 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan GPT-4 do L2 analytic assessment?
Apr 29, 2024Automated essay scoring (AES) to evaluate second language (L2) proficiency has been a firmly established technology used in educational contexts for decades. Although holistic scoring has seen advancements in AES that match or even exceed human performance, analytic scoring still encounters issues as it inherits flaws and shortcomings from the human scoring process. The recent introduction of large language models presents new opportunities for automating the evaluation of specific aspects of L2 writing proficiency. In this paper, we perform a series of experiments using GPT-4 in a zero-shot fashion on a publicly available dataset annotated with holistic scores based on the Common European Framework of Reference and aim to extract detailed information about their underlying analytic components. We observe significant correlations between the automatically predicted analytic scores and multiple features associated with the individual proficiency components.
The IWSLT 2021 BUT Speech Translation Systems
Jul 13, 2021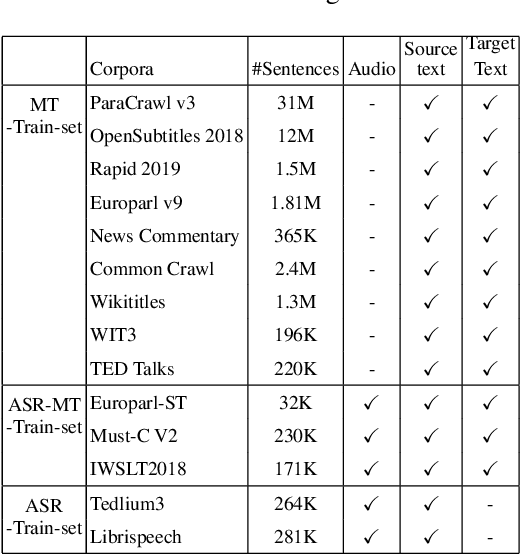
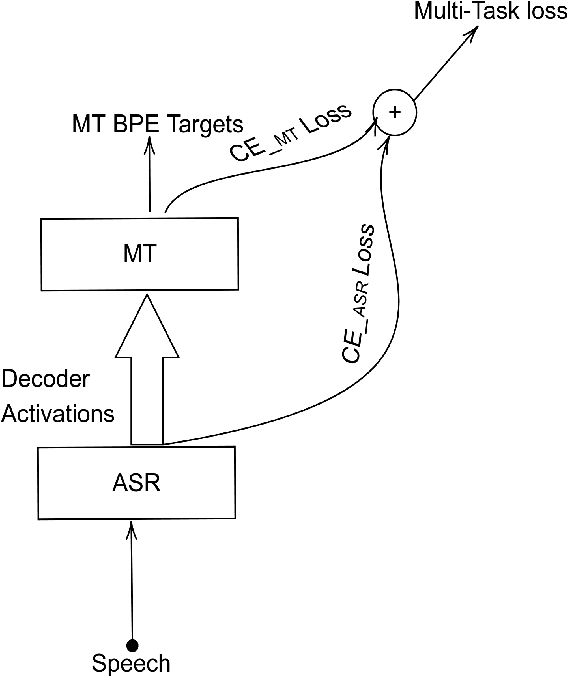
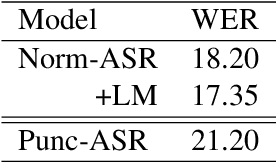
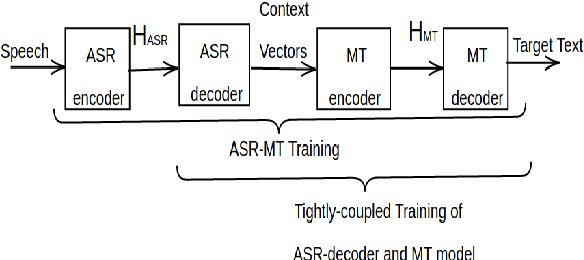
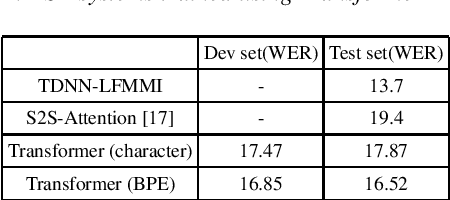
The paper describes BUT's English to German offline speech translation(ST) systems developed for IWSLT2021. They are based on jointly trained Automatic Speech Recognition-Machine Translation models. Their performances is evaluated on MustC-Common test set. In this work, we study their efficiency from the perspective of having a large amount of separate ASR training data and MT training data, and a smaller amount of speech-translation training data. Large amounts of ASR and MT training data are utilized for pre-training the ASR and MT models. Speech-translation data is used to jointly optimize ASR-MT models by defining an end-to-end differentiable path from speech to translations. For this purpose, we use the internal continuous representations from the ASR-decoder as the input to MT module. We show that speech translation can be further improved by training the ASR-decoder jointly with the MT-module using large amount of text-only MT training data. We also show significant improvements by training an ASR module capable of generating punctuated text, rather than leaving the punctuation task to the MT module.
