 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Video Compression for YUV 4:2:0 Content Using Flow-based Conditional Inter-frame Coding
Oct 15, 2022
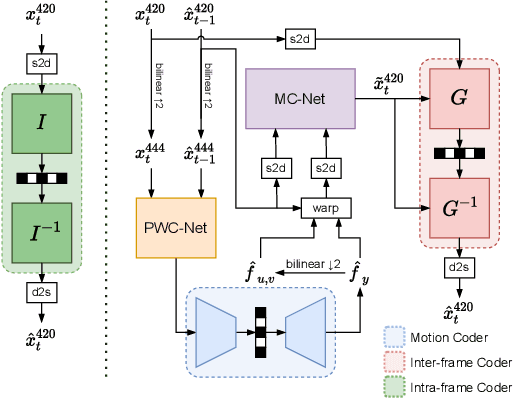
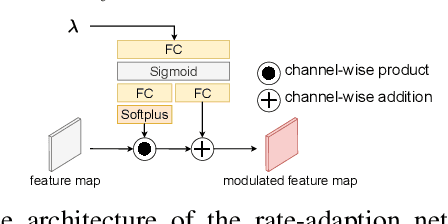
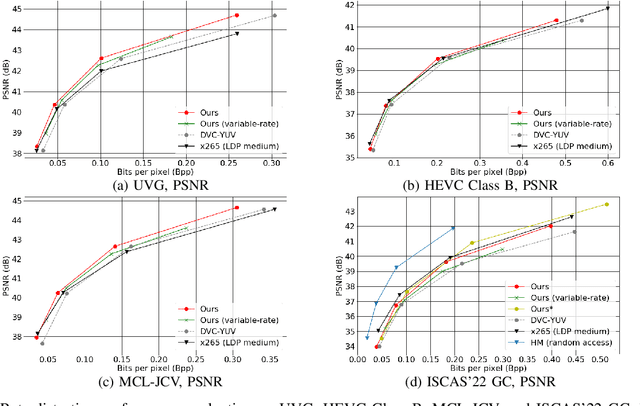
This paper proposes a learning-based video compression framework for variable-rate coding on YUV 4:2:0 content. Most existing learning-based video compression models adopt the traditional hybrid-based coding architecture, which involves temporal prediction followed by residual coding. However, recent studies have shown that residual coding is sub-optimal from the information-theoretic perspective. In addition, most existing models are optimized with respect to RGB content. Furthermore, they require separate models for variable-rate coding. To address these issues, this work presents an attempt to incorporate the conditional inter-frame coding for YUV 4:2:0 content. We introduce a conditional flow-based inter-frame coder to improve the inter-frame coding efficiency. To adapt our codec to YUV 4:2:0 content, we adopt a simple strategy of using space-to-depth and depth-to-space conversions. Lastly, we employ a rate-adaption net to achieve variable-rate coding without training multiple models. Experimental results show that our model performs better than x265 on UVG and MCL-JCV datasets in terms of PSNR-YUV. However, on the more challenging datasets from ISCAS'22 GC, there is still ample room for improvement. This insufficient performance is due to the lack of inter-frame coding capability at a large GOP size and can be mitigated by increasing the model capacity and applying an error propagation-aware training strategy.
B-CANF: Adaptive B-frame Coding with Conditional Augmented Normalizing Flows
Sep 05, 2022

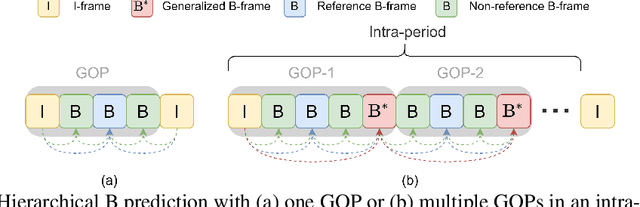

This work introduces a B-frame coding framework, termed B-CANF, that exploits conditional augmented normalizing flows for B-frame coding. Learned B-frame coding is less explored and more challenging. Motivated by recent advances in conditional P-frame coding, B-CANF is the first attempt at applying flow-based models to both conditional motion and inter-frame coding. B-CANF features frame-type adaptive coding that learns better bit allocation for hierarchical B-frame coding. B-CANF also introduces a special type of B-frame, called B*-frame, to mimic P-frame coding. On commonly used datasets, B-CANF achieves the state-of-the-art compression performance, showing comparable BD-rate results (in terms of PSNR-RGB) to HM-16.23 under the random access configuration.
CANF-VC: Conditional Augmented Normalizing Flows for Video Compression
Jul 18, 2022
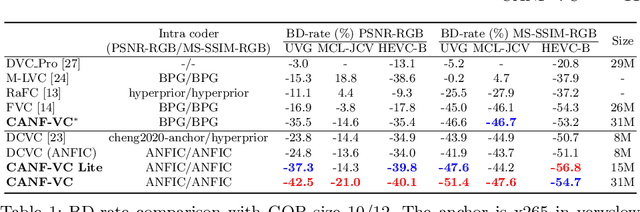

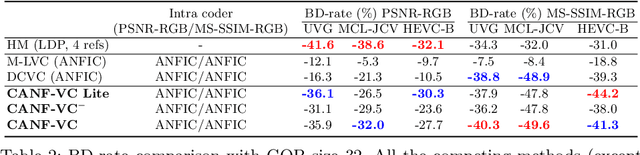
This paper presents an end-to-end learning-based video compression system, termed CANF-VC, based on conditional augmented normalizing flows (CANF). Most learned video compression systems adopt the same hybrid-based coding architecture as the traditional codecs. Recent research on conditional coding has shown the sub-optimality of the hybrid-based coding and opens up opportunities for deep generative models to take a key role in creating new coding frameworks. CANF-VC represents a new attempt that leverages the conditional ANF to learn a video generative model for conditional inter-frame coding. We choose ANF because it is a special type of generative model, which includes variational autoencoder as a special case and is able to achieve better expressiveness. CANF-VC also extends the idea of conditional coding to motion coding, forming a purely conditional coding framework. Extensive experimental results on commonly used datasets confirm the superiority of CANF-VC to the state-of-the-art methods. The source code of CANF-VC is available at https://github.com/NYCU-MAPL/CANF-VC.