 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical B-frame Video Coding Using Two-Layer CANF without Motion Coding
Apr 05, 2023Typical video compression systems consist of two main modules: motion coding and residual coding. This general architecture is adopted by classical coding schemes (such as international standards H.265 and H.266) and deep learning-based coding schemes. We propose a novel B-frame coding architecture based on two-layer Conditional Augmented Normalization Flows (CANF). It has the striking feature of not transmitting any motion information. Our proposed idea of video compression without motion coding offers a new direction for learned video coding. Our base layer is a low-resolution image compressor that replaces the full-resolution motion compressor. The low-resolution coded image is merged with the warped high-resolution images to generate a high-quality image as a conditioning signal for the enhancement-layer image coding in full resolution. One advantage of this architecture is significantly reduced computational complexity due to eliminating the motion information compressor. In addition, we adopt a skip-mode coding technique to reduce the transmitted latent samples. The rate-distortion performance of our scheme is slightly lower than that of the state-of-the-art learned B-frame coding scheme, B-CANF, but outperforms other learned B-frame coding schemes. However, compared to B-CANF, our scheme saves 45% of multiply-accumulate operations (MACs) for encoding and 27% of MACs for decoding. The code is available at https://nycu-clab.github.io.
Learned Hierarchical B-frame Coding with Adaptive Feature Modulation for YUV 4:2:0 Content
Dec 29, 2022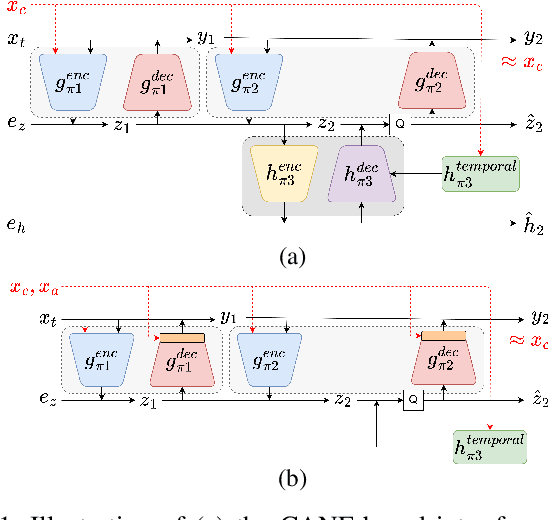
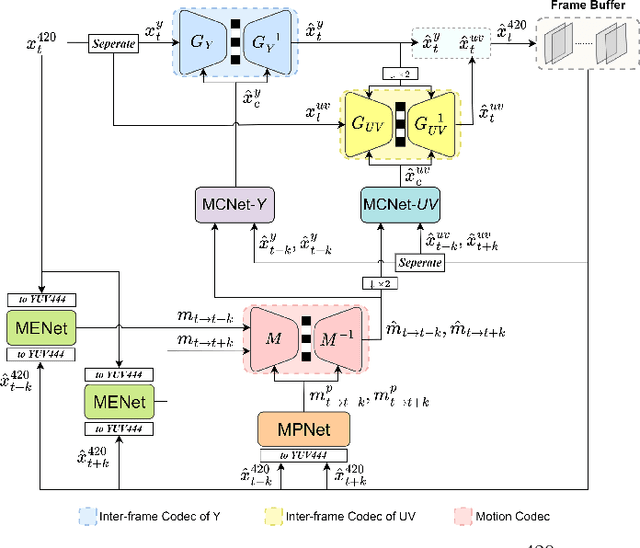
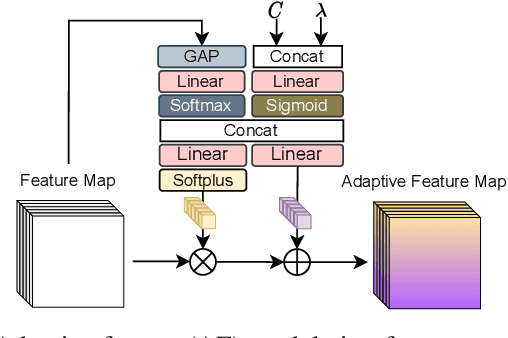

This paper introduces a learned hierarchical B-frame coding scheme in response to the Grand Challenge on Neural Network-based Video Coding at ISCAS 2023. We address specifically three issues, including (1) B-frame coding, (2) YUV 4:2:0 coding, and (3) content-adaptive variable-rate coding with only one single model. Most learned video codecs operate internally in the RGB domain for P-frame coding. B-frame coding for YUV 4:2:0 content is largely under-explored. In addition, while there have been prior works on variable-rate coding with conditional convolution, most of them fail to consider the content information. We build our scheme on conditional augmented normalized flows (CANF). It features conditional motion and inter-frame codecs for efficient B-frame coding. To cope with YUV 4:2:0 content, two conditional inter-frame codecs are used to process the Y and UV components separately, with the coding of the UV components conditioned additionally on the Y component. Moreover, we introduce adaptive feature modulation in every convolutional layer, taking into account both the content information and the coding levels of B-frames to achieve content-adaptive variable-rate coding. Experimental results show that our model outperforms x265 and the winner of last year's challenge on commonly used datasets in terms of PSNR-YUV.
