 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrub of a thousand faces: an individual segmentation from satellite images using deep learning
Jan 31, 2024



Monitoring the distribution and size structure of long-living shrubs, such as Juniperus communis, can be used to estimate the long-term effects of climate change on high-mountain and high latitude ecosystems. Historical aerial very-high resolution imagery offers a retrospective tool to monitor shrub growth and distribution at high precision. Currently, deep learning models provide impressive results for detecting and delineating the contour of objects with defined shapes. However, adapting these models to detect natural objects that express complex growth patterns, such as junipers, is still a challenging task. This research presents a novel approach that leverages remotely sensed RGB imagery in conjunction with Mask R-CNN-based instance segmentation models to individually delineate Juniperus shrubs above the treeline in Sierra Nevada (Spain). In this study, we propose a new data construction design that consists in using photo interpreted (PI) and field work (FW) data to respectively develop and externally validate the model. We also propose a new shrub-tailored evaluation algorithm based on a new metric called Multiple Intersections over Ground Truth Area (MIoGTA) to assess and optimize the model shrub delineation performance. Finally, we deploy the developed model for the first time to generate a wall-to-wall map of Juniperus individuals. The experimental results demonstrate the efficiency of our dual data construction approach in overcoming the limitations associated with traditional field survey methods. They also highlight the robustness of MIoGTA metric in evaluating instance segmentation models on species with complex growth patterns showing more resilience against data annotation uncertainty. Furthermore, they show the effectiveness of employing Mask R-CNN with ResNet101-C4 backbone in delineating PI and FW shrubs, achieving an F1-score of 87,87% and 76.86%, respectively.
Deep Learning for blind spectral unmixing of LULC classes with MODIS multispectral time series and ancillary data
Oct 11, 2023



Remotely sensed data are dominated by mixed Land Use and Land Cover (LULC) types. Spectral unmixing is a technique to extract information from mixed pixels into their constituent LULC types and corresponding abundance fractions. Traditionally, solving this task has relied on either classical methods that require prior knowledge of endmembers or machine learning methods that avoid explicit endmembers calculation, also known as blind spectral unmixing (BSU). Most BSU studies based on Deep Learning (DL) focus on one time-step hyperspectral data, yet its acquisition remains quite costly compared with multispectral data. To our knowledge, here we provide the first study on BSU of LULC classes using multispectral time series data with DL models. We further boost the performance of a Long-Short Term Memory (LSTM)-based model by incorporating geographic plus topographic (geo-topographic) and climatic ancillary information. Our experiments show that combining spectral-temporal input data together with geo-topographic and climatic information substantially improves the abundance estimation of LULC classes in mixed pixels. To carry out this study, we built a new labeled dataset of the region of Andalusia (Spain) with monthly multispectral time series of pixels for the year 2013 from MODIS at 460m resolution, for two hierarchical levels of LULC classes, named Andalusia MultiSpectral MultiTemporal Unmixing (Andalusia-MSMTU). This dataset provides, at the pixel level, a multispectral time series plus ancillary information annotated with the abundance of each LULC class inside each pixel. The dataset and code are available to the public.
What is the best RNN-cell structure for forecasting each time series behavior?
Mar 15, 2022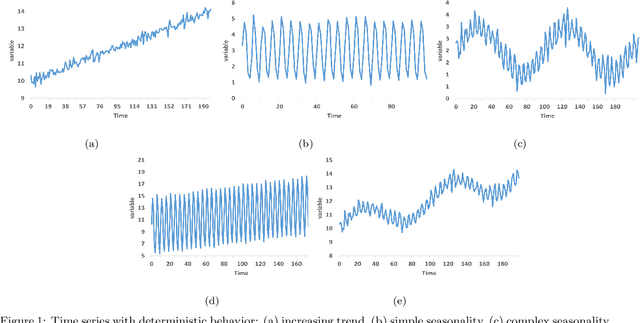

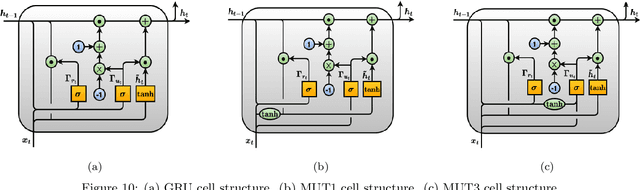

It is unquestionable that time series forecasting is of paramount importance in many fields. The most used machine learning models to address time series forecasting tasks are Recurrent Neural Networks (RNNs). Typically, those models are built using one of the three most popular cells, ELMAN, Long-Short Term Memory (LSTM), or Gated Recurrent Unit (GRU) cells, each cell has a different structure and implies a different computational cost. However, it is not clear why and when to use each RNN-cell structure. Actually, there is no comprehensive characterization of all the possible time series behaviors and no guidance on what RNN cell structure is the most suitable for each behavior. The objective of this study is two-fold: it presents a comprehensive taxonomy of all-time series behaviors (deterministic, random-walk, nonlinear, long-memory, and chaotic), and provides insights into the best RNN cell structure for each time series behavior. We conducted two experiments: (1) The first experiment evaluates and analyzes the role of each component in the LSTM-Vanilla cell by creating 11 variants based on one alteration in its basic architecture (removing, adding, or substituting one cell component). (2) The second experiment evaluates and analyzes the performance of 20 possible RNN-cell structures. Our results showed that the MGU-SLIM3 cell is the most recommended for deterministic and nonlinear behaviors, the MGU-SLIM2 cell is the most suitable for random-walk behavior, FB1 cell is advocated for long-memory behavior, and LSTM-SLIM1 for chaotic behavior.