A Technical Report: BUT Speech Translation Systems
Oct 22, 2020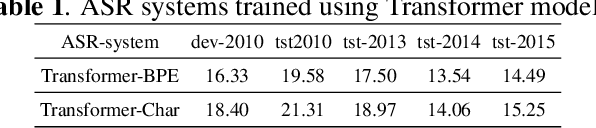
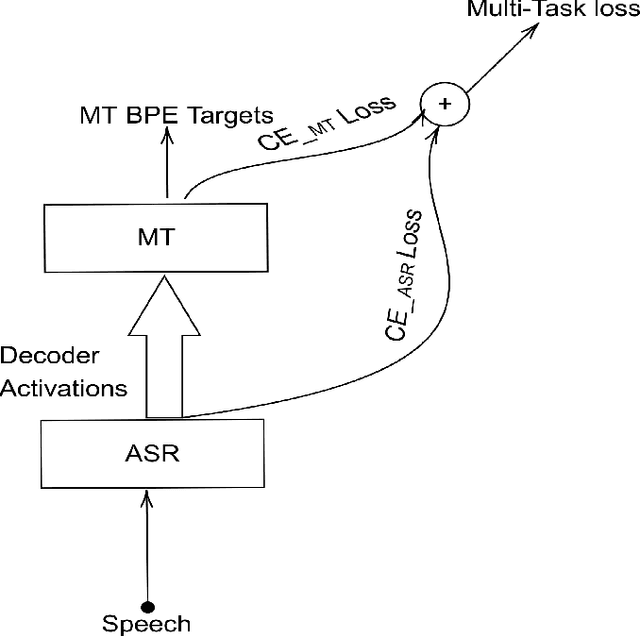
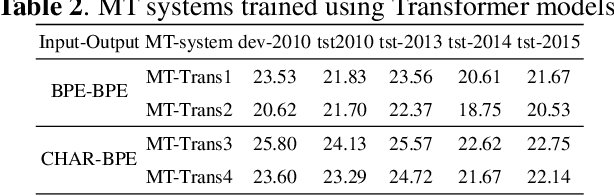
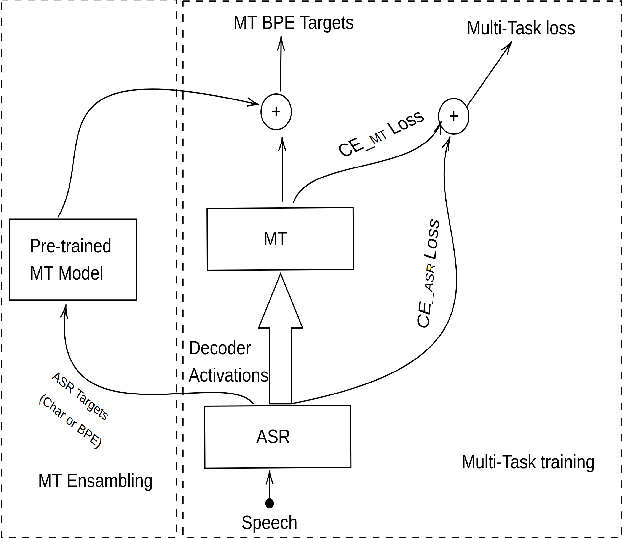
The paper describes the BUT's speech translation systems. The systems are English$\longrightarrow$German offline speech translation systems. The systems are based on our previous works \cite{Jointly_trained_transformers}. Though End-to-End and cascade~(ASR-MT) spoken language translation~(SLT) systems are reaching comparable performances, a large degradation is observed when translating ASR hypothesis compared to the oracle input text. To reduce this performance degradation, we have jointly-trained ASR and MT modules with ASR objective as an auxiliary loss. Both the networks are connected through the neural hidden representations. This model has an End-to-End differentiable path with respect to the final objective function and also utilizes the ASR objective for better optimization. During the inference both the modules(i.e., ASR and MT) are connected through the hidden representations corresponding to the n-best hypotheses. Ensembling with independently trained ASR and MT models have further improved the performance of the system.
