 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFIC: End-to-End Text-Focused Image Compression for Coding for Machines
Mar 25, 2025

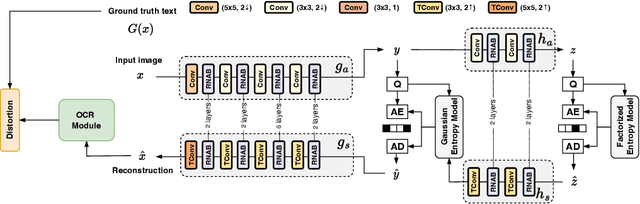

Traditional image compression methods aim to faithfully reconstruct images for human perception. In contrast, Coding for Machines focuses on compressing images to preserve information relevant to a specific machine task. In this paper, we present an image compression system designed to retain text-specific features for subsequent Optical Character Recognition (OCR). Our encoding process requires half the time needed by the OCR module, making it especially suitable for devices with limited computational capacity. In scenarios where on-device OCR is computationally prohibitive, images are compressed and later processed to recover the text content. Experimental results demonstrate that our method achieves significant improvements in text extraction accuracy at low bitrates, even improving over the accuracy of OCR performed on uncompressed images, thus acting as a local pre-processing step.
Learning Optimal Linear Block Transform by Rate Distortion Minimization
Nov 27, 2024



Linear block transform coding remains a fundamental component of image and video compression. Although the Discrete Cosine Transform (DCT) is widely employed in all current compression standards, its sub-optimality has sparked ongoing research into discovering more efficient alternative transforms even for fields where it represents a consolidated tool. In this paper, we introduce a novel linear block transform called the Rate Distortion Learned Transform (RDLT), a data-driven transform specifically designed to minimize the rate-distortion (RD) cost when approximating residual blocks. Our approach builds on the latest end-to-end learned compression frameworks, adopting back-propagation and stochastic gradient descent for optimization. However, unlike the nonlinear transforms used in variational autoencoder (VAE)-based methods, the goal is to create a simpler yet optimal linear block transform, ensuring practical integration into existing image and video compression standards. Differently from existing data-driven methods that design transforms based on sample covariance matrices, such as the Karhunen-Lo\`eve Transform (KLT), the proposed RDLT is directly optimized from an RD perspective. Experimental