Learned Video Compression for YUV 4:2:0 Content Using Flow-based Conditional Inter-frame Coding
Oct 15, 2022
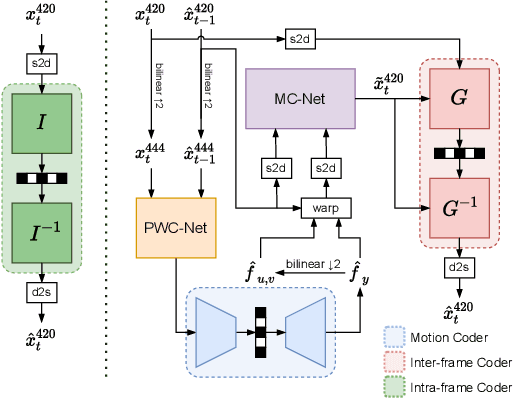
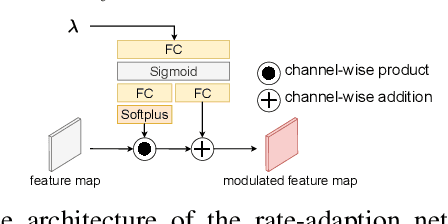
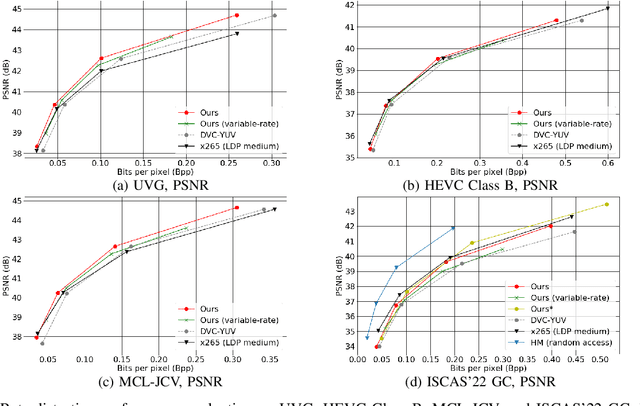
This paper proposes a learning-based video compression framework for variable-rate coding on YUV 4:2:0 content. Most existing learning-based video compression models adopt the traditional hybrid-based coding architecture, which involves temporal prediction followed by residual coding. However, recent studies have shown that residual coding is sub-optimal from the information-theoretic perspective. In addition, most existing models are optimized with respect to RGB content. Furthermore, they require separate models for variable-rate coding. To address these issues, this work presents an attempt to incorporate the conditional inter-frame coding for YUV 4:2:0 content. We introduce a conditional flow-based inter-frame coder to improve the inter-frame coding efficiency. To adapt our codec to YUV 4:2:0 content, we adopt a simple strategy of using space-to-depth and depth-to-space conversions. Lastly, we employ a rate-adaption net to achieve variable-rate coding without training multiple models. Experimental results show that our model performs better than x265 on UVG and MCL-JCV datasets in terms of PSNR-YUV. However, on the more challenging datasets from ISCAS'22 GC, there is still ample room for improvement. This insufficient performance is due to the lack of inter-frame coding capability at a large GOP size and can be mitigated by increasing the model capacity and applying an error propagation-aware training strategy.