Jointly Trained Transformers models for Spoken Language Translation
Apr 25, 2020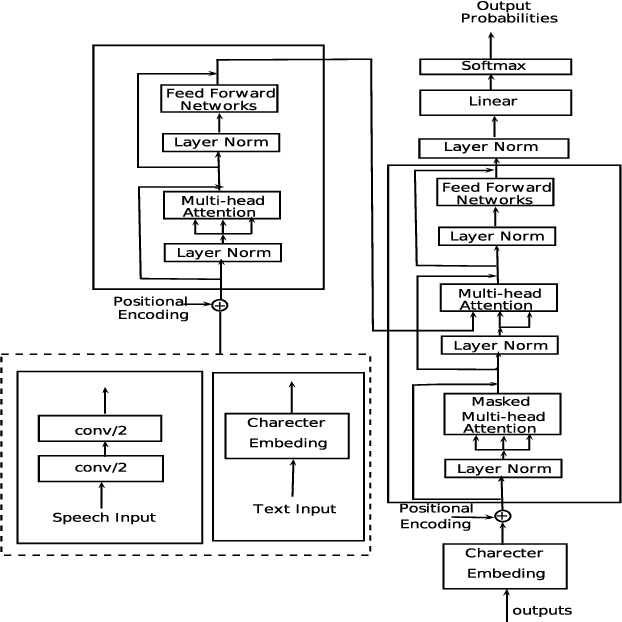
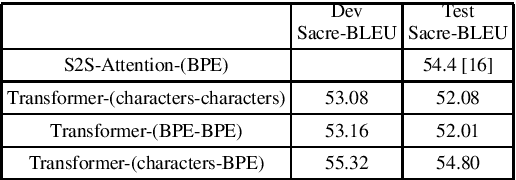
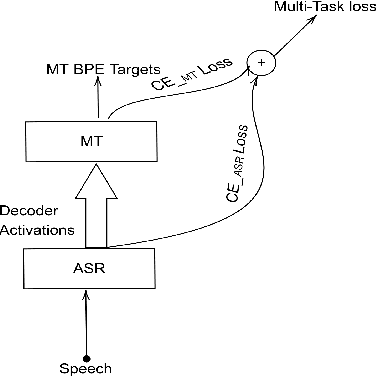
Conventional spoken language translation (SLT) systems are pipeline based systems, where we have an Automatic Speech Recognition (ASR) system to convert the modality of source from speech to text and a Machine Translation (MT) systems to translate source text to text in target language. Recent progress in the sequence-sequence architectures have reduced the performance gap between the pipeline based SLT systems (cascaded ASR-MT) and End-to-End approaches. Though End-to-End and cascaded ASR-MT systems are reaching to the comparable levels of performances, we can see a large performance gap using the ASR hypothesis and oracle text w.r.t MT models. This performance gap indicates that the MT systems are prone to large performance degradation due to noisy ASR hypothesis as opposed to oracle text transcript. In this work this degradation in the performance is reduced by creating an end to-end differentiable pipeline between the ASR and MT systems. In this work, we train SLT systems with ASR objective as an auxiliary loss and both the networks are connected through the neural hidden representations. This train ing would have an End-to-End differentiable path w.r.t to the final objective function as well as utilize the ASR objective for better performance of the SLT systems. This architecture has improved from BLEU from 36.8 to 44.5. Due to the Multi-task training the model also generates the ASR hypothesis which are used by a pre-trained MT model. Combining the proposed systems with the MT model has increased the BLEU score by 1. All the experiments are reported on English-Portuguese speech translation task using How2 corpus. The final BLEU score is on-par with the best speech translation system on How2 dataset with no additional training data and language model and much less parameters.