results show that this transform significantly outperforms the DCT or other existing data-driven transforms. Additionally, it is shown that when simulating the integration of our RDLT into a VVC-like image compression framework, the proposed transform brings substantial improvements. All the code used in our experiments has been made publicly available at [1].
Variable-size Symmetry-based Graph Fourier Transforms for image compression
Nov 24, 2024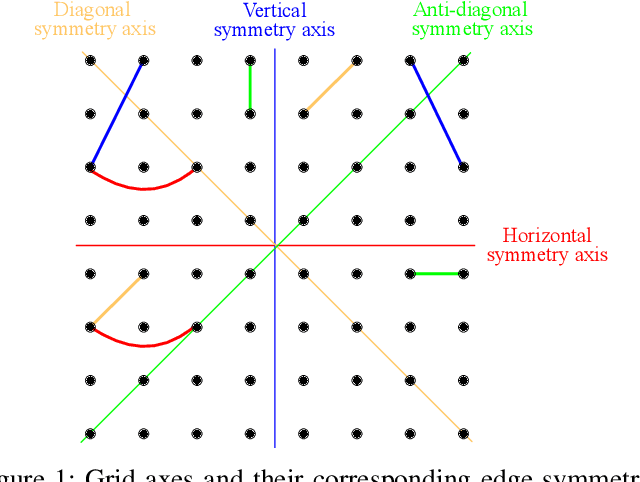
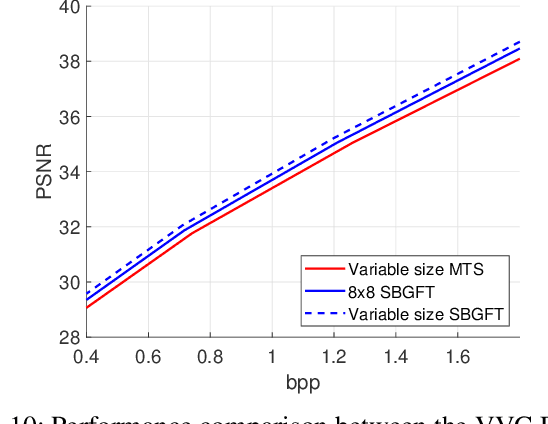
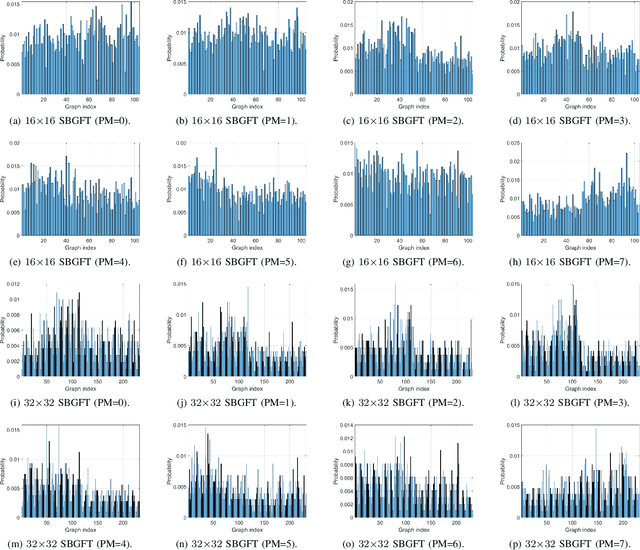
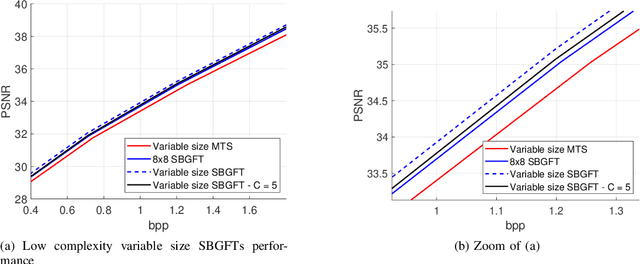
Modern compression systems use linear transformations in their encoding and decoding processes, with transforms providing compact signal representations. While multiple data-dependent transforms for image/video coding can adapt to diverse statistical characteristics, assembling large datasets to learn each transform is challenging. Also, the resulting transforms typically lack fast implementation, leading to significant computational costs. Thus, despite many papers proposing new transform families, the most recent compression standards predominantly use traditional separable sinusoidal transforms. This paper proposes integrating a new family of Symmetry-based Graph Fourier Transforms (SBGFTs) of variable sizes into a coding framework, focusing on the extension from our previously introduced 8x8 SBGFTs to the general case of NxN grids. SBGFTs are non-separable transforms that achieve sparse signal representation while maintaining low computational complexity thanks to their symmetry properties. Their design is based on our proposed algorithm, which generates symmetric graphs on the grid by adding specific symmetrical connections between nodes and does not require any data-dependent adaptation. Furthermore, for video intra-frame coding, we exploit the correlations between optimal graphs and prediction modes to reduce the cardinality of the transform sets, thus proposing a low-complexity framework. Experiments show that SBGFTs outperform the primary transforms integrated in the explicit Multiple Transform Selection (MTS) used in the latest VVC intra-coding, providing a bit rate saving percentage of 6.23%, with only a marginal increase in average complexity. A MATLAB implementation of the proposed algorithm is available online at [1].
