 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskCRT: Masked Conditional Residual Transformer for Learned Video Compression
Dec 25, 2023Conditional coding has lately emerged as the mainstream approach to learned video compression. However, a recent study shows that it may perform worse than residual coding when the information bottleneck arises. Conditional residual coding was thus proposed, creating a new school of thought to improve on conditional coding. Notably, conditional residual coding relies heavily on the assumption that the residual frame has a lower entropy rate than that of the intra frame. Recognizing that this assumption is not always true due to dis-occlusion phenomena or unreliable motion estimates, we propose a masked conditional residual coding scheme. It learns a soft mask to form a hybrid of conditional coding and conditional residual coding in a pixel adaptive manner. We introduce a Transformer-based conditional autoencoder. Several strategies are investigated with regard to how to condition a Transformer-based autoencoder for inter-frame coding, a topic that is largely under-explored. Additionally, we propose a channel transform module (CTM) to decorrelate the image latents along the channel dimension, with the aim of using the simple hyperprior to approach similar compression performance to the channel-wise autoregressive model. Experimental results confirm the superiority of our masked conditional residual transformer (termed MaskCRT) to both conditional coding and conditional residual coding. On commonly used datasets, MaskCRT shows comparable BD-rate results to VTM-17.0 under the low delay P configuration in terms of PSNR-RGB. It also opens up a new research direction for advancing learned video compression.
Learned Hierarchical B-frame Coding with Adaptive Feature Modulation for YUV 4:2:0 Content
Dec 29, 2022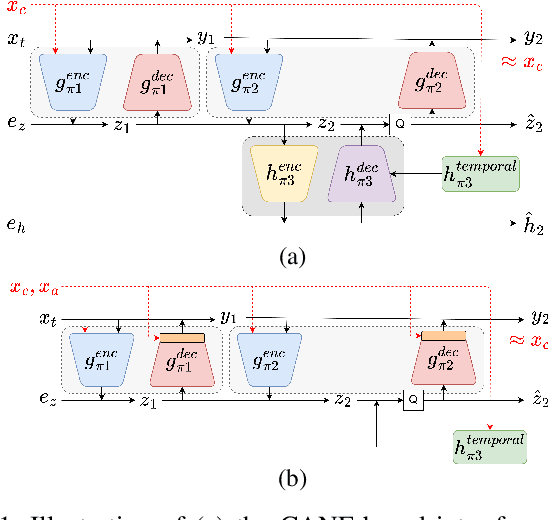
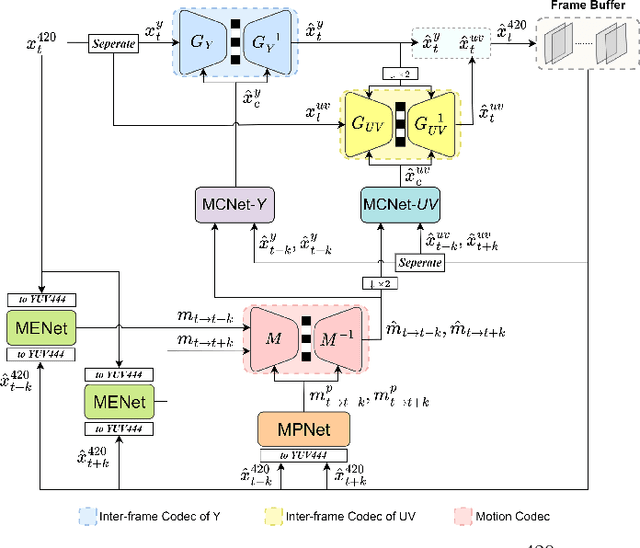
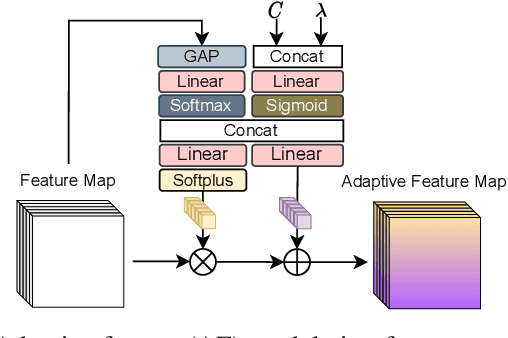

This paper introduces a learned hierarchical B-frame coding scheme in response to the Grand Challenge on Neural Network-based Video Coding at ISCAS 2023. We address specifically three issues, including (1) B-frame coding, (2) YUV 4:2:0 coding, and (3) content-adaptive variable-rate coding with only one single model. Most learned video codecs operate internally in the RGB domain for P-frame coding. B-frame coding for YUV 4:2:0 content is largely under-explored. In addition, while there have been prior works on variable-rate coding with conditional convolution, most of them fail to consider the content information. We build our scheme on conditional augmented normalized flows (CANF). It features conditional motion and inter-frame codecs for efficient B-frame coding. To cope with YUV 4:2:0 content, two conditional inter-frame codecs are used to process the Y and UV components separately, with the coding of the UV components conditioned additionally on the Y component. Moreover, we introduce adaptive feature modulation in every convolutional layer, taking into account both the content information and the coding levels of B-frames to achieve content-adaptive variable-rate coding. Experimental results show that our model outperforms x265 and the winner of last year's challenge on commonly used datasets in terms of PSNR-YUV.