Fast Vehicle Detection and Tracking on Fisheye Traffic Monitoring Video using CNN and Bounding Box Propagation
Jul 13, 2022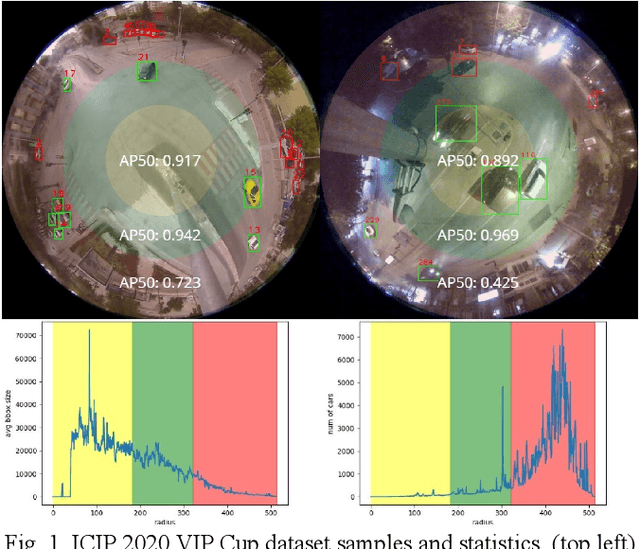


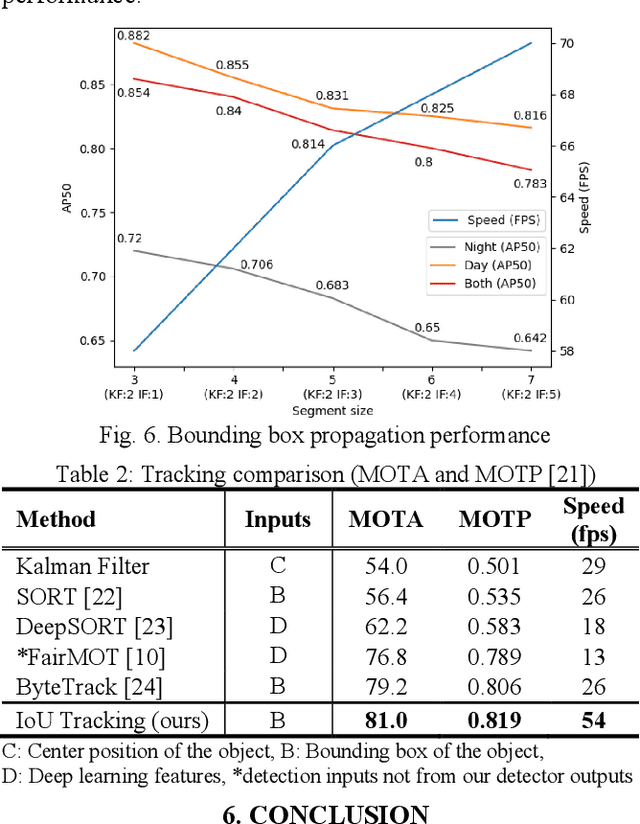
We design a fast car detection and tracking algorithm for traffic monitoring fisheye video mounted on crossroads. We use ICIP 2020 VIP Cup dataset and adopt YOLOv5 as the object detection base model. The nighttime video of this dataset is very challenging, and the detection accuracy (AP50) of the base model is about 54%. We design a reliable car detection and tracking algorithm based on the concept of bounding box propagation among frames, which provides 17.9 percentage points (pp) and 6.2 pp. accuracy improvement over the base model for the nighttime and daytime videos, respectively. To speed up, the grayscale frame difference is used for the intermediate frames in a segment, which can double the processing speed.
