 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUT CHiME-7 system description
Oct 18, 2023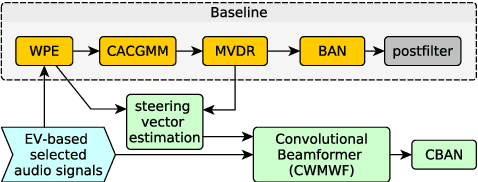
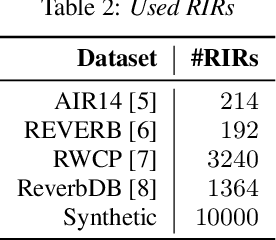
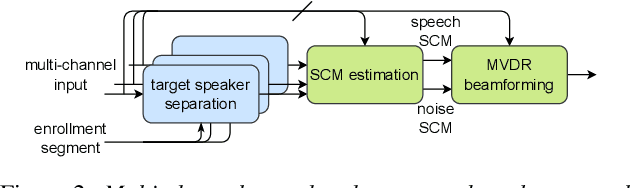
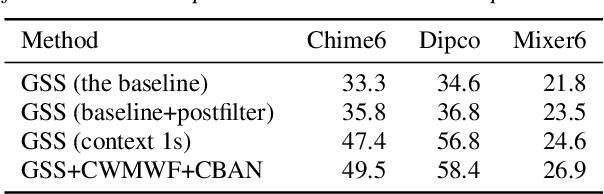
This paper describes the joint effort of Brno University of Technology (BUT), AGH University of Krakow and University of Buenos Aires on the development of Automatic Speech Recognition systems for the CHiME-7 Challenge. We train and evaluate various end-to-end models with several toolkits. We heavily relied on Guided Source Separation (GSS) to convert multi-channel audio to single channel. The ASR is leveraging speech representations from models pre-trained by self-supervised learning, and we do a fusion of several ASR systems. In addition, we modified external data from the LibriSpeech corpus to become a close domain and added it to the training. Our efforts were focused on the far-field acoustic robustness sub-track of Task 1 - Distant Automatic Speech Recognition (DASR), our systems use oracle segmentation.
BCN2BRNO: ASR System Fusion for Albayzin 2020 Speech to Text Challenge
Jan 29, 2021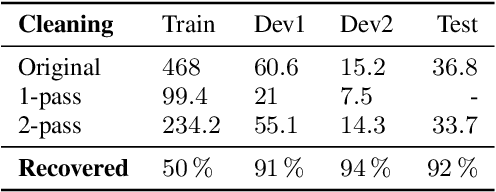
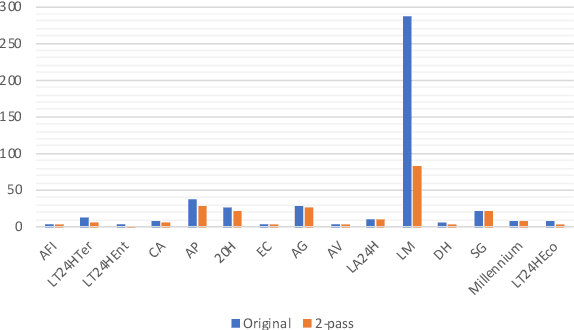
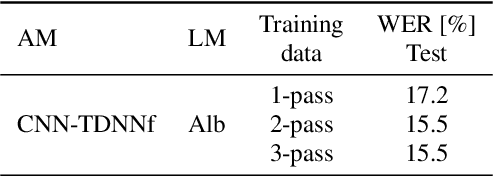
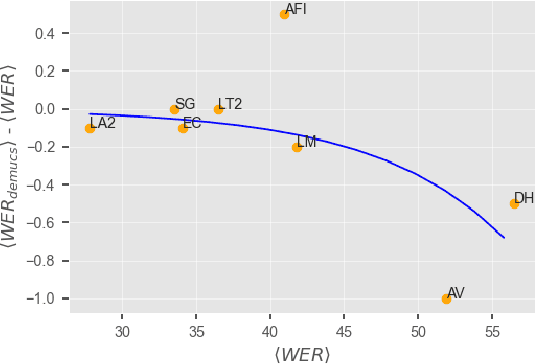
This paper describes joint effort of BUT and Telef\'onica Research on development of Automatic Speech Recognition systems for Albayzin 2020 Challenge. We compare approaches based on either hybrid or end-to-end models. In hybrid modelling, we explore the impact of SpecAugment layer on performance. For end-to-end modelling, we used a convolutional neural network with gated linear units (GLUs). The performance of such model is also evaluated with an additional n-gram language model to improve word error rates. We further inspect source separation methods to extract speech from noisy environment (i.e. TV shows). More precisely, we assess the effect of using a neural-based music separator named Demucs. A fusion of our best systems achieved 23.33% WER in official Albayzin 2020 evaluations. Aside from techniques used in our final submitted systems, we also describe our efforts in retrieving high quality transcripts for training.
