 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComNeck: Bridging Compressed Image Latents and Multimodal LLMs via Universal Transform-Neck
Jul 29, 2024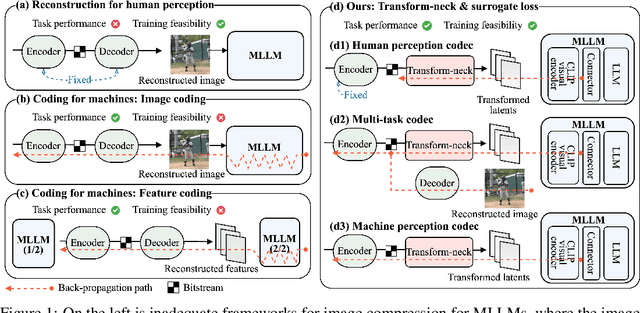

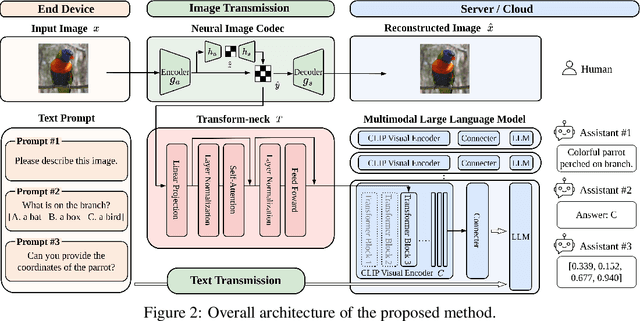
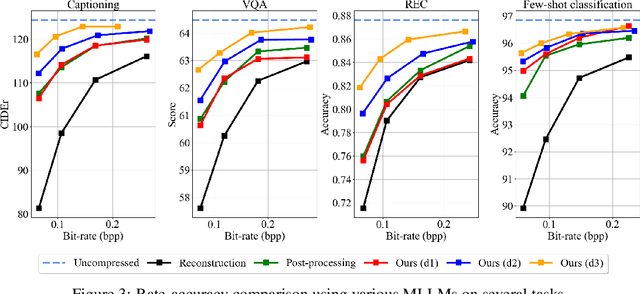
This paper presents the first-ever study of adapting compressed image latents to suit the needs of downstream vision tasks that adopt Multimodal Large Language Models (MLLMs). MLLMs have extended the success of large language models to modalities (e.g. images) beyond text, but their billion scale hinders deployment on resource-constrained end devices. While cloud-hosted MLLMs could be available, transmitting raw, uncompressed images captured by end devices to the cloud requires an efficient image compression system. To address this, we focus on emerging neural image compression and propose a novel framework with a lightweight transform-neck and a surrogate loss to adapt compressed image latents for MLLM-based vision tasks. The proposed framework is generic and applicable to multiple application scenarios, where the neural image codec can be (1) pre-trained for human perception without updating, (2) fully updated for joint human and machine perception, or (3) fully updated for only machine perception. The transform-neck trained with the surrogate loss is universal, for it can serve various downstream vision tasks enabled by a variety of MLLMs that share the same visual encoder. Our framework has the striking feature of excluding the downstream MLLMs from training the transform-neck, and potentially the neural image codec as well. This stands out from most existing coding for machine approaches that involve downstream networks in training and thus could be impractical when the networks are MLLMs. Extensive experiments on different neural image codecs and various MLLM-based vision tasks show that our method achieves great rate-accuracy performance with much less complexity, demonstrating its effectiveness.