ANFIC: Image Compression Using Augmented Normalizing Flows
Jul 18, 2021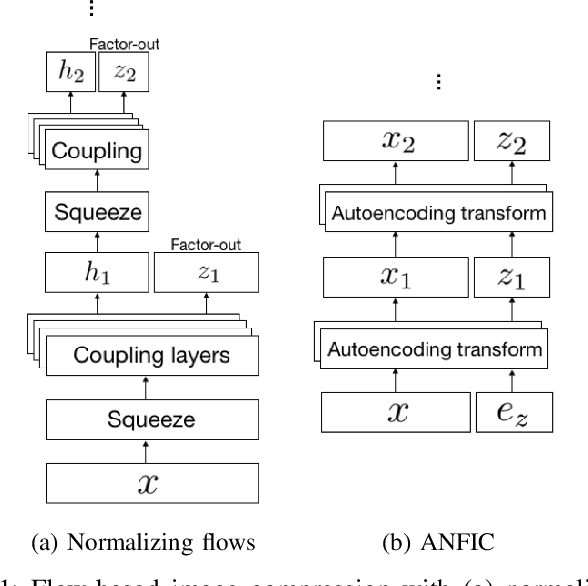
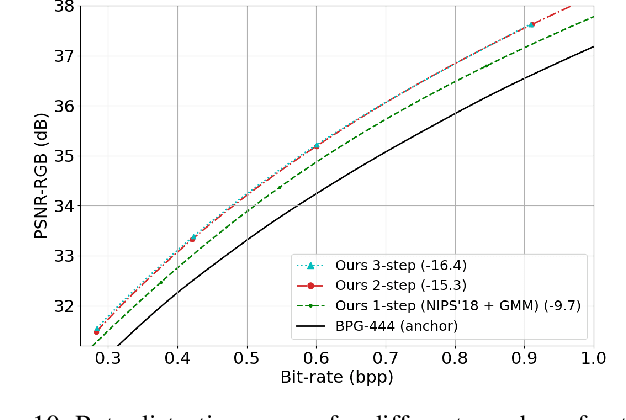
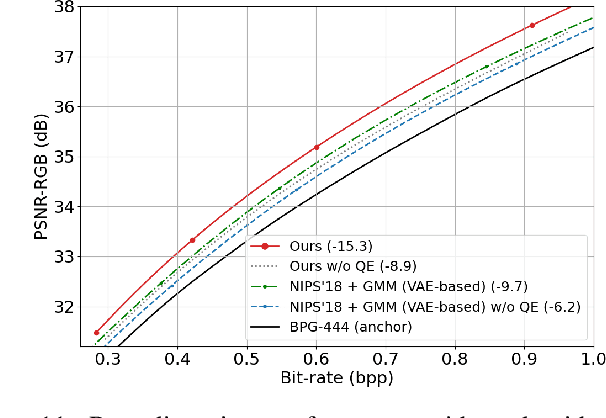
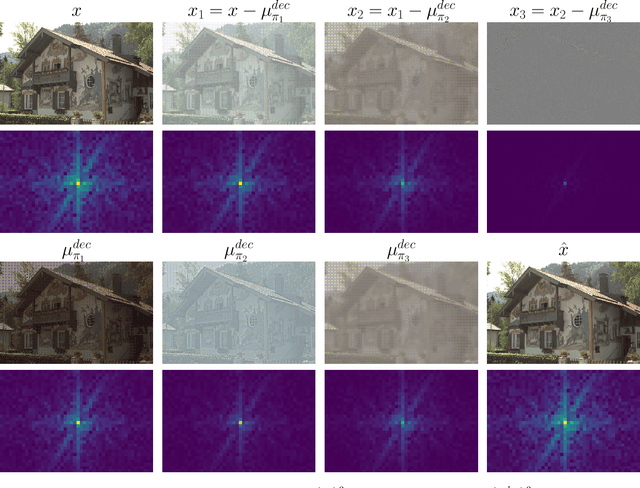
This paper introduces an end-to-end learned image compression system, termed ANFIC, based on Augmented Normalizing Flows (ANF). ANF is a new type of flow model, which stacks multiple variational autoencoders (VAE) for greater model expressiveness. The VAE-based image compression has gone mainstream, showing promising compression performance. Our work presents the first attempt to leverage VAE-based compression in a flow-based framework. ANFIC advances further compression efficiency by stacking and extending hierarchically multiple VAE's. The invertibility of ANF, together with our training strategies, enables ANFIC to support a wide range of quality levels without changing the encoding and decoding networks. Extensive experimental results show that in terms of PSNR-RGB, ANFIC performs comparably to or better than the state-of-the-art learned image compression. Moreover, it performs close to VVC intra coding, from low-rate compression up to nearly-lossless compression. In particular, ANFIC achieves the state-of-the-art performance, when extended with conditional convolution for variable rate compression with a single model.