BUT Opensat 2019 Speech Recognition System
Jan 30, 2020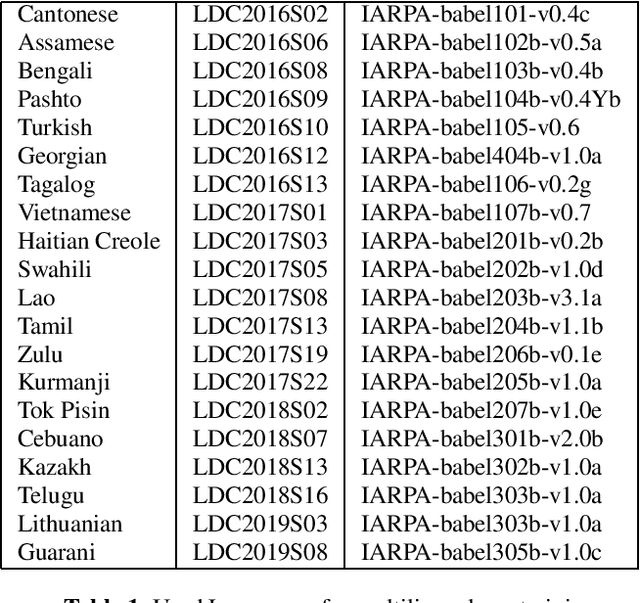


The paper describes the BUT Automatic Speech Recognition (ASR) systems submitted for OpenSAT evaluations under two domain categories such as low resourced languages and public safety communications. The first was challenging due to lack of training data, therefore various architectures and multilingual approaches were employed. The combination led to superior performance. The second domain was challenging due to recording in extreme conditions such as specific channel, speaker under stress and high levels of noise. Data augmentation process was inevitable to get reasonably good performance.
Analysis of Multilingual Sequence-to-Sequence speech recognition systems
Nov 07, 2018
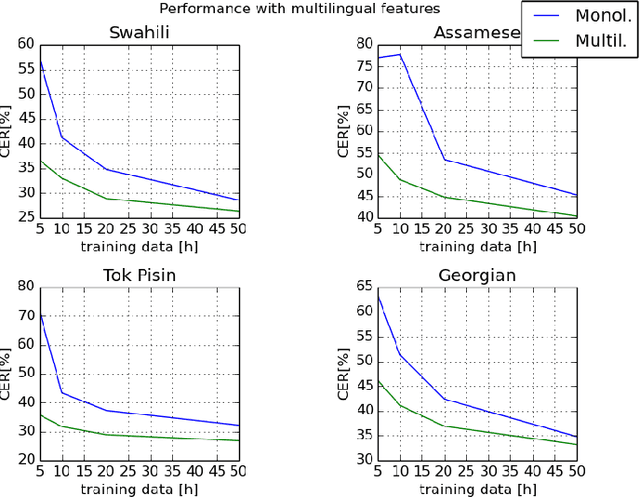
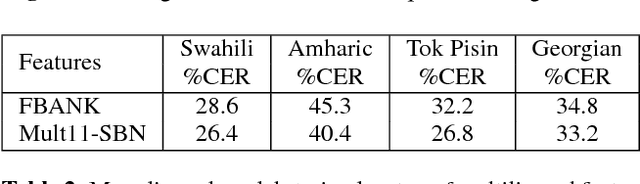
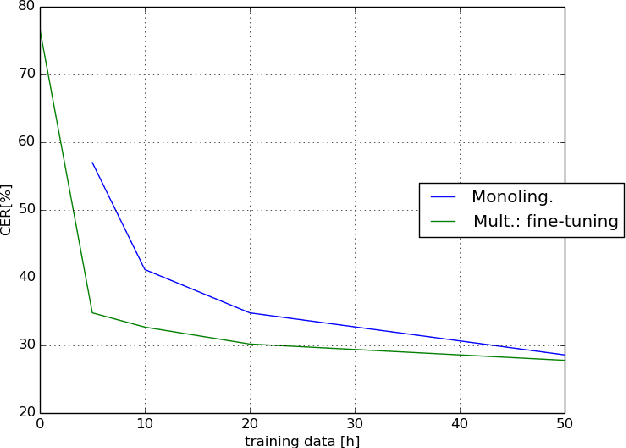
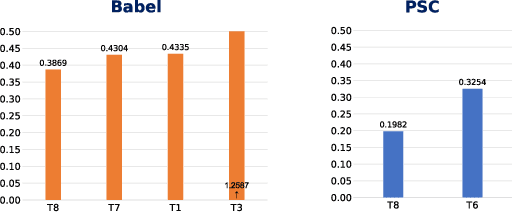
This paper investigates the applications of various multilingual approaches developed in conventional hidden Markov model (HMM) systems to sequence-to-sequence (seq2seq) automatic speech recognition (ASR). On a set composed of Babel data, we first show the effectiveness of multi-lingual training with stacked bottle-neck (SBN) features. Then we explore various architectures and training strategies of