MULTICAST: MULTI Confirmation-level Alarm SysTem based on CNN and LSTM to mitigate false alarms for handgun detection in video-surveillance
May 03, 2021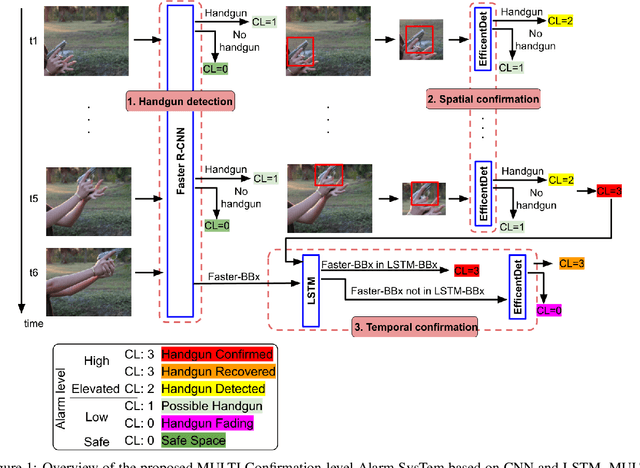
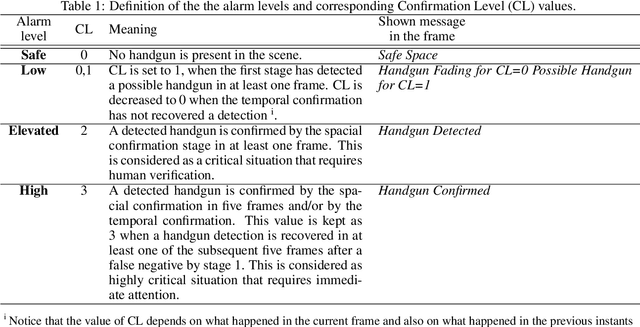
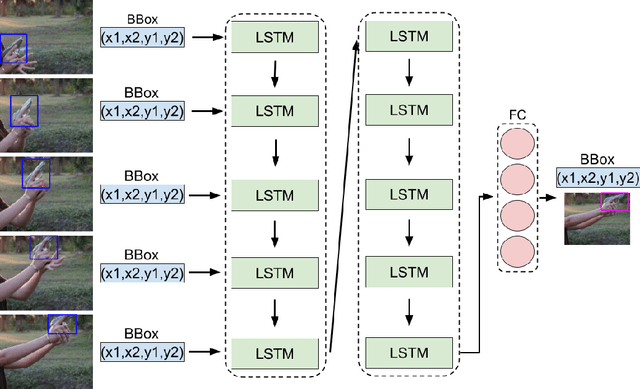
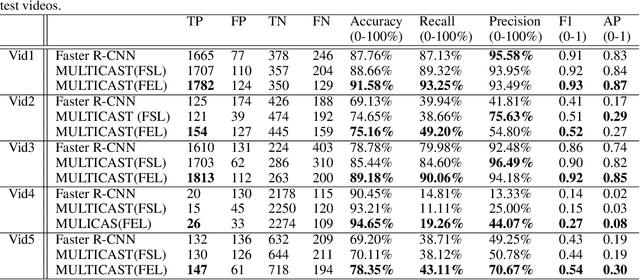
Despite the constant advances in computer vision, integrating modern single-image detectors in real-time handgun alarm systems in video-surveillance is still debatable. Using such detectors still implies a high number of false alarms and false negatives. In this context, most existent studies select one of the latest single-image detectors and train it on a better dataset or use some pre-processing, post-processing or data-fusion approach to further reduce false alarms. However, none of these works tried to exploit the temporal information present in the videos to mitigate false detections. This paper presents a new system, called MULTI Confirmation-level Alarm SysTem based on Convolutional Neural Networks (CNN) and Long Short Term Memory networks (LSTM) (MULTICAST), that leverages not only the spacial information but also the temporal information existent in the videos for a more reliable handgun detection. MULTICAST consists of three stages, i) a handgun detection stage, ii) a CNN-based spacial confirmation stage and iii) LSTM-based temporal confirmation stage. The temporal confirmation stage uses the positions of the detected handgun in previous instants to predict its trajectory in the next frame. Our experiments show that MULTICAST reduces by 80% the number of false alarms with respect to Faster R-CNN based-single-image detector, which makes it more useful in providing more effective and rapid security responses.
