 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-Distortion Optimization for Ensembles of Non-Reference Metrics
Feb 17, 2026Non-reference metrics (NRMs) can assess the visual quality of images and videos without a reference, making them well-suited for the evaluation of user-generated content. Nonetheless, rate-distortion optimization (RDO) in video coding is still mainly driven by full-reference metrics, such as the sum of squared errors, which treat the input as an ideal target. A way to incorporate NRMs into RDO is through linearization (LNRM), where the gradient of the NRM with respect to the input guides bit allocation. While this strategy improves the quality predicted by some metrics, we show that it can yield limited gains or degradations when evaluated with other NRMs. We argue that NRMs are highly non-linear predictors with locally unstable gradients that can compromise the quality of the linearization; furthermore, optimizing a single metric may exploit model-specific biases that do not generalize across quality estimators. Motivated by this observation, we extend the LNRM framework to optimize ensembles of NRMs and, to further improve robustness, we introduce a smoothing-based formulation that stabilizes NRM gradients prior to linearization. Our framework is well-suited to hybrid codecs, and we advocate for its use with overfitted codecs, where it avoids iterative evaluations and backpropagation of neural network-based NRMs, reducing encoder complexity relative to direct NRM optimization. We validate the proposed approach on AVC and Cool-chic, using the YouTube UGC dataset. Experiments demonstrate consistent bitrate savings across multiple NRMs with no decoder complexity overhead and, for Cool-chic, a substantial reduction in encoding runtime compared to direct NRM optimization.
Uncertainty Principle for Vertex-Time Graph Signal Processing
Feb 03, 2026We present an uncertainty principle for graph signals in the vertex-time domain, unifying the classical time-frequency and graph uncertainty principles within a single framework. By defining vertex-time and spectral-frequency spreads, we quantify signal localization across these domains. Our framework identifies a class of signals that achieve maximum concentration in both the spatial and temporal domains. These signals serve as fundamental atoms for a new vertex-time dictionary, enhancing signal reconstruction under practical constraints, such as intermittent data commonly encountered in sensor and social networks. Furthermore, we introduce a novel graph topology inference method leveraging the uncertainty principle. Numerical experiments on synthetic and real datasets validate the effectiveness of our approach, demonstrating improved reconstruction accuracy, greater robustness to noise, and enhanced graph learning performance compared to existing methods.
Wrapper-Aware Rate-Distortion Optimization in Feature Coding for Machines
Jan 29, 2026Feature coding for machines (FCM) is a lossy compression paradigm for split-inference. The transmitter encodes the outputs of the first part of a neural network before sending them to the receiver for completing the inference. Practical FCM methods ``sandwich'' a traditional codec between pre- and post-processing neural networks, called wrappers, to make features easier to compress using video codecs. Since traditional codecs are non-differentiable, the wrappers are trained using a proxy codec, which is later replaced by a standard codec after training. These codecs perform rate-distortion optimization (RDO) based on the sum of squared errors (SSE). Because the RDO does not consider the post-processing wrapper, the inner codec can invest bits in preserving information that the post-processing later discards. In this paper, we modify the bit-allocation in the inner codec via a wrapper-aware weighted SSE metric. To make wrapper-aware RDO (WA-RDO) practical for FCM, we propose: 1) temporal reuse of weights across a group of pictures and 2) fixed, architecture- and task-dependent weights trained offline. Under MPEG test conditions, our methods implemented on HEVC match the VVC-based FCM state-of-the-art, effectively bridging a codec generation gap with minimal runtime overhead relative to SSE-RDO HEVC.