multi-lingual seq2seq models based on CTC-attention networks including combinations of output layer, CTC and/or attention component re-training. We also investigate the effectiveness of language-transfer learning in a very low resource scenario when the target language is not included in the original multi-lingual training data. Interestingly, we found multilingual features superior to multilingual models, and this finding suggests that we can efficiently combine the benefits of the HMM system with the seq2seq system through these multilingual feature techniques.
Promising Accurate Prefix Boosting for sequence-to-sequence ASR
Nov 07, 2018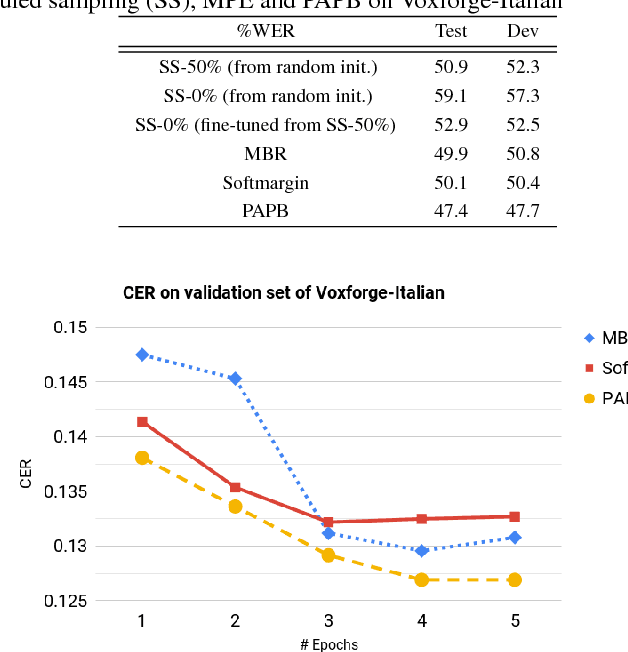
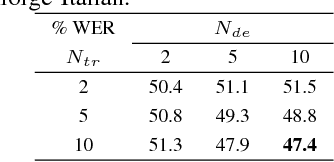
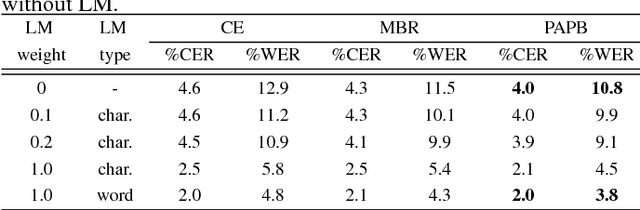
In this paper, we present promising accurate prefix boosting (PAPB), a discriminative training technique for attention based sequence-to-sequence (seq2seq) ASR. PAPB is devised to unify the training and testing scheme in an effective manner. The training procedure involves maximizing the score of each partial correct sequence obtained during beam search compared to other hypotheses. The training objective also includes minimization of token (character) error rate. PAPB shows its efficacy by achieving 10.8\% and 3.8\% WER with and without RNNLM respectively on Wall Street Journal dataset.