BUT Opensat 2019 Speech Recognition System
Jan 30, 2020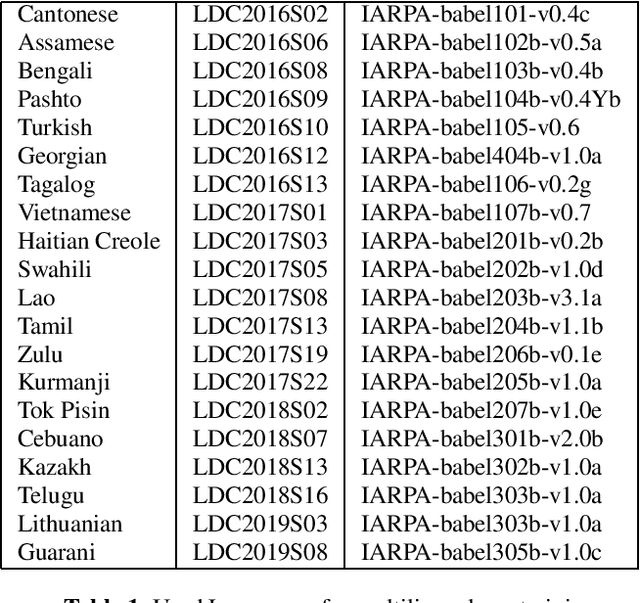


The paper describes the BUT Automatic Speech Recognition (ASR) systems submitted for OpenSAT evaluations under two domain categories such as low resourced languages and public safety communications. The first was challenging due to lack of training data, therefore various architectures and multilingual approaches were employed. The combination led to superior performance. The second domain was challenging due to recording in extreme conditions such as specific channel, speaker under stress and high levels of noise. Data augmentation process was inevitable to get reasonably good performance.
Bayesian Subspace Hidden Markov Model for Acoustic Unit Discovery
Apr 08, 2019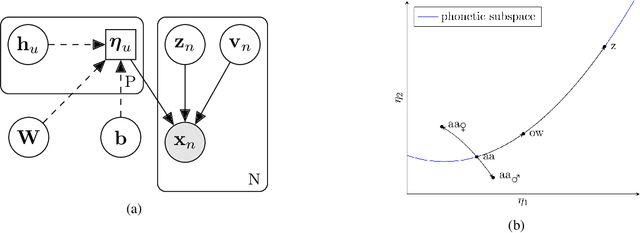
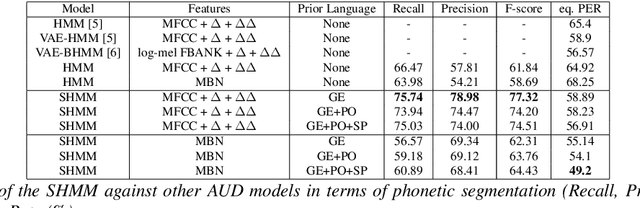
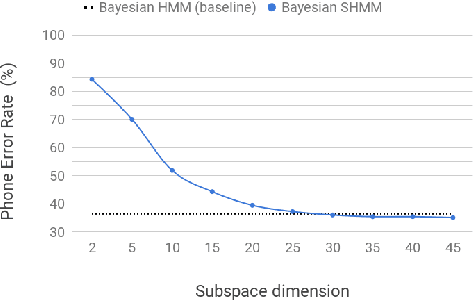
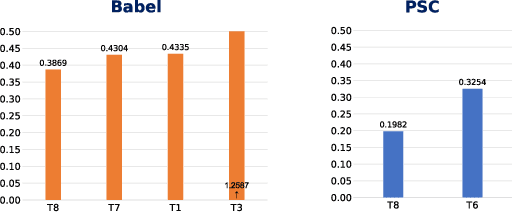
This work tackles the problem of learning a set of language specific acoustic units from unlabeled speech recordings given a set of labeled recordings from other languages. Our approach may be described by the following two steps procedure: first the model learns the notion of acoustic units from the labelled data and then the model uses its knowledge to find new acoustic units on the target language. We implement this process with the Bayesian Subspace Hidden Markov Model (SHMM), a model akin to the Subspace Gaussian Mixture Model (SGMM) where each low dimensional embedding represents an acoustic unit rather than just a HMM's state. The subspace is trained on 3 languages from the GlobalPhone corpus (German, Polish and Spanish) and the AUs are discovered on the TIMIT corpus. Results, measured in equivalent Phone Error Rate, show that this approach significantly outperforms previous HMM based acoustic units discovery systems and compares favorably with the Variational Auto Encoder-HMM.