Transformer-based Image Compression with Variable Image Quality Objectives
Sep 22, 2023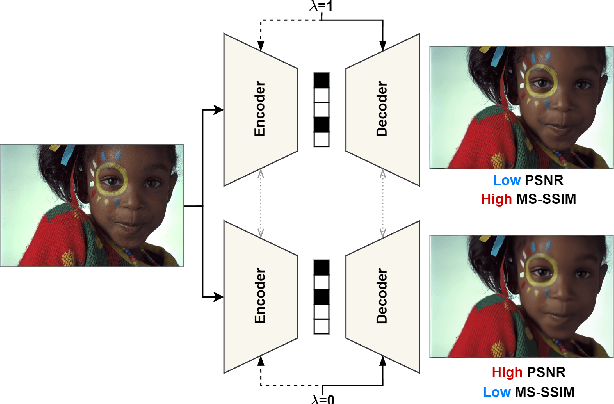
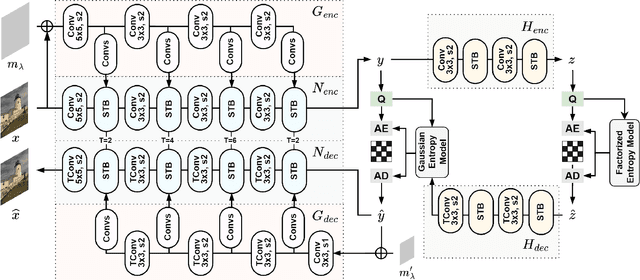
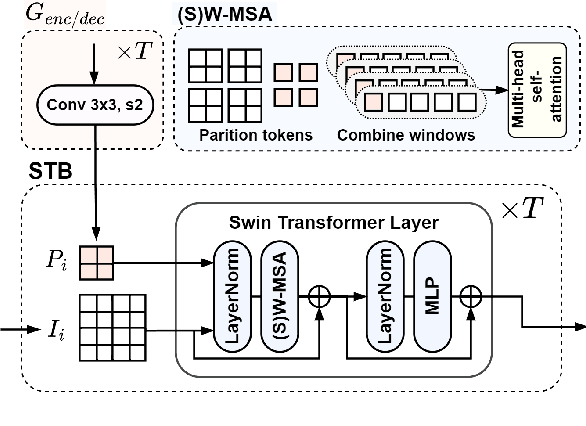
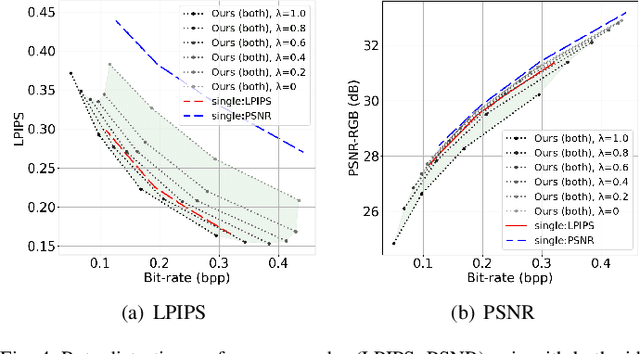
This paper presents a Transformer-based image compression system that allows for a variable image quality objective according to the user's preference. Optimizing a learned codec for different quality objectives leads to reconstructed images with varying visual characteristics. Our method provides the user with the flexibility to choose a trade-off between two image quality objectives using a single, shared model. Motivated by the success of prompt-tuning techniques, we introduce prompt tokens to condition our Transformer-based autoencoder. These prompt tokens are generated adaptively based on the user's preference and input image through learning a prompt generation network. Extensive experiments on commonly used quality metrics demonstrate the effectiveness of our method in adapting the encoding and/or decoding processes to a variable quality objective. While offering the additional flexibility, our proposed method performs comparably to the single-objective methods in terms of rate-distortion performance.
TransTIC: Transferring Transformer-based Image Compression from Human Visualization to Machine Perception
Jun 08, 2023

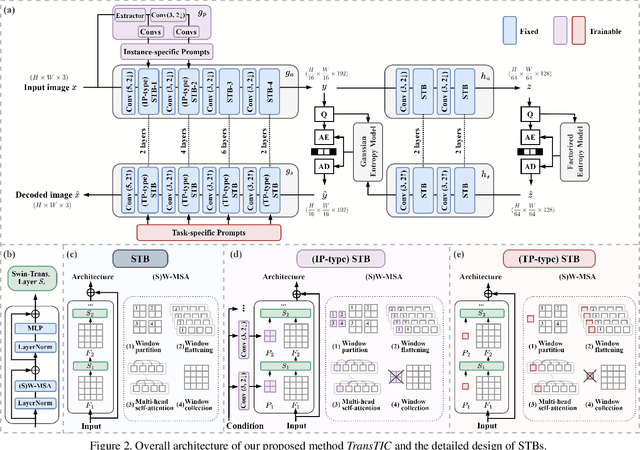
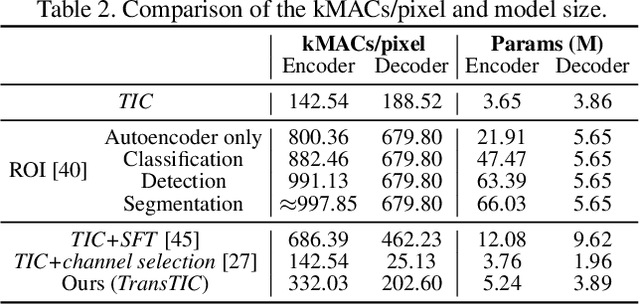
This work aims for transferring a Transformer-based image compression codec from human vision to machine perception without fine-tuning the codec. We propose a transferable Transformer-based image compression framework, termed TransTIC. Inspired by visual prompt tuning, we propose an instance-specific prompt generator to inject instance-specific prompts to the encoder and task-specific prompts to the decoder. Extensive experiments show that our proposed method is capable of transferring the codec to various machine tasks and outshining the competing methods significantly. To our best knowledge, this work is the first attempt to utilize prompting on the low-level image compression task.
