 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNATE: UNsupervised ATomic Embedding for crystal structures property prediction
May 25, 2026Accurately predicting crystal properties is critical for accelerating materials discovery, but it is often limited by scarce labeled data and costly theoretical calculations. To alleviate this, we propose UNATE (Unsupervised Atomic Embedding), a framework that leverages structural information extracted from unlabeled crystal structures. UNATE integrates an unsupervised denoising autoencoder with self-supervised contrastive learning to learn robust atomic representations, which are then used as input features for downstream property prediction. Experimental results show that replacing raw atomic numbers with UNATE-pretrained node embeddings yields a 2.7\% improvement over the full-data baseline. Notably, the benefits become more pronounced in scenarios with limited labeled data, reaching improvements of up to 10\% when only 25\% of the labeled data is used.
Machine Learning Multiscale Interactions
May 25, 2026Realistic physical systems are characterised by emergent interactions across multiple length and time scales, posing a significant challenge for predictive machine learning (ML) models. Most scientific ML models focus on a narrow range of interactions. While machine learning force fields (MLFFs) offer near-quantum accuracy, the ubiquitous message-passing layers miss long-range many-body effects. Here we introduce the Multiscale Structural Ensemble (MuSE), a hierarchical model that uses Soft Coarse-Graining Pooling to construct coarse representations from smooth fractional assignments of atoms to coarse nodes, enabling MLFF modules to operate across multiple scales. MuSE is architecture-agnostic and coupled with SO3krates, MACE, and PaiNN MLFFs for both molecules and materials. We demonstrate the power of MuSE through Hessian-based benchmarks, folding trajectories for biomolecules, and energy profiles in molecule-graphene nanostructures, where MuSE accurately captures quantum-mechanical interactions at relevant scales -- unlike other recent long-range ML models.
Leveraging Latent Vector Prediction for Localized Control in Image Generation via Diffusion Models
Feb 02, 2026Diffusion models emerged as a leading approach in text-to-image generation, producing high-quality images from textual descriptions. However, attempting to achieve detailed control to get a desired image solely through text remains a laborious trial-and-error endeavor. Recent methods have introduced image-level controls alongside with text prompts, using prior images to extract conditional information such as edges, segmentation and depth maps. While effective, these methods apply conditions uniformly across the entire image, limiting localized control. In this paper, we propose a novel methodology to enable precise local control over user-defined regions of an image, while leaving to the diffusion model the task of autonomously generating the remaining areas according to the original prompt. Our approach introduces a new training framework that incorporates masking features and an additional loss term, which leverages the prediction of the initial latent vector at any diffusion step to enhance the correspondence between the current step and the final sample in the latent space. Extensive experiments demonstrate that our method effectively synthesizes high-quality images with controlled local conditions.
2D Representation for Unguided Single-View 3D Super-Resolution in Real-Time
Nov 11, 2025We introduce 2Dto3D-SR, a versatile framework for real-time single-view 3D super-resolution that eliminates the need for high-resolution RGB guidance. Our framework encodes 3D data from a single viewpoint into a structured 2D representation, enabling the direct application of existing 2D image super-resolution architectures. We utilize the Projected Normalized Coordinate Code (PNCC) to represent 3D geometry from a visible surface as a regular image, thereby circumventing the complexities of 3D point-based or RGB-guided methods. This design supports lightweight and fast models adaptable to various deployment environments. We evaluate 2Dto3D-SR with two implementations: one using Swin Transformers for high accuracy, and another using Vision Mamba for high efficiency. Experiments show the Swin Transformer model achieves state-of-the-art accuracy on standard benchmarks, while the Vision Mamba model delivers competitive results at real-time speeds. This establishes our geometry-guided pipeline as a surprisingly simple yet viable and practical solution for real-world scenarios, especially where high-resolution RGB data is inaccessible.