ComNeck: Bridging Compressed Image Latents and Multimodal LLMs via Universal Transform-Neck
Jul 29, 2024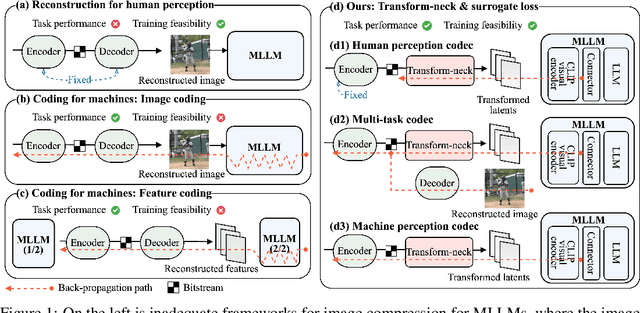

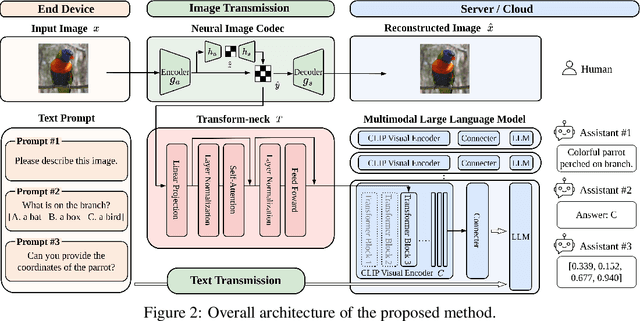
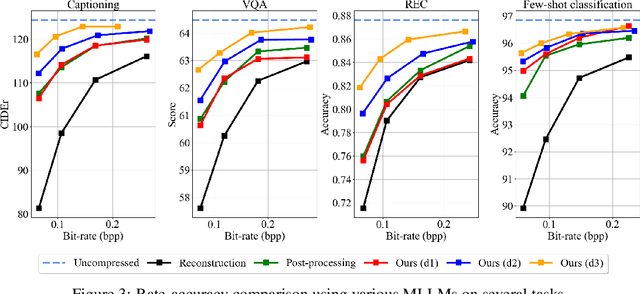
This paper presents the first-ever study of adapting compressed image latents to suit the needs of downstream vision tasks that adopt Multimodal Large Language Models (MLLMs). MLLMs have extended the success of large language models to modalities (e.g. images) beyond text, but their billion scale hinders deployment on resource-constrained end devices. While cloud-hosted MLLMs could be available, transmitting raw, uncompressed images captured by end devices to the cloud requires an efficient image compression system. To address this, we focus on emerging neural image compression and propose a novel framework with a lightweight transform-neck and a surrogate loss to adapt compressed image latents for MLLM-based vision tasks. The proposed framework is generic and applicable to multiple application scenarios, where the neural image codec can be (1) pre-trained for human perception without updating, (2) fully updated for joint human and machine perception, or (3) fully updated for only machine perception. The transform-neck trained with the surrogate loss is universal, for it can serve various downstream vision tasks enabled by a variety of MLLMs that share the same visual encoder. Our framework has the striking feature of excluding the downstream MLLMs from training the transform-neck, and potentially the neural image codec as well. This stands out from most existing coding for machine approaches that involve downstream networks in training and thus could be impractical when the networks are MLLMs. Extensive experiments on different neural image codecs and various MLLM-based vision tasks show that our method achieves great rate-accuracy performance with much less complexity, demonstrating its effectiveness.
Transformer-based Learned Image Compression for Joint Decoding and Denoising
Feb 20, 2024



This work introduces a Transformer-based image compression system. It has the flexibility to switch between the standard image reconstruction and the denoising reconstruction from a single compressed bitstream. Instead of training separate decoders for these tasks, we incorporate two add-on modules to adapt a pre-trained image decoder from performing the standard image reconstruction to joint decoding and denoising. Our scheme adopts a two-pronged approach. It features a latent refinement module to refine the latent representation of a noisy input image for reconstructing a noise-free image. Additionally, it incorporates an instance-specific prompt generator that adapts the decoding process to improve on the latent refinement. Experimental results show that our method achieves a similar level of denoising quality to training a separate decoder for joint decoding and denoising at the expense of only a modest increase in the decoder's model size and computational complexity.