Learned Hierarchical B-frame Coding with Adaptive Feature Modulation for YUV 4:2:0 Content
Dec 29, 2022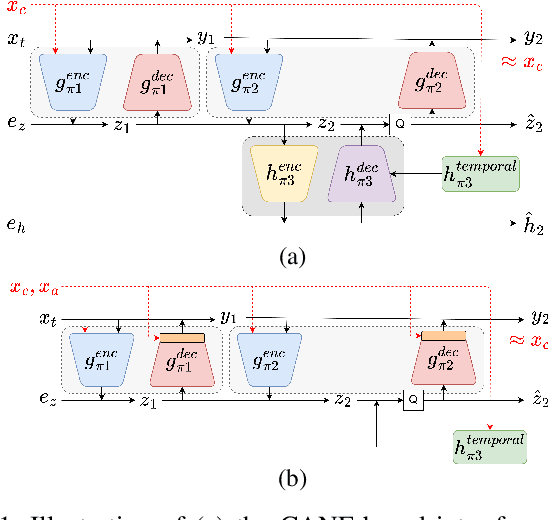
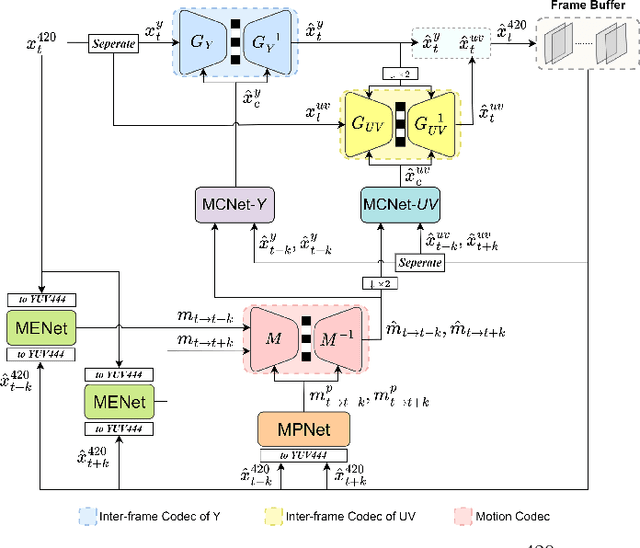
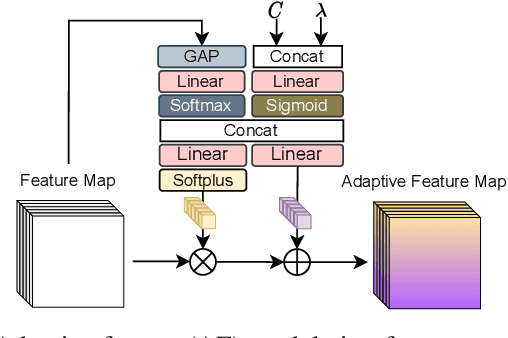

This paper introduces a learned hierarchical B-frame coding scheme in response to the Grand Challenge on Neural Network-based Video Coding at ISCAS 2023. We address specifically three issues, including (1) B-frame coding, (2) YUV 4:2:0 coding, and (3) content-adaptive variable-rate coding with only one single model. Most learned video codecs operate internally in the RGB domain for P-frame coding. B-frame coding for YUV 4:2:0 content is largely under-explored. In addition, while there have been prior works on variable-rate coding with conditional convolution, most of them fail to consider the content information. We build our scheme on conditional augmented normalized flows (CANF). It features conditional motion and inter-frame codecs for efficient B-frame coding. To cope with YUV 4:2:0 content, two conditional inter-frame codecs are used to process the Y and UV components separately, with the coding of the UV components conditioned additionally on the Y component. Moreover, we introduce adaptive feature modulation in every convolutional layer, taking into account both the content information and the coding levels of B-frames to achieve content-adaptive variable-rate coding. Experimental results show that our model outperforms x265 and the winner of last year's challenge on commonly used datasets in terms of PSNR-YUV.