A language model based approach towards large scale and lightweight language identification systems
Oct 13, 2015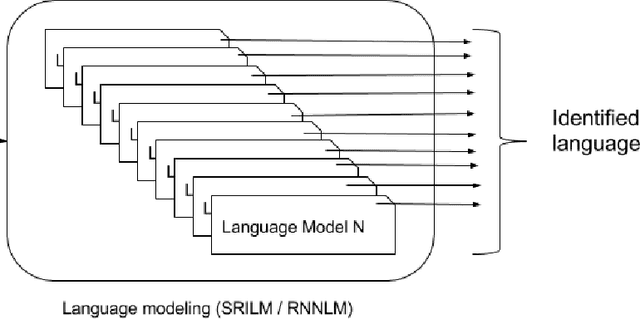
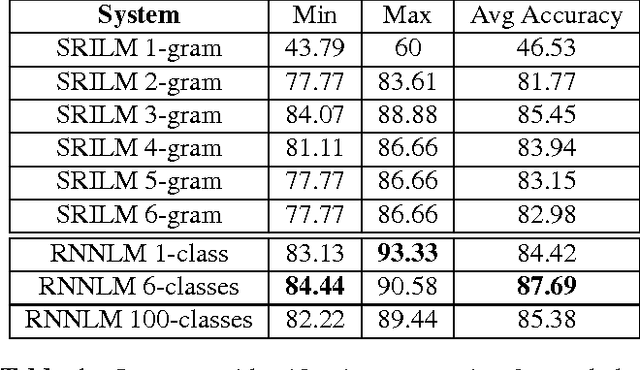
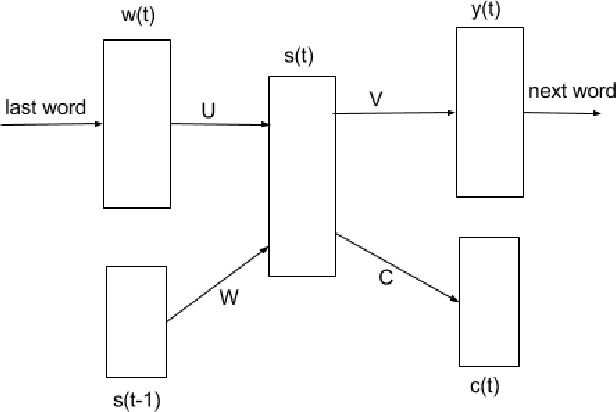
Multilingual spoken dialogue systems have gained prominence in the recent past necessitating the requirement for a front-end Language Identification (LID) system. Most of the existing LID systems rely on modeling the language discriminative information from low-level acoustic features. Due to the variabilities of speech (speaker and emotional variabilities, etc.), large-scale LID systems developed using low-level acoustic features suffer from a degradation in the performance. In this approach, we have attempted to model the higher level language discriminative phonotactic information for developing an LID system. In this paper, the input speech signal is tokenized to phone sequences by using a language independent phone recognizer. The language discriminative phonotactic information in the obtained phone sequences are modeled using statistical and recurrent neural network based language modeling approaches. As this approach, relies on higher level phonotactical information it is more robust to variabilities of speech. Proposed approach is computationally light weight, highly scalable and it can be used in complement with the existing LID systems.