Region-Adaptive Learned Hierarchical Encoding for 3D Gaussian Splatting Data
Oct 26, 2025
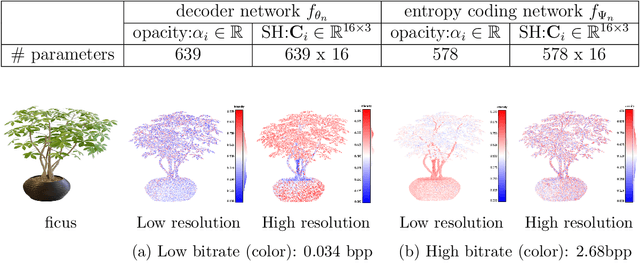
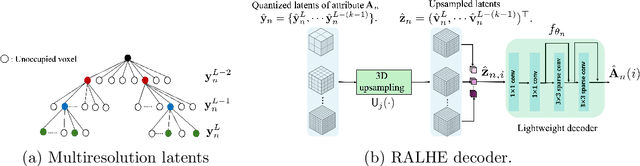

We introduce Region-Adaptive Learned Hierarchical Encoding (RALHE) for 3D Gaussian Splatting (3DGS) data. While 3DGS has recently become popular for novel view synthesis, the size of trained models limits its deployment in bandwidth-constrained applications such as volumetric media streaming. To address this, we propose a learned hierarchical latent representation that builds upon the principles of "overfitted" learned image compression (e.g., Cool-Chic and C3) to efficiently encode 3DGS attributes. Unlike images, 3DGS data have irregular spatial distributions of Gaussians (geometry) and consist of multiple attributes (signals) defined on the irregular geometry. Our codec is designed to account for these differences between images and 3DGS. Specifically, we leverage the octree structure of the voxelized 3DGS geometry to obtain a hierarchical multi-resolution representation. Our approach overfits latents to each Gaussian attribute under a global rate constraint. These latents are decoded independently through a lightweight decoder network. To estimate the bitrate during training, we employ an autoregressive probability model that leverages octree-derived contexts from the 3D point structure. The multi-resolution latents, decoder, and autoregressive entropy coding networks are jointly optimized for each Gaussian attribute. Experiments demonstrate that the proposed RALHE compression framework achieves a rendering PSNR gain of up to 2dB at low bitrates (less than 1 MB) compared to the baseline 3DGS compression methods.
Robust Classification under Noisy Labels: A Geometry-Aware Reliability Framework for Foundation Models
Jul 31, 2025Foundation models (FMs) pretrained on large datasets have become fundamental for various downstream machine learning tasks, in particular in scenarios where obtaining perfectly labeled data is prohibitively expensive. In this paper, we assume an FM has to be fine-tuned with noisy data and present a two-stage framework to ensure robust classification in the presence of label noise without model retraining. Recent work has shown that simple k-nearest neighbor (kNN) approaches using an embedding derived from an FM can achieve good performance even in the presence of severe label noise. Our work is motivated by the fact that these methods make use of local geometry. In this paper, following a similar two-stage procedure, reliability estimation followed by reliability-weighted inference, we show that improved performance can be achieved by introducing geometry information. For a given instance, our proposed inference uses a local neighborhood of training data, obtained using the non-negative kernel (NNK) neighborhood construction. We propose several methods for reliability estimation that can rely less on distance and local neighborhood as the label noise increases. Our evaluation on CIFAR-10 and DermaMNIST shows that our methods improve robustness across various noise conditions, surpassing standard K-NN approaches and recent adaptive-neighborhood baselines.
Sparse Interpretable Deep Learning with LIES Networks for Symbolic Regression
Jun 09, 2025Symbolic regression (SR) aims to discover closed-form mathematical expressions that accurately describe data, offering interpretability and analytical insight beyond standard black-box models. Existing SR methods often rely on population-based search or autoregressive modeling, which struggle with scalability and symbolic consistency. We introduce LIES (Logarithm, Identity, Exponential, Sine), a fixed neural network architecture with interpretable primitive activations that are optimized to model symbolic expressions. We develop a framework to extract compact formulae from LIES networks by training with an appropriate oversampling strategy and a tailored loss function to promote sparsity and to prevent gradient instability. After training, it applies additional pruning strategies to further simplify the learned expressions into compact formulae. Our experiments on SR benchmarks show that the LIES framework consistently produces sparse and accurate symbolic formulae outperforming all baselines. We also demonstrate the importance of each design component through ablation studies.