FINED: Fast Inference Network for Edge Detection
Dec 15, 2020

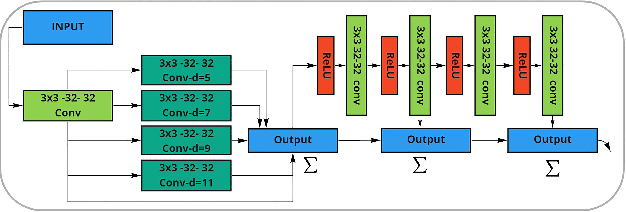

In this paper, we address the design of lightweight deep learning-based edge detection. The deep learning technology offers a significant improvement on the edge detection accuracy. However, typical neural network designs have very high model complexity, which prevents it from practical usage. In contrast, we propose a Fast Inference Network for Edge Detection (FINED), which is a lightweight neural net dedicated to edge detection. By carefully choosing proper components for edge detection purpose, we can achieve the state-of-the-art accuracy in edge detection while significantly reducing its complexity. Another key contribution in increasing the inferencing speed is introducing the training helper concept. The extra subnetworks (training helper) are employed in training but not used in inferencing. It can further reduce the model complexity and yet maintain the same level of accuracy. Our experiments show that our systems outperform all the current edge detectors at about the same model (parameter) size.
Learned Video Codec with Enriched Reconstruction for CLIC P-frame Coding
Dec 14, 2020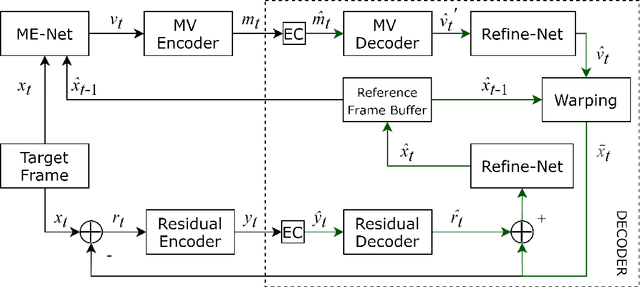
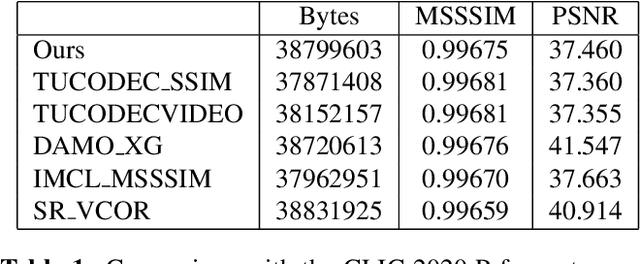

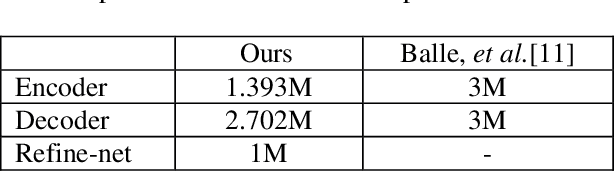
This paper proposes a learning-based video codec, specifically used for Challenge on Learned Image Compression (CLIC, CVPRWorkshop) 2020 P-frame coding. More specifically, we designed a compressor network with Refine-Net for coding residual signals and motion vectors. Also, for motion estimation, we introduced a hierarchical, attention-based ME-Net. To verify our design, we conducted an extensive ablation study on our modules and different input formats. Our video codec demonstrates its performance by using the perfect reference frame at the decoder side specified by the CLIC P-frame Challenge. The experimental result shows that our proposed codec is very competitive with the Challenge top performers in terms of quality metrics.
