 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Fusion for Robust Patch Matching With Compact Binary Descriptors
Jan 11, 2019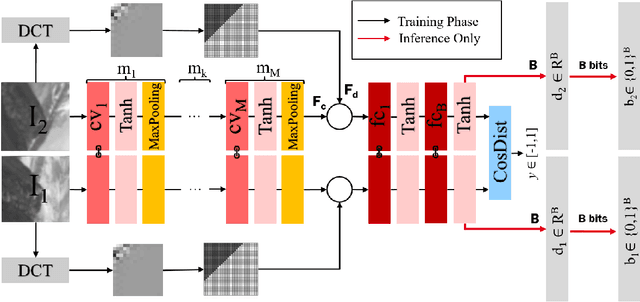

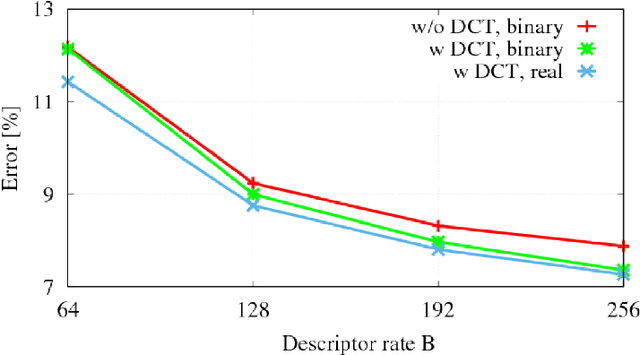
This work addresses the problem of learning compact yet discriminative patch descriptors within a deep learning framework. We observe that features extracted by convolutional layers in the pixel domain are largely complementary to features extracted in a transformed domain. We propose a convolutional network framework for learning binary patch descriptors where pixel domain features are fused with features extracted from the transformed domain. In our framework, while convolutional and transformed features are distinctly extracted, they are fused and provided to a single classifier which thus jointly operates on convolutional and transformed features. We experiment at matching patches from three different datasets, showing that our feature fusion approach outperforms multiple state-of-the-art approaches in terms of accuracy, rate, and complexity.
Learning Sparse Neural Networks via Sensitivity-Driven Regularization
Oct 28, 2018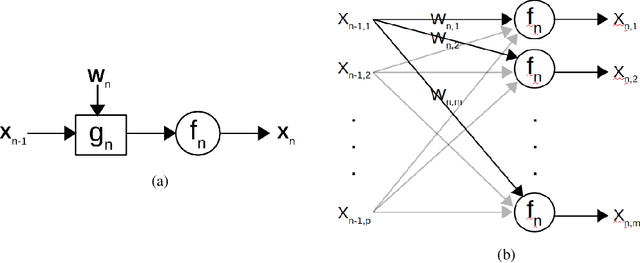
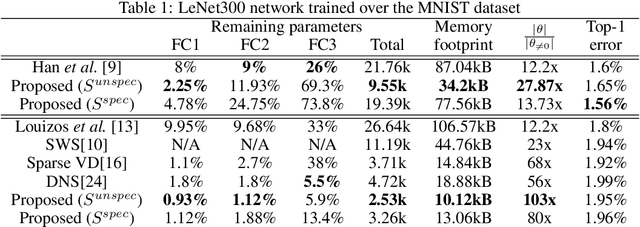
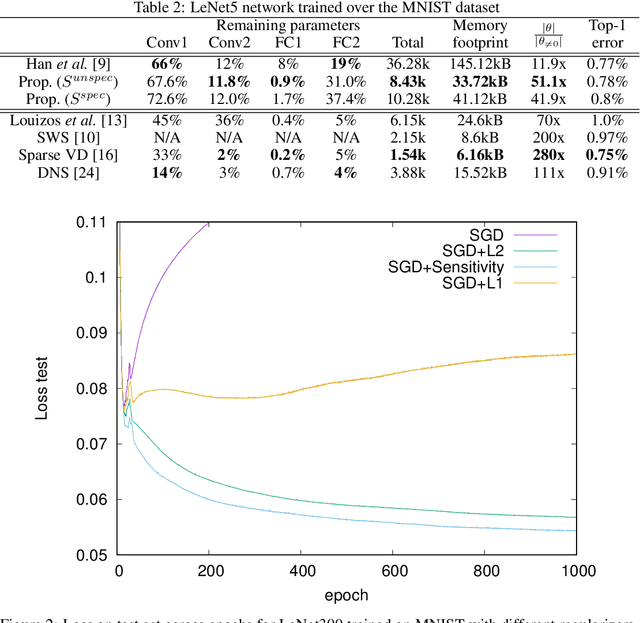