LiDAR Depth Map Guided Image Compression Model
Jan 12, 2024

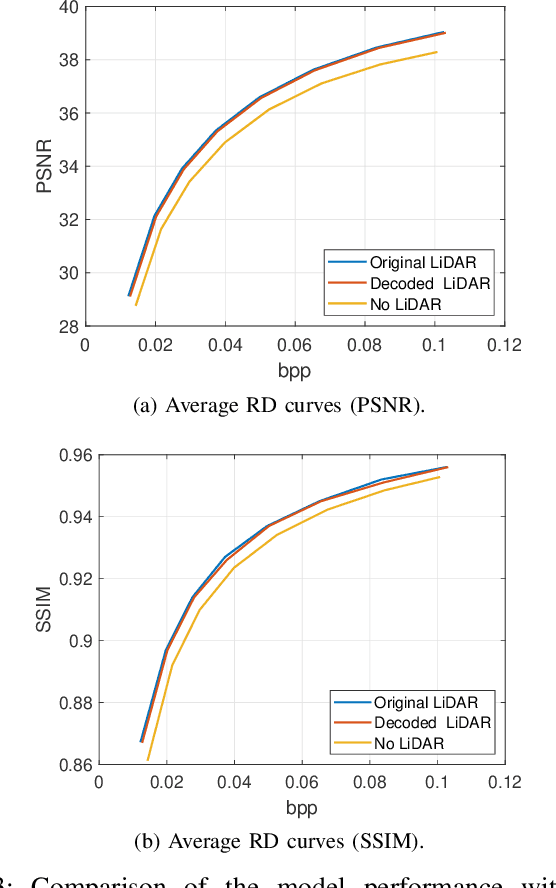

The incorporation of LiDAR technology into some high-end smartphones has unlocked numerous possibilities across various applications, including photography, image restoration, augmented reality, and more. In this paper, we introduce a novel direction that harnesses LiDAR depth maps to enhance the compression of the corresponding RGB camera images. Specifically, we propose a Transformer-based learned image compression system capable of achieving variable-rate compression using a single model while utilizing the LiDAR depth map as supplementary information for both the encoding and decoding processes. Experimental results demonstrate that integrating LiDAR yields an average PSNR gain of 0.83 dB and an average bitrate reduction of 16% as compared to its absence.
End-to-end learning for semiquantitative rating of COVID-19 severity on Chest X-rays
Jun 08, 2020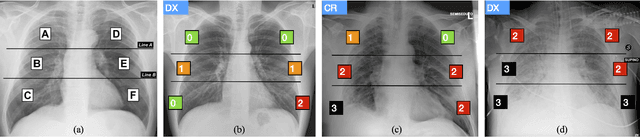
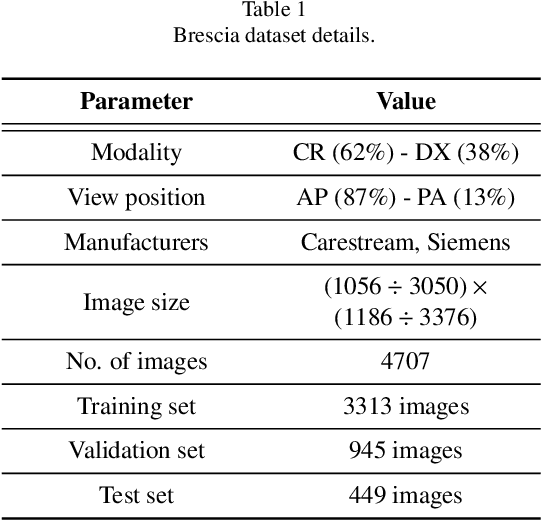
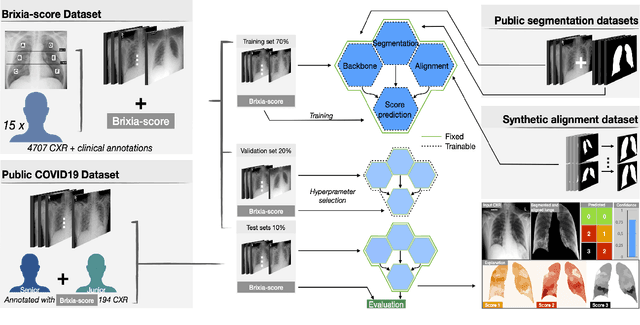
In this work we designed an end-to-end deep learning architecture for predicting, on Chest X-rays images (CRX), a multi-regional score conveying the degree of lung compromise in COVID-19 patients. Such semiquantitative scoring system, namely Brixia-score, was applied in serial monitoring of such patients, showing significant prognostic value, in one of the hospitals that experienced one of the highest pandemic peaks in Italy. To solve such a challenging visual task, we adopt a weakly supervised learning strategy structured to handle different tasks (segmentation, spatial alignment, and score estimation) trained with a "from part to whole" procedure involving different datasets. In particular, we exploited a clinical dataset of almost 5,000 CXR annotated images collected in the same