Traditional Method Inspired Deep Neural Network for Edge Detection
May 28, 2020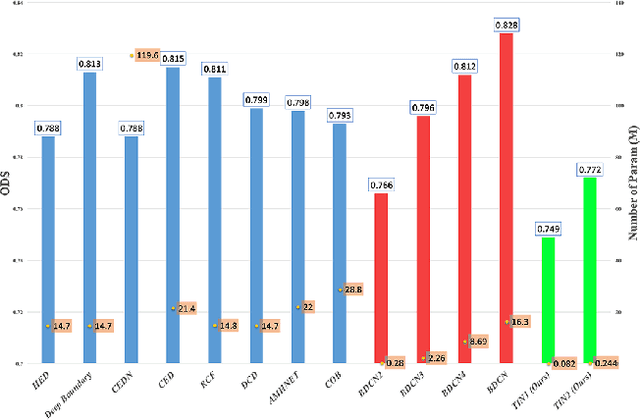
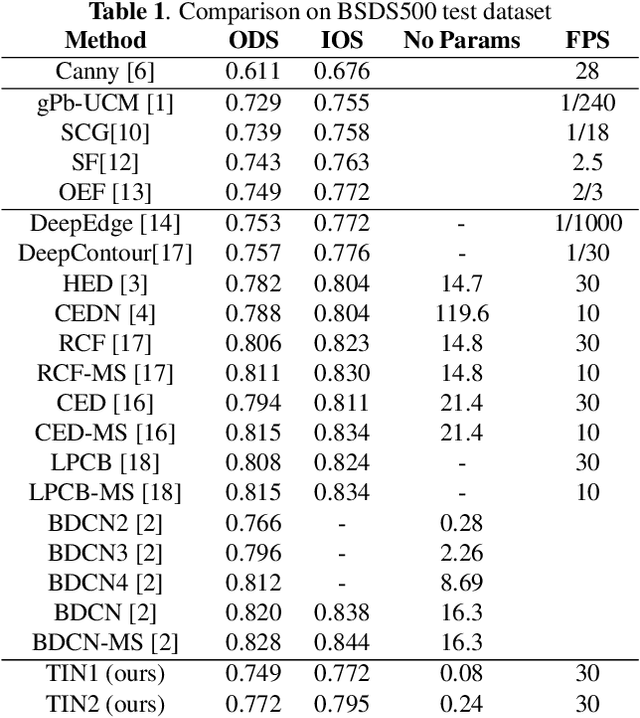

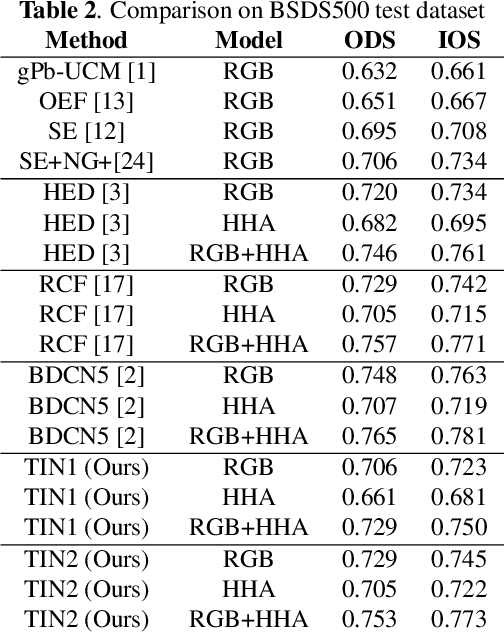
Recently, Deep-Neural-Network (DNN) based edge prediction is progressing fast. Although the DNN based schemes outperform the traditional edge detectors, they have much higher computational complexity. It could be that the DNN based edge detectors often adopt the neural net structures designed for high-level computer vision tasks, such as image segmentation and object recognition. Edge detection is a rather local and simple job, the over-complicated architecture and massive parameters may be unnecessary. Therefore, we propose a traditional method inspired framework to produce good edges with minimal complexity. We simplify the network architecture to include Feature Extractor, Enrichment, and Summarizer, which roughly correspond to gradient, low pass filter, and pixel connection in the traditional edge detection schemes. The proposed structure can effectively reduce the complexity and retain the edge prediction quality. Our TIN2 (Traditional Inspired Network) model has an accuracy higher than the recent BDCN2 (Bi-Directional Cascade Network) but with a smaller model.