Joint Optimization of Primary and Secondary Transforms Using Rate-Distortion Optimized Transform Design
May 21, 2025



Data-dependent transforms are increasingly being incorporated into next-generation video coding systems such as AVM, a codec under development by the Alliance for Open Media (AOM), and VVC. To circumvent the computational complexities associated with implementing non-separable data-dependent transforms, combinations of separable primary transforms and non-separable secondary transforms have been studied and integrated into video coding standards. These codecs often utilize rate-distortion optimized transforms (RDOT) to ensure that the new transforms complement existing transforms like the DCT and the ADST. In this work, we propose an optimization framework for jointly designing primary and secondary transforms from data through a rate-distortion optimized clustering. Primary transforms are assumed to follow a path-graph model, while secondary transforms are non-separable. We empirically evaluate our proposed approach using AVM residual data and demonstrate that 1) the joint clustering method achieves lower total RD cost in the RDOT design framework, and 2) jointly optimized separable path-graph transforms (SPGT) provide better coding efficiency compared to separable KLTs obtained from the same data.
Rate-Distortion Optimization with Non-Reference Metrics for UGC Compression
May 21, 2025Service providers must encode a large volume of noisy videos to meet the demand for user-generated content (UGC) in online video-sharing platforms. However, low-quality UGC challenges conventional codecs based on rate-distortion optimization (RDO) with full-reference metrics (FRMs). While effective for pristine videos, FRMs drive codecs to preserve artifacts when the input is degraded, resulting in suboptimal compression. A more suitable approach used to assess UGC quality is based on non-reference metrics (NRMs). However, RDO with NRMs as a measure of distortion requires an iterative workflow of encoding, decoding, and metric evaluation, which is computationally impractical. This paper overcomes this limitation by linearizing the NRM around the uncompressed video. The resulting cost function enables block-wise bit allocation in the transform domain by estimating the alignment of the quantization error with the gradient of the NRM. To avoid large deviations from the input, we add sum of squared errors (SSE) regularization. We derive expressions for both the SSE regularization parameter and the Lagrangian, akin to the relationship used for SSE-RDO. Experiments with images and videos show bitrate savings of more than 30\% over SSE-RDO using the target NRM, with no decoder complexity overhead and minimal encoder complexity increase.
Image Coding for Machines via Feature-Preserving Rate-Distortion Optimization
Apr 03, 2025



Many images and videos are primarily processed by computer vision algorithms, involving only occasional human inspection. When this content requires compression before processing, e.g., in distributed applications, coding methods must optimize for both visual quality and downstream task performance. We first show that, given the features obtained from the original and the decoded images, an approach to reduce the effect of compression on a task loss is to perform rate-distortion optimization (RDO) using the distance between features as a distortion metric. However, optimizing directly such a rate-distortion trade-off requires an iterative workflow of encoding, decoding, and feature evaluation for each coding parameter, which is computationally impractical. We address this problem by simplifying the RDO formulation to make the distortion term computable using block-based encoders. We first apply Taylor's expansion to the feature extractor, recasting the feature distance as a quadratic metric with the Jacobian matrix of the neural network. Then, we replace the linearized metric with a block-wise approximation, which we call input-dependent squared error (IDSE). To reduce computational complexity, we approximate IDSE using Jacobian sketches. The resulting loss can be evaluated block-wise in the transform domain and combined with the sum of squared errors (SSE) to address both visual quality and computer vision performance. Simulations with AVC across multiple feature extractors and downstream neural networks show up to 10% bit-rate savings for the same computer vision accuracy compared to RDO based on SSE, with no decoder complexity overhead and just a 7% encoder complexity increase.
