 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperFast: Instant Classification for Tabular Data
Feb 22, 2024



Training deep learning models and performing hyperparameter tuning can be computationally demanding and time-consuming. Meanwhile, traditional machine learning methods like gradient-boosting algorithms remain the preferred choice for most tabular data applications, while neural network alternatives require extensive hyperparameter tuning or work only in toy datasets under limited settings. In this paper, we introduce HyperFast, a meta-trained hypernetwork designed for instant classification of tabular data in a single forward pass. HyperFast generates a task-specific neural network tailored to an unseen dataset that can be directly used for classification inference, removing the need for training a model. We report extensive experiments with OpenML and genomic data, comparing HyperFast to competing tabular data neural networks, traditional ML methods, AutoML systems, and boosting machines. HyperFast shows highly competitive results, while being significantly faster. Additionally, our approach demonstrates robust adaptability across a variety of classification tasks with little to no fine-tuning, positioning HyperFast as a strong solution for numerous applications and rapid model deployment. HyperFast introduces a promising paradigm for fast classification, with the potential to substantially decrease the computational burden of deep learning. Our code, which offers a scikit-learn-like interface, along with the trained HyperFast model, can be found at https://github.com/AI-sandbox/HyperFast.
Channel redundancy and overlap in convolutional neural networks with channel-wise NNK graphs
Oct 18, 2021
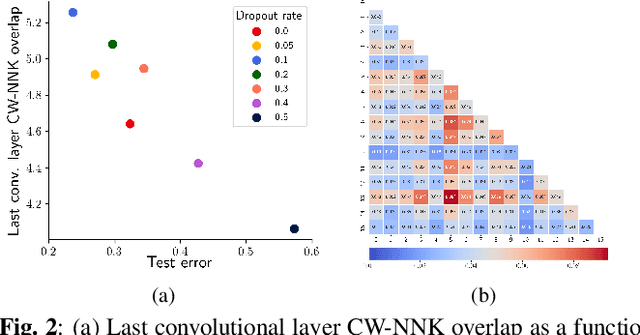

Feature spaces in the deep layers of convolutional neural networks (CNNs) are often very high-dimensional and difficult to interpret. However, convolutional layers consist of multiple channels that are activated by different types of inputs, which suggests that more insights may be gained by studying the channels and how they relate to each other. In this paper, we first analyze theoretically channel-wise non-negative kernel (CW-NNK) regression graphs, which allow us to quantify the overlap between channels and, indirectly, the intrinsic dimension of the data representation manifold. We find that redundancy between channels is significant and varies with the layer depth and the level of regularization during training. Additionally, we observe that there is a correlation between channel overlap in the last convolutional layer and generalization performance. Our experimental results demonstrate that these techniques can lead to a better understanding of deep representations.
Channel-Wise Early Stopping without a Validation Set via NNK Polytope Interpolation
Jul 27, 2021