A Cartesian Encoding Graph Neural Network for Crystal Structures Property Prediction: Application to Thermal Ellipsoid Estimation
Jan 30, 2025



In diffraction-based crystal structure analysis, thermal ellipsoids, quantified via Anisotropic Displacement Parameters (ADPs), are critical yet challenging to determine. ADPs capture atomic vibrations, reflecting thermal and structural properties, but traditional computation is often expensive. This paper introduces CartNet, a novel graph neural network (GNN) for efficiently predicting crystal properties by encoding atomic geometry into Cartesian coordinates alongside the crystal temperature. CartNet integrates a neighbour equalization technique to emphasize covalent and contact interactions, and a Cholesky-based head to ensure valid ADP predictions. We also propose a rotational SO(3) data augmentation strategy during training to handle unseen orientations. An ADP dataset with over 200,000 experimental crystal structures from the Cambridge Structural Database (CSD) was curated to validate the approach. CartNet significantly reduces computational costs and outperforms existing methods in ADP prediction by 10.87%, while delivering a 34.77% improvement over theoretical approaches. We further evaluated CartNet on other datasets covering formation energy, band gap, total energy, energy above the convex hull, bulk moduli, and shear moduli, achieving 7.71% better results on the Jarvis Dataset and 13.16% on the Materials Project Dataset. These gains establish CartNet as a state-of-the-art solution for diverse crystal property predictions. Project website and online demo: https://www.ee.ub.edu/cartnet
Study of Manifold Geometry using Multiscale Non-Negative Kernel Graphs
Oct 31, 2022



Modern machine learning systems are increasingly trained on large amounts of data embedded in high-dimensional spaces. Often this is done without analyzing the structure of the dataset. In this work, we propose a framework to study the geometric structure of the data. We make use of our recently introduced non-negative kernel (NNK) regression graphs to estimate the point density, intrinsic dimension, and the linearity of the data manifold (curvature). We further generalize the graph construction and geometric estimation to multiple scale by iteratively merging neighborhoods in the input data. Our experiments demonstrate the effectiveness of our proposed approach over other baselines in estimating the local geometry of the data manifolds on synthetic and real datasets.
Learning task-specific features for 3D pointcloud graph creation