AutoML for Multi-Class Anomaly Compensation of Sensor Drift
Feb 26, 2025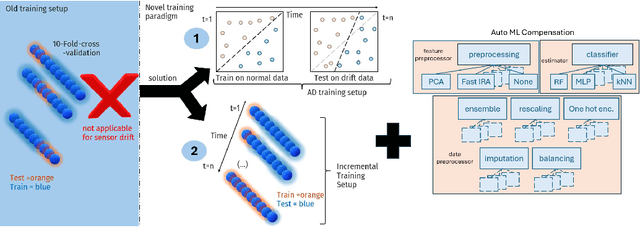
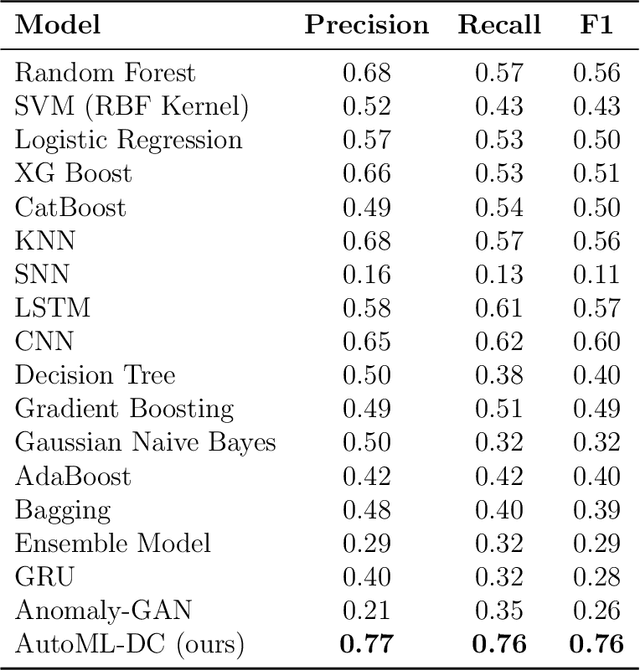
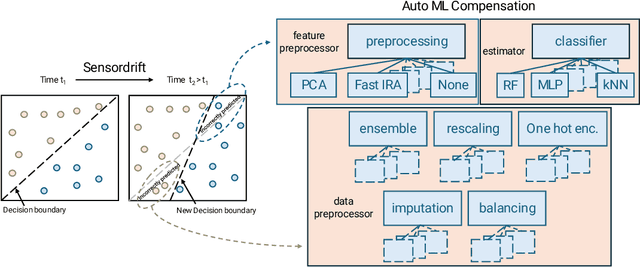
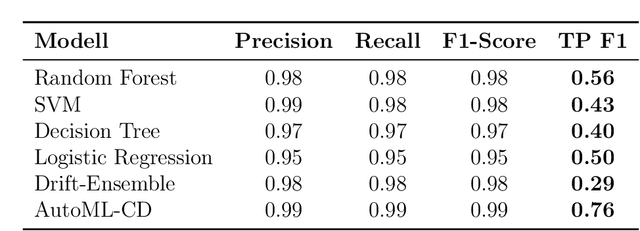
Addressing sensor drift is essential in industrial measurement systems, where precise data output is necessary for maintaining accuracy and reliability in monitoring processes, as it progressively degrades the performance of machine learning models over time. Our findings indicate that the standard cross-validation method used in existing model training overestimates performance by inadequately accounting for drift. This is primarily because typical cross-validation techniques allow data instances to appear in both training and testing sets, thereby distorting the accuracy of the predictive evaluation. As a result, these models are unable to precisely predict future drift effects, compromising their ability to generalize and adapt to evolving data conditions. This paper presents two solutions: (1) a novel sensor drift compensation learning paradigm for validating models, and (2) automated machine learning (AutoML) techniques to enhance classification performance and compensate sensor drift. By employing strategies such as data balancing, meta-learning, automated ensemble learning, hyperparameter optimization, feature selection, and boosting, our AutoML-DC (Drift Compensation) model significantly improves classification performance against sensor drift. AutoML-DC further adapts effectively to varying drift severities.