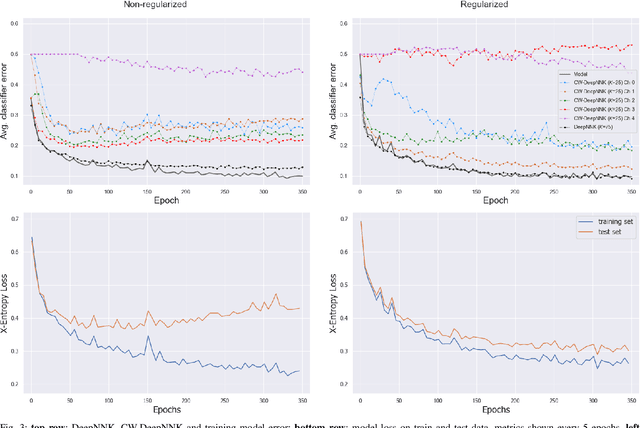

State-of-the-art neural network architectures continue to scale in size and deliver impressive generalization results, although this comes at the expense of limited interpretability. In particular, a key challenge is to determine when to stop training the model, as this has a significant impact on generalization. Convolutional neural networks (ConvNets) comprise high-dimensional feature spaces formed by the aggregation of multiple channels, where analyzing intermediate data representations and the model's evolution can be challenging owing to the curse of dimensionality. We present channel-wise DeepNNK (CW-DeepNNK), a novel channel-wise generalization estimate based on non-negative kernel regression (NNK) graphs with which we perform local polytope interpolation on low-dimensional channels. This method leads to instance-based interpretability of both the learned data representations and the relationship between channels. Motivated by our observations, we use CW-DeepNNK to propose a novel early stopping criterion that (i) does not require a validation set, (ii) is based on a task performance metric, and (iii) allows stopping to be reached at different points for each channel. Our experiments demonstrate that our proposed method has advantages as compared to the standard criterion based on validation set performance.
Speech Enhancement for Wake-Up-Word detection in Voice Assistants
Jan 29, 2021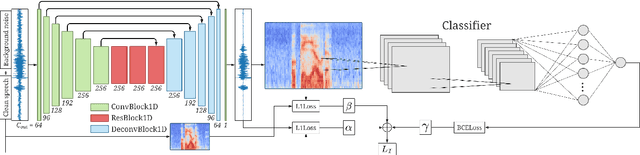
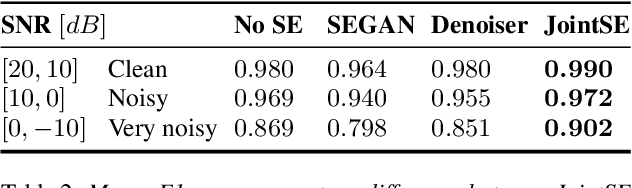
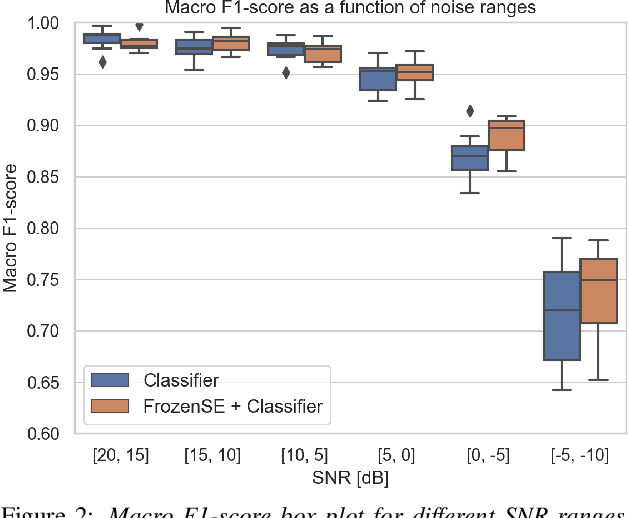
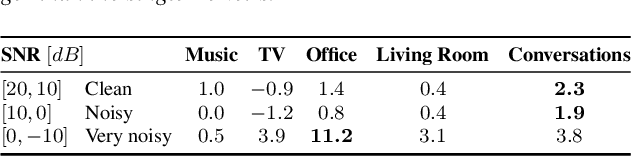
Keyword spotting and in particular Wake-Up-Word (WUW) detection is a very important task for voice assistants. A very common issue of voice assistants is that they get easily activated by background noise like music, TV or background speech that accidentally triggers the device. In this paper, we propose a Speech Enhancement (SE) model adapted to the task of WUW detection that aims at increasing the recognition rate and reducing the false alarms in the presence of these types of noises. The SE model is a fully-convolutional denoising auto-encoder at waveform level and is trained using a log-Mel Spectrogram and waveform reconstruction losses together with the BCE loss of a simple WUW classification network. A new database has been purposely prepared for the task of recognizing the WUW in challenging conditions containing negative samples that are very phonetically similar to the keyword. The database is extended with public databases and an exhaustive data augmentation to simulate different noises and environments. The results obtained by concatenating the SE with a simple and state-of-the-art WUW detectors show that the SE does not have a negative impact on the recognition rate in quiet environments while increasing the performance in the presence of noise, especially when the SE and WUW detector are trained jointly end-to-end.
BCN2BRNO: ASR System Fusion for Albayzin 2020 Speech to Text Challenge
Jan 29, 2021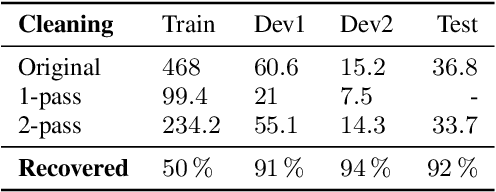
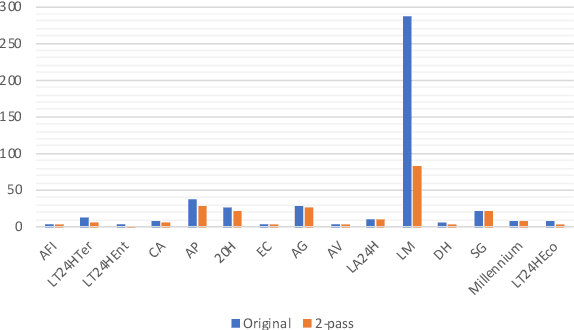
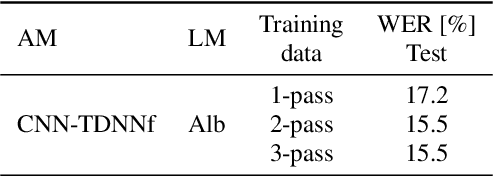
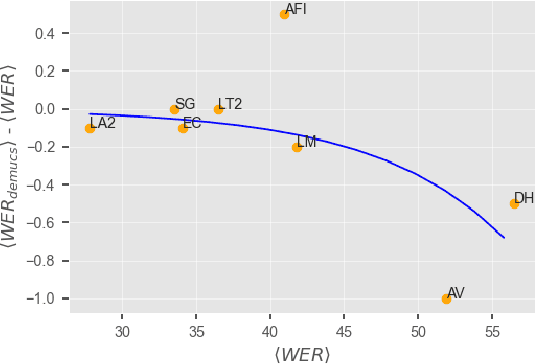
This paper describes joint effort of BUT and Telef\'onica Research on development of Automatic Speech Recognition systems for Albayzin 2020 Challenge. We compare approaches based on either hybrid or end-to-end models. In hybrid modelling, we explore the impact of SpecAugment layer on performance. For end-to-end modelling, we used a convolutional neural network with gated linear units (GLUs). The performance of such model is also evaluated with an additional n-gram language model to improve word error rates. We further inspect source separation methods to extract speech from noisy environment (i.e. TV shows). More precisely, we assess the effect of using a neural-based music separator named Demucs. A fusion of our best systems achieved 23.33% WER in official Albayzin 2020 evaluations. Aside from techniques used in our final submitted systems, we also describe our efforts in retrieving high quality transcripts for training.