Sep 02, 2022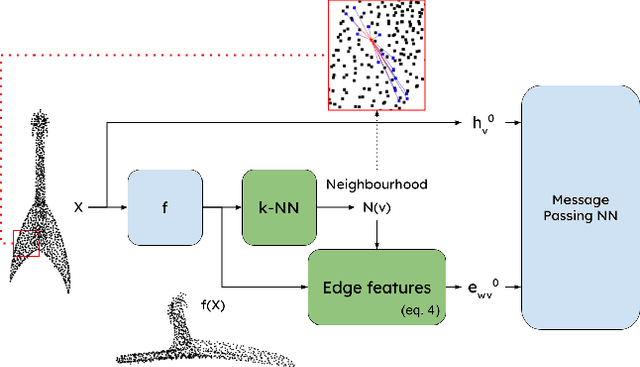
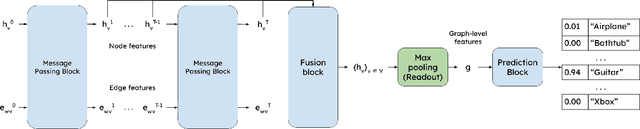
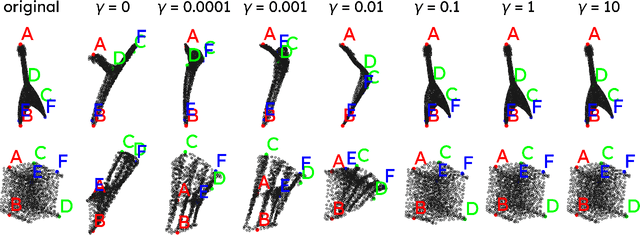
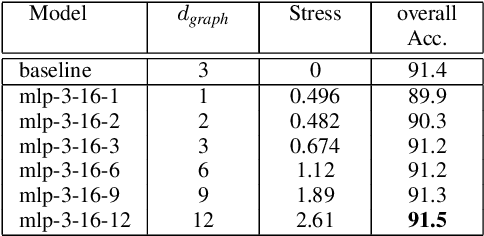
Processing 3D pointclouds with Deep Learning methods is not an easy task. A common choice is to do so with Graph Neural Networks, but this framework involves the creation of edges between points, which are explicitly not related between them. Historically, naive and handcrafted methods like k Nearest Neighbors (k-NN) or query ball point over xyz features have been proposed, focusing more attention on improving the network than improving the graph. In this work, we propose a more principled way of creating a graph from a 3D pointcloud. Our method is based on performing k-NN over a transformation of the input 3D pointcloud. This transformation is done by an Multi-Later Perceptron (MLP) with learnable parameters that is optimized through backpropagation jointly with the rest of the network. We also introduce a regularization method based on stress minimization, which allows to control how distant is the learnt graph from our baseline: k-NN over xyz space. This framework is tested on ModelNet40, where graphs generated by our network outperformed the baseline by 0.3 points in overall accuracy.
SkinningNet: Two-Stream Graph Convolutional Neural Network for Skinning Prediction of Synthetic Characters
Apr 06, 2022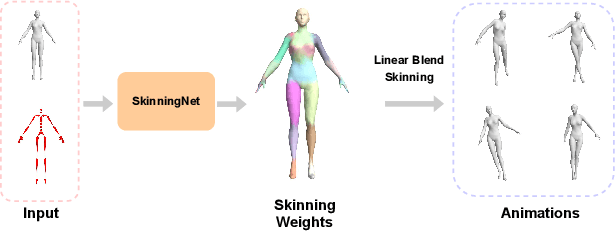
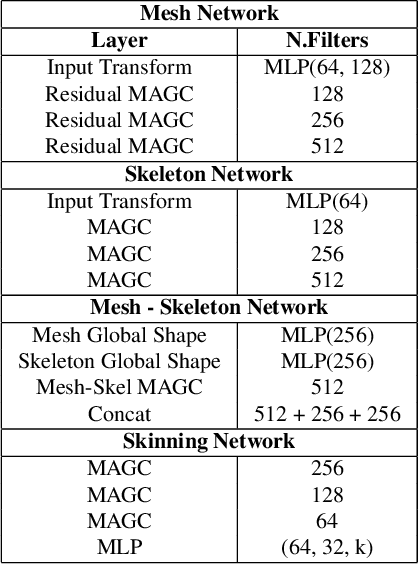
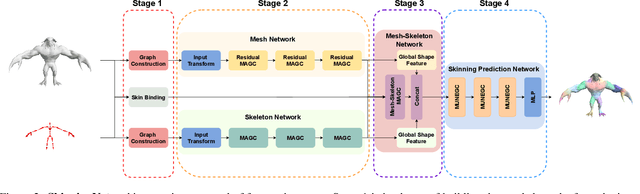
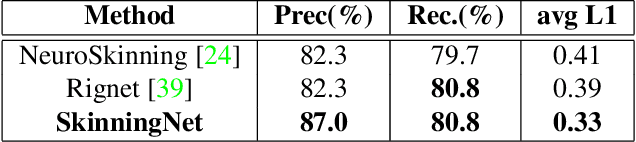
This work presents SkinningNet, an end-to-end Two-Stream Graph Neural Network architecture that computes skinning weights from an input mesh and its associated skeleton, without making any assumptions on shape class and structure of the provided mesh. Whereas previous methods pre-compute handcrafted features that relate the mesh and the skeleton or assume a fixed topology of the skeleton, the proposed method extracts this information in an end-to-end learnable fashion by jointly learning the best relationship between mesh vertices and skeleton joints. The proposed method exploits the benefits of the novel Multi-Aggregator Graph Convolution that combines the results of different aggregators during the summarizing step of the Message-Passing scheme, helping the operation to generalize for unseen topologies. Experimental results demonstrate the effectiveness of the contributions of our novel architecture, with SkinningNet outperforming current state-of-the-art alternatives.