Exploring Semantic Segmentation on the DCT Representation
Jul 23, 2019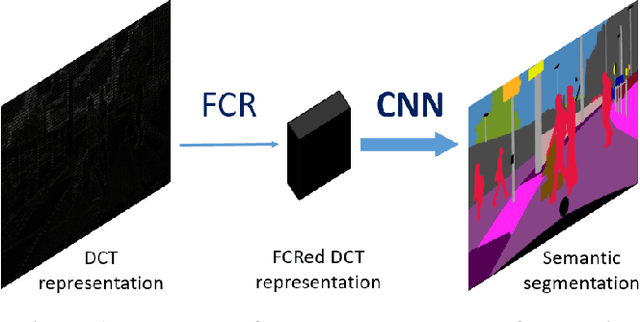
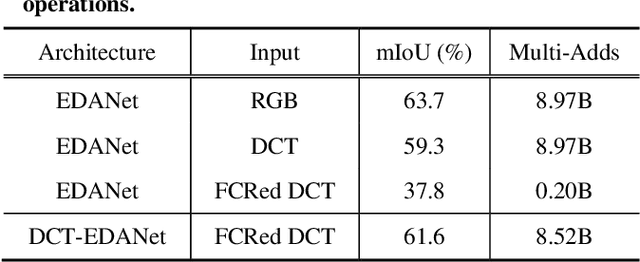
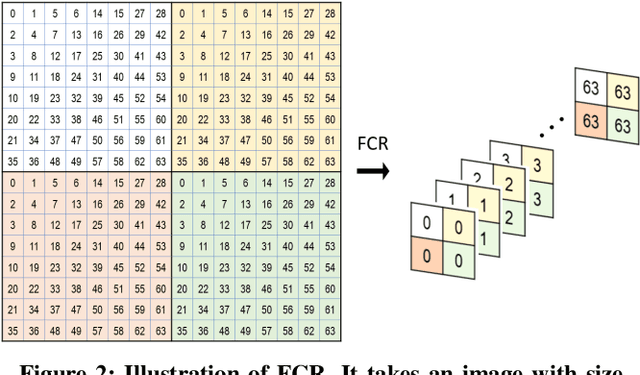

Typical convolutional networks are trained and conducted on RGB images. However, images are often compressed for memory savings and efficient transmission in real-world applications. In this paper, we explore methods for performing semantic segmentation on the discrete cosine transform (DCT) representation defined by the JPEG standard. We first rearrange the DCT coefficients to form a preferred input type, then we tailor an existing network to the DCT inputs. The proposed method has an accuracy close to the RGB model at about the same network complexity. Moreover, we investigate the impact of selecting different DCT components on segmentation performance. With a proper selection, one can achieve the same level accuracy using only 36% of the DCT coefficients. We further show the robustness of our method under quantization errors. To our knowledge, this paper is the first to explore semantic segmentation on the DCT representation.
Multi-Class Lane Semantic Segmentation using Efficient Convolutional Networks
Jul 22, 2019



Lane detection plays an important role in a self-driving vehicle. Several studies leverage a semantic segmentation network to extract robust lane features, but few of them can distinguish different types of lanes. In this paper, we focus on the problem of multi-class lane semantic segmentation. Based on the observation that the lane is a small-size and narrow-width object in a road scene image, we propose two techniques, Feature Size Selection (FSS) and Degressive Dilation Block (DD Block). The FSS allows a network to extract thin lane features using appropriate feature sizes. To acquire fine-grained spatial information, the DD Block is made of a series of dilated convolutions with degressive dilation rates. Experimental results show that the proposed techniques provide obvious improvement in accuracy, while they achieve the same or faster inference speed compared to the baseline system, and can run at real-time on high-resolution images.