hospital. Our BS-Net demonstrated self-attentive behavior and a high degree of accuracy in all processing stages. Through inter-rater agreement tests and a gold standard comparison, we were able to show that our solution outperforms single human annotators in rating accuracy and consistency, thus supporting the possibility of using this tool in contexts of computer-assisted monitoring. Highly resolved (super-pixel level) explainability maps were also generated, with an original technique, to visually help the understanding of the network activity on the lung areas. We eventually tested the performance robustness of our model on a variegated public COVID-19 dataset, for which we also provide Brixia-score annotations, observing good direct generalization and fine-tuning capabilities that favorably highlight the portability of BS-Net in other clinical settings.
Feature Fusion for Robust Patch Matching With Compact Binary Descriptors
Jan 11, 2019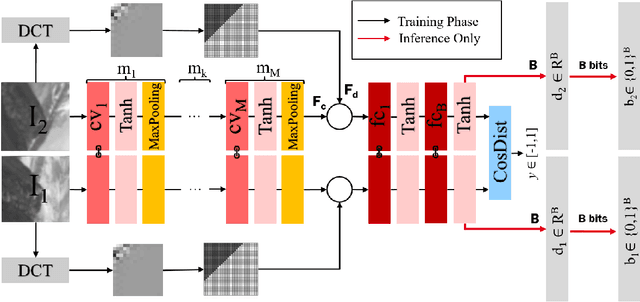

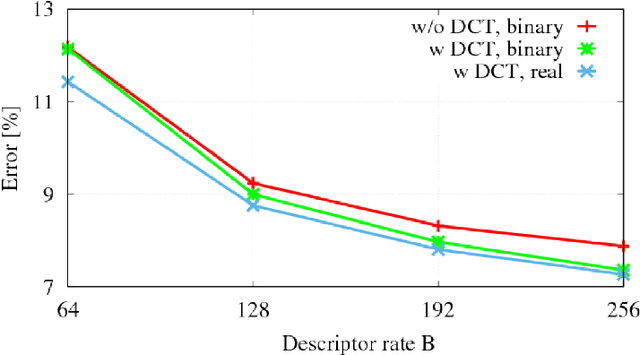
This work addresses the problem of learning compact yet discriminative patch descriptors within a deep learning framework. We observe that features extracted by convolutional layers in the pixel domain are largely complementary to features extracted in a transformed domain. We propose a convolutional network framework for learning binary patch descriptors where pixel domain features are fused with features extracted from the transformed domain. In our framework, while convolutional and transformed features are distinctly extracted, they are fused and provided to a single classifier which thus jointly operates on convolutional and transformed features. We experiment at matching patches from three different datasets, showing that our feature fusion approach outperforms multiple state-of-the-art approaches in terms of accuracy, rate, and complexity.