Channel redundancy and overlap in convolutional neural networks with channel-wise NNK graphs
Oct 18, 2021
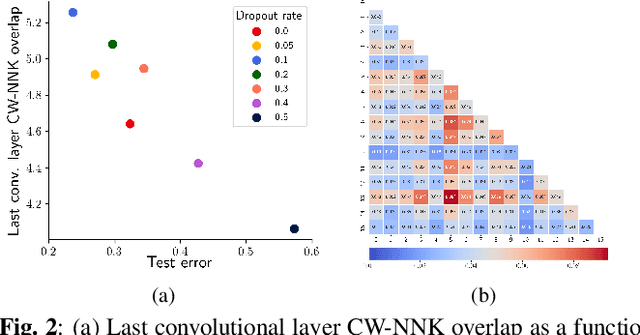

Feature spaces in the deep layers of convolutional neural networks (CNNs) are often very high-dimensional and difficult to interpret. However, convolutional layers consist of multiple channels that are activated by different types of inputs, which suggests that more insights may be gained by studying the channels and how they relate to each other. In this paper, we first analyze theoretically channel-wise non-negative kernel (CW-NNK) regression graphs, which allow us to quantify the overlap between channels and, indirectly, the intrinsic dimension of the data representation manifold. We find that redundancy between channels is significant and varies with the layer depth and the level of regularization during training. Additionally, we observe that there is a correlation between channel overlap in the last convolutional layer and generalization performance. Our experimental results demonstrate that these techniques can lead to a better understanding of deep representations.
Channel-Wise Early Stopping without a Validation Set via NNK Polytope Interpolation
Jul 27, 2021

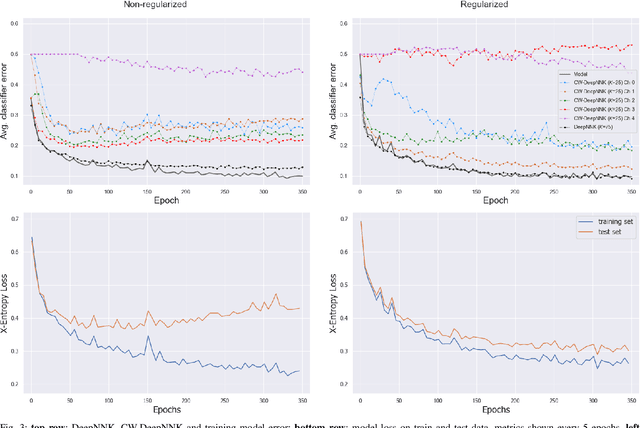

State-of-the-art neural network architectures continue to scale in size and deliver impressive generalization results, although this comes at the expense of limited interpretability. In particular, a key challenge is to determine when to stop training the model, as this has a significant impact on generalization. Convolutional neural networks (ConvNets) comprise high-dimensional feature spaces formed by the aggregation of multiple channels, where analyzing intermediate data representations and the model's evolution can be challenging owing to the curse of dimensionality. We present channel-wise DeepNNK (CW-DeepNNK), a novel channel-wise generalization estimate based on non-negative kernel regression (NNK) graphs with which we perform local polytope interpolation on low-dimensional channels. This method leads to instance-based interpretability of both the learned data representations and the relationship between channels. Motivated by our observations, we use CW-DeepNNK to propose a novel early stopping criterion that (i) does not require a validation set, (ii) is based on a task performance metric, and (iii) allows stopping to be reached at different points for each channel. Our experiments demonstrate that our proposed method has advantages as compared to the standard criterion based on validation set performance.