 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeletonization-Based Adversarial Perturbations on Large Vision Language Model's Mathematical Text Recognition
Jan 08, 2026This work explores the visual capabilities and limitations of foundation models by introducing a novel adversarial attack method utilizing skeletonization to reduce the search space effectively. Our approach specifically targets images containing text, particularly mathematical formula images, which are more challenging due to their LaTeX conversion and intricate structure. We conduct a detailed evaluation of both character and semantic changes between original and adversarially perturbed outputs to provide insights into the models' visual interpretation and reasoning abilities. The effectiveness of our method is further demonstrated through its application to ChatGPT, which shows its practical implications in real-world scenarios.
* accepted to ITC-CSCC 2025
Spectrogram-Based Detection of Auto-Tuned Vocals in Music Recordings
Mar 08, 2024In the domain of music production and audio processing, the implementation of automatic pitch correction of the singing voice, also known as Auto-Tune, has significantly transformed the landscape of vocal performance. While auto-tuning technology has offered musicians the ability to tune their vocal pitches and achieve a desired level of precision, its use has also sparked debates regarding its impact on authenticity and artistic integrity. As a result, detecting and analyzing Auto-Tuned vocals in music recordings has become essential for music scholars, producers, and listeners. However, to the best of our knowledge, no prior effort has been made in this direction. This study introduces a data-driven approach leveraging triplet networks for the detection of Auto-Tuned songs, backed by the creation of a dataset composed of original and Auto-Tuned audio clips. The experimental results demonstrate the superiority of the proposed method in both accuracy and robustness compared to Rawnet2, an end-to-end model proposed for anti-spoofing and widely used for other audio forensic tasks.
End-to-end learning for semiquantitative rating of COVID-19 severity on Chest X-rays
Jun 08, 2020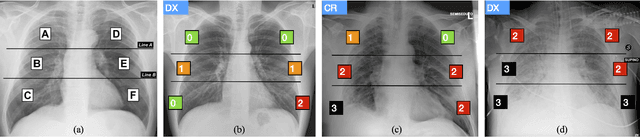
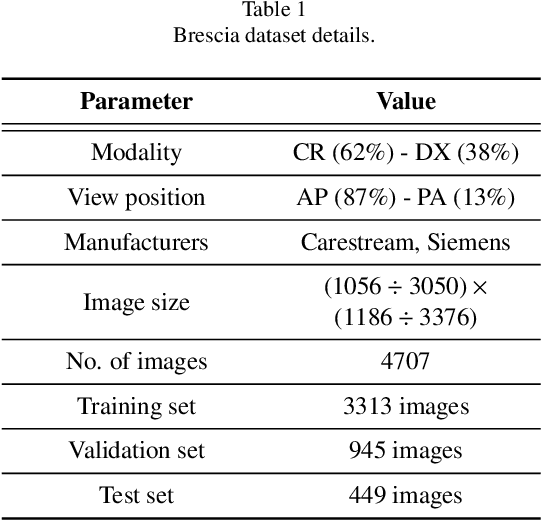
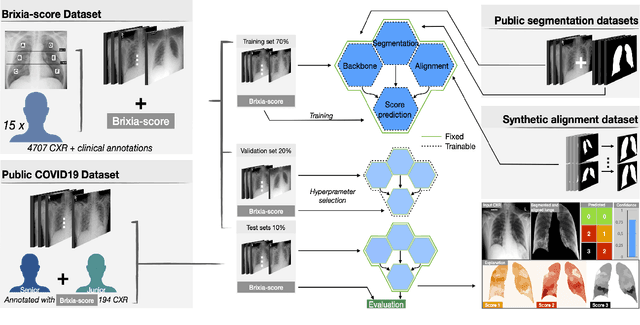
In this work we designed an end-to-end deep learning architecture for predicting, on Chest X-rays images (CRX), a multi-regional score conveying the degree of lung compromise in COVID-19 patients. Such semiquantitative scoring system, namely Brixia-score, was applied in serial monitoring of such patients, showing significant prognostic value, in one of the hospitals that experienced one of the highest pandemic peaks in Italy. To solve such a challenging visual task, we adopt a weakly supervised learning strategy structured to handle different tasks (segmentation, spatial alignment, and score estimation) trained with a "from part to whole" procedure involving different datasets. In particular, we exploited a clinical dataset of almost 5,000 CXR annotated images collected in the same hospital. Our BS-Net demonstrated self-attentive behavior and a high degree of accuracy in all processing stages. Through inter-rater agreement tests and a gold standard comparison, we were able to show that our solution outperforms single human annotators in rating accuracy and consistency, thus supporting the possibility of using this tool in contexts of computer-assisted monitoring. Highly resolved (super-pixel level) explainability maps were also generated, with an original technique, to visually help the understanding of the network activity on the lung areas. We eventually tested the performance robustness of our model on a variegated public COVID-19 dataset, for which we also provide Brixia-score annotations, observing good direct generalization and fine-tuning capabilities that favorably highlight the portability of BS-Net in other clinical settings.