EXplainable Neural-Symbolic Learning (X-NeSyL) methodology to fuse deep learning representations with expert knowledge graphs: the MonuMAI cultural heritage use case
Apr 24, 2021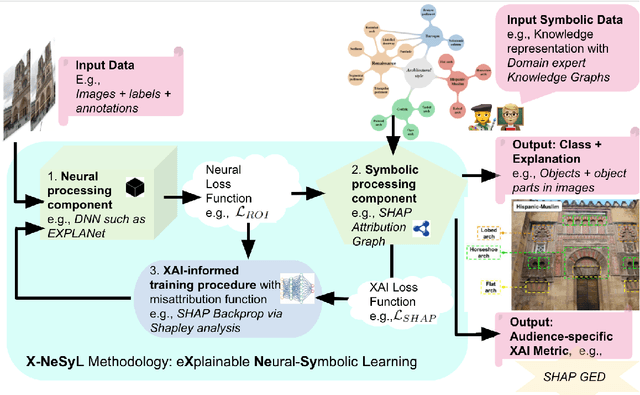
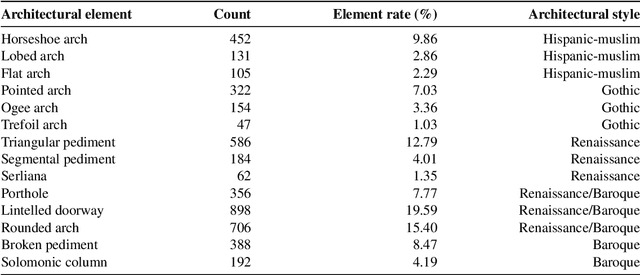


The latest Deep Learning (DL) models for detection and classification have achieved an unprecedented performance over classical machine learning algorithms. However, DL models are black-box methods hard to debug, interpret, and certify. DL alone cannot provide explanations that can be validated by a non technical audience. In contrast, symbolic AI systems that convert concepts into rules or symbols -- such as knowledge graphs -- are easier to explain. However, they present lower generalisation and scaling capabilities. A very important challenge is to fuse DL representations with expert knowledge. One way to address this challenge, as well as the performance-explainability trade-off is by leveraging the best of both streams without obviating domain expert knowledge. We tackle such problem by considering the symbolic knowledge is expressed in form of a domain expert knowledge graph. We present the eXplainable Neural-symbolic learning (X-NeSyL) methodology, designed to learn both symbolic and deep representations, together with an explainability metric to assess the level of alignment of machine and human expert explanations. The ultimate objective is to fuse DL representations with expert domain knowledge during the learning process to serve as a sound basis for explainability. X-NeSyL methodology involves the concrete use of two notions of explanation at inference and training time respectively: 1) EXPLANet: Expert-aligned eXplainable Part-based cLAssifier NETwork Architecture, a compositional CNN that makes use of symbolic representations, and 2) SHAP-Backprop, an explainable AI-informed training procedure that guides the DL process to align with such symbolic representations in form of knowledge graphs. We showcase X-NeSyL methodology using MonuMAI dataset for monument facade image classification, and demonstrate that our approach improves explainability and performance.
