 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical B-frame Video Coding Using Two-Layer CANF without Motion Coding
Apr 05, 2023Typical video compression systems consist of two main modules: motion coding and residual coding. This general architecture is adopted by classical coding schemes (such as international standards H.265 and H.266) and deep learning-based coding schemes. We propose a novel B-frame coding architecture based on two-layer Conditional Augmented Normalization Flows (CANF). It has the striking feature of not transmitting any motion information. Our proposed idea of video compression without motion coding offers a new direction for learned video coding. Our base layer is a low-resolution image compressor that replaces the full-resolution motion compressor. The low-resolution coded image is merged with the warped high-resolution images to generate a high-quality image as a conditioning signal for the enhancement-layer image coding in full resolution. One advantage of this architecture is significantly reduced computational complexity due to eliminating the motion information compressor. In addition, we adopt a skip-mode coding technique to reduce the transmitted latent samples. The rate-distortion performance of our scheme is slightly lower than that of the state-of-the-art learned B-frame coding scheme, B-CANF, but outperforms other learned B-frame coding schemes. However, compared to B-CANF, our scheme saves 45% of multiply-accumulate operations (MACs) for encoding and 27% of MACs for decoding. The code is available at https://nycu-clab.github.io.
Learned Video Codec with Enriched Reconstruction for CLIC P-frame Coding
Dec 14, 2020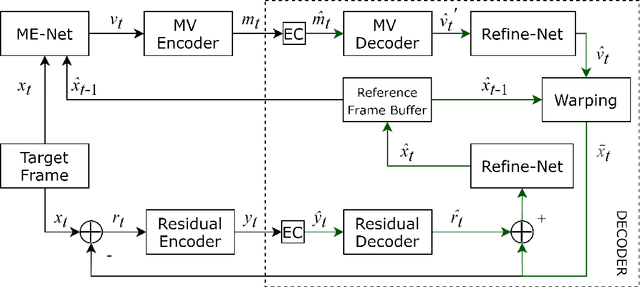
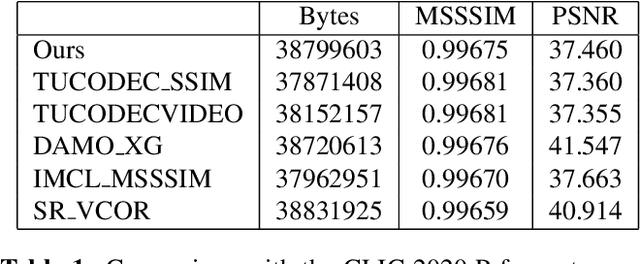

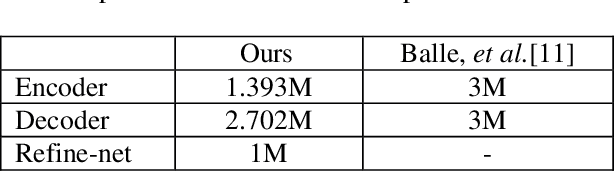
This paper proposes a learning-based video codec, specifically used for Challenge on Learned Image Compression (CLIC, CVPRWorkshop) 2020 P-frame coding. More specifically, we designed a compressor network with Refine-Net for coding residual signals and motion vectors. Also, for motion estimation, we introduced a hierarchical, attention-based ME-Net. To verify our design, we conducted an extensive ablation study on our modules and different input formats. Our video codec demonstrates its performance by using the perfect reference frame at the decoder side specified by the CLIC P-frame Challenge. The experimental result shows that our proposed codec is very competitive with the Challenge top performers in terms of quality metrics.
An Autoencoder-based Learned Image Compressor: Description of Challenge Proposal by NCTU
Feb 20, 2019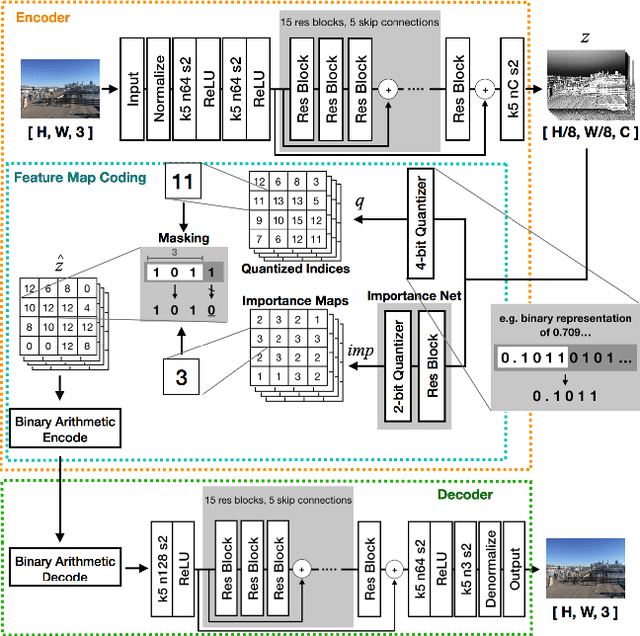
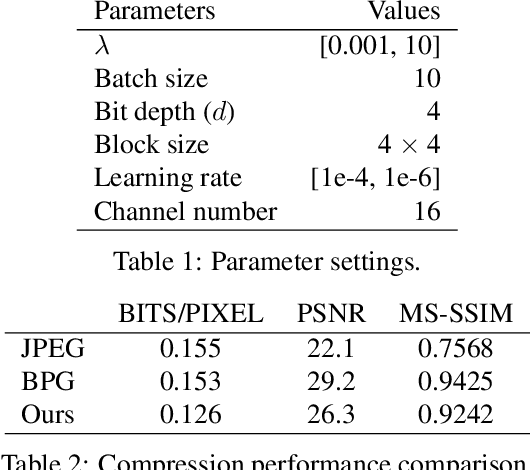

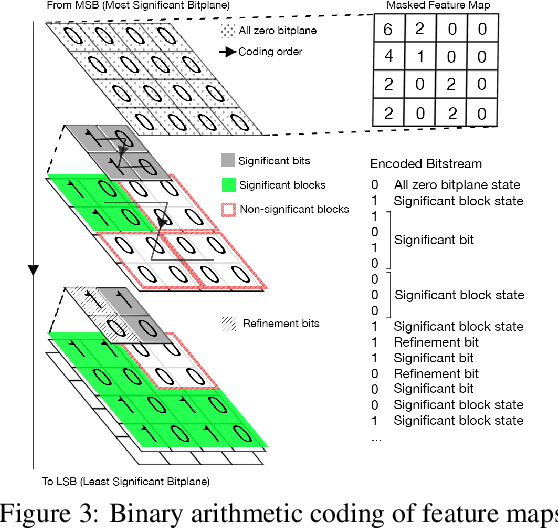
We propose a lossy image compression system using the deep-learning autoencoder structure to participate in the Challenge on Learned Image Compression (CLIC) 2018. Our autoencoder uses the residual blocks with skip connections to reduce the correlation among image pixels and condense the input image into a set of feature maps, a compact representation of the original image. The bit allocation and bitrate control are implemented by using the importance maps and quantizer. The importance maps are generated by a separate neural net in the encoder. The autoencoder and the importance net are trained jointly based on minimizing a weighted sum of mean squared error, MS-SSIM, and a rate estimate. Our aim is to produce reconstructed images with good subjective quality subject to the 0.15 bits-per-pixel constraint.