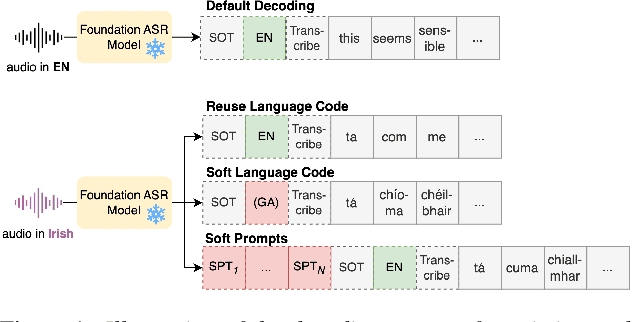
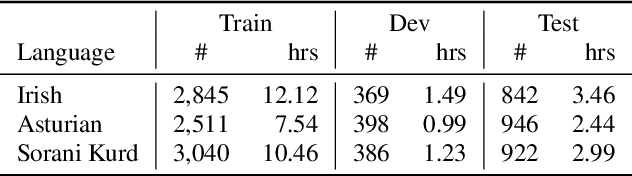
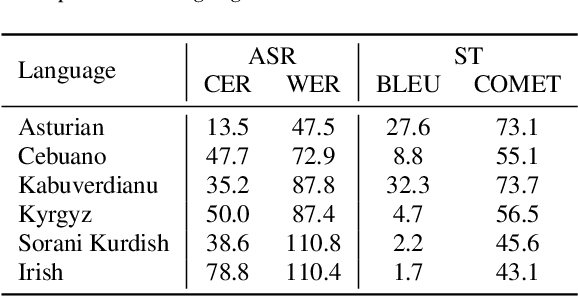
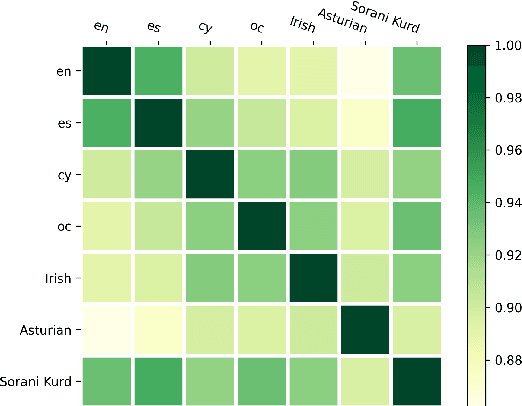
Foundation ASR models often support many languages, e.g. 100 languages in Whisper. However, there has been limited work on integrating an additional, typically low-resource, language, while maintaining performance on the original language set. Fine-tuning, while simple, may degrade the accuracy of the original set. We compare three approaches that exploit adaptation parameters: soft language code tuning, train only the language code; soft prompt tuning, train prepended tokens; and LoRA where a small set of additional parameters are optimised. Elastic Weight Consolidation (EWC) offers an alternative compromise with the potential to maintain performance in specific target languages. Results show that direct fine-tuning yields the best performance for the new language but degrades existing language capabilities. EWC can address this issue for specific languages. If only adaptation parameters are used, the language capabilities are maintained but at the cost of performance in the new language.
Efficient Sample-Specific Encoder Perturbations
May 01, 2024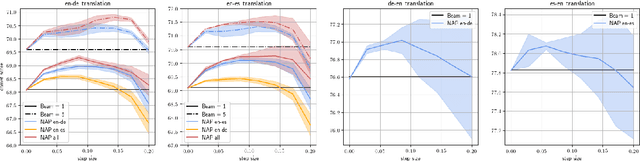



Encoder-decoder foundation models have displayed state-of-the-art performance on a range of autoregressive sequence tasks. This paper proposes a simple and lightweight modification to such systems to control the behaviour according to a specific attribute of interest. This paper proposes a novel inference-efficient approach to modifying the behaviour of an encoder-decoder system according to a specific attribute of interest. Specifically, we show that a small proxy network can be used to find a sample-by-sample perturbation of the encoder output of a frozen foundation model to trigger the decoder to generate improved decodings. This work explores a specific realization of this framework focused on improving the COMET performance of Flan-T5 on Machine Translation and the WER of Whisper foundation models on Speech Recognition. Results display consistent improvements in performance evaluated through COMET and WER respectively. Furthermore, experiments also show that the proxies are robust to the exact nature of the data used to train them and can extend to other domains.