The ever-increasing number of parameters in deep neural networks poses challenges for memory-limited applications. Regularize-and-prune methods aim at meeting these challenges by sparsifying the network weights. In this context we quantify the output sensitivity to the parameters (i.e. their relevance to the network output) and introduce a regularization term that gradually lowers the absolute value of parameters with low sensitivity. Thus, a very large fraction of the parameters approach zero and are eventually set to zero by simple thresholding. Our method surpasses most of the recent techniques both in terms of sparsity and error rates. In some cases, the method reaches twice the sparsity obtained by other techniques at equal error rates.
Fast Training of Convolutional Neural Networks via Kernel Rescaling
Oct 12, 2016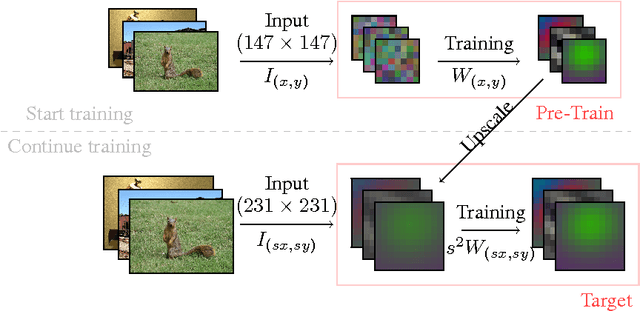
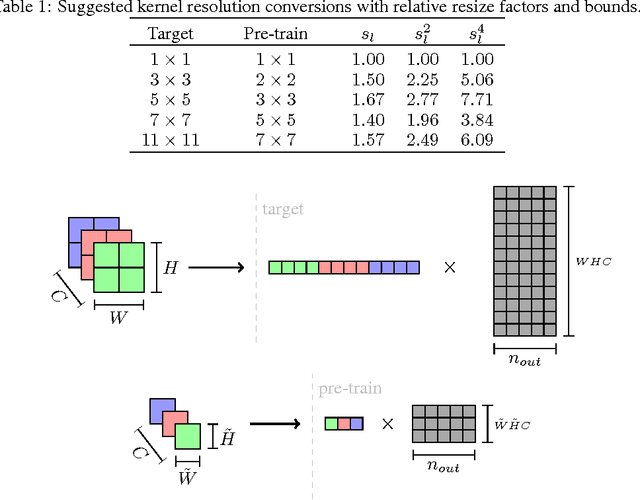

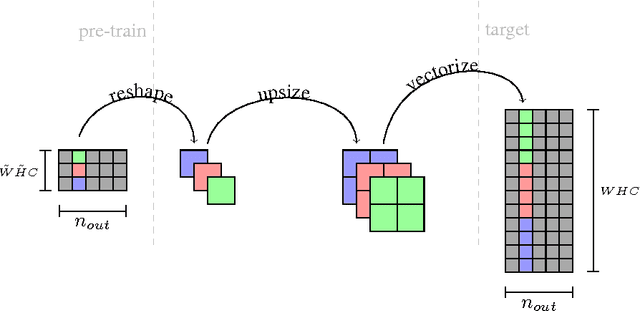
Training deep Convolutional Neural Networks (CNN) is a time consuming task that may take weeks to complete. In this article we propose a novel, theoretically founded method for reducing CNN training time without incurring any loss in accuracy. The basic idea is to begin training with a pre-train network using lower-resolution kernels and input images, and then refine the results at the full resolution by exploiting the spatial scaling property of convolutions. We apply our method to the ImageNet winner OverFeat and to the more recent ResNet architecture and show a reduction in training time of nearly 20% while test set accuracy is preserved in both cases.