Lights and Shadows in Evolutionary Deep Learning: Taxonomy, Critical Methodological Analysis, Cases of Study, Learned Lessons, Recommendations and Challenges
Aug 09, 2020
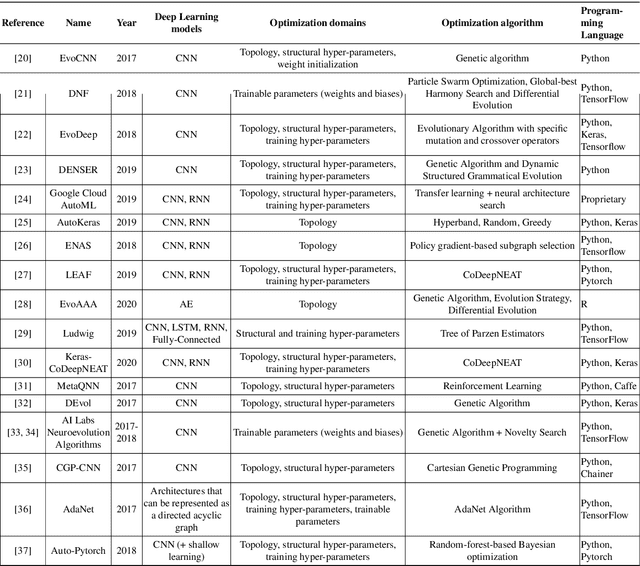
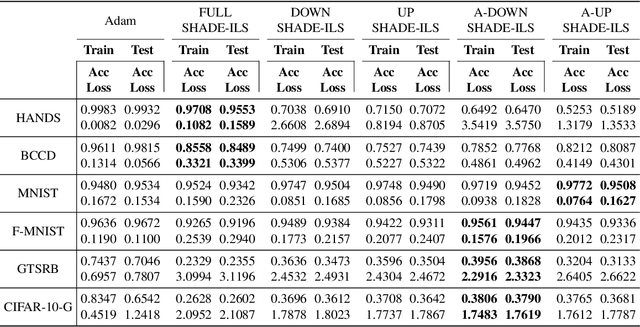
Much has been said about the fusion of bio-inspired optimization algorithms and Deep Learning models for several purposes: from the discovery of network topologies and hyper-parametric configurations with improved performance for a given task, to the optimization of the model's parameters as a replacement for gradient-based solvers. Indeed, the literature is rich in proposals showcasing the application of assorted nature-inspired approaches for these tasks. In this work we comprehensively review and critically examine contributions made so far based on three axes, each addressing a fundamental question in this research avenue: a) optimization and taxonomy (Why?), including a historical perspective, definitions of optimization problems in Deep Learning, and a taxonomy associated with an in-depth analysis of the literature, b) critical methodological analysis (How?), which together with two case studies, allows us to address learned lessons and recommendations for good practices following the analysis of the literature, and c) challenges and new directions of research (What can be done, and what for?). In summary, three axes - optimization and taxonomy, critical analysis, and challenges - which outline a complete vision of a merger of two technologies drawing up an exciting future for this area of fusion research.
FuCiTNet: Improving the generalization of deep learning networks by the fusion of learned class-inherent transformations
May 17, 2020

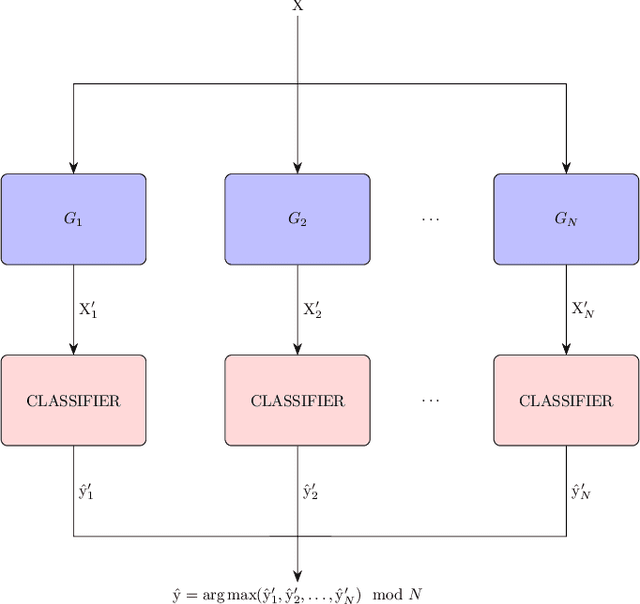
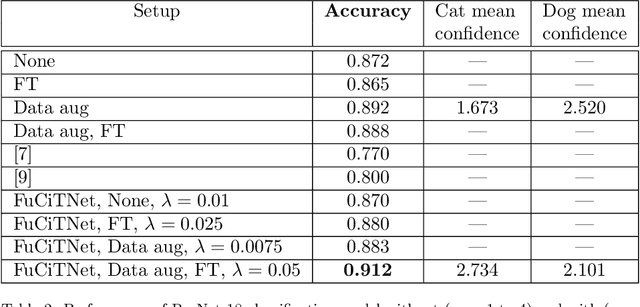
It is widely known that very small datasets produce overfitting in Deep Neural Networks (DNNs), i.e., the network becomes highly biased to the data it has been trained on. This issue is often alleviated using transfer learning, regularization techniques and/or data augmentation. This work presents a new approach, independent but complementary to the previous mentioned techniques, for improving the generalization of DNNs on very small datasets in which the involved classes share many visual features. The proposed methodology, called FuCiTNet (Fusion Class inherent Transformations Network), inspired by GANs, creates as many generators as classes in the problem. Each generator, $k$, learns the transformations that bring the input image into the k-class domain. We introduce a classification loss in the generators to drive the leaning of specific k-class transformations. Our experiments demonstrate that the proposed transformations improve the generalization of the classification model in three diverse datasets.
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
Oct 22, 2019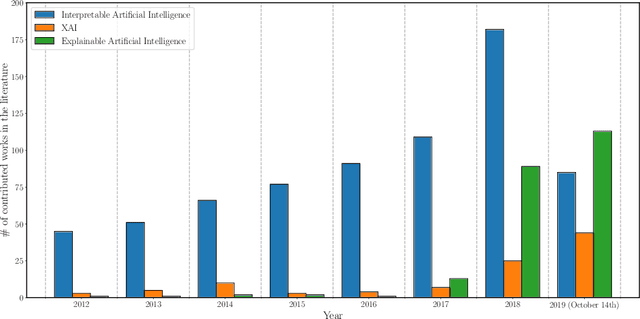
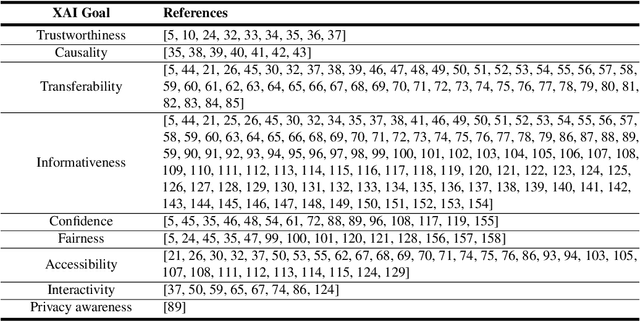
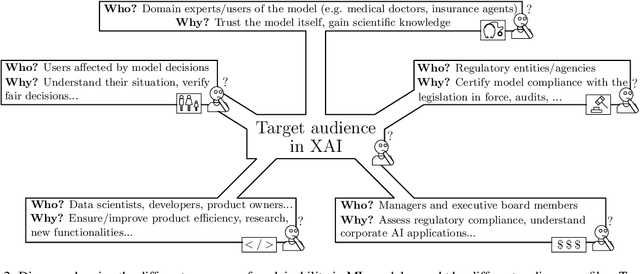

In the last years, Artificial Intelligence (AI) has achieved a notable momentum that may deliver the best of expectations over many application sectors across the field. For this to occur, the entire community stands in front of the barrier of explainability, an inherent problem of AI techniques brought by sub-symbolism (e.g. ensembles or Deep Neural Networks) that were not present in the last hype of AI. Paradigms underlying this problem fall within the so-called eXplainable AI (XAI) field, which is acknowledged as a crucial feature for the practical deployment of AI models. This overview examines the existing literature in the field of XAI, including a prospect toward what is yet to be reached. We summarize previous efforts to define explainability in Machine Learning, establishing a novel definition that covers prior conceptual propositions with a major focus on the audience for which explainability is sought. We then propose and discuss about a taxonomy of recent contributions related to the explainability of different Machine Learning models, including those aimed at Deep Learning methods for which a second taxonomy is built. This literature analysis serves as the background for a series of challenges faced by XAI, such as the crossroads between data fusion and explainability. Our prospects lead toward the concept of Responsible Artificial Intelligence, namely, a methodology for the large-scale implementation of AI methods in real organizations with fairness, model explainability and accountability at its core. Our ultimate goal is to provide newcomers to XAI with a reference material in order to stimulate future research advances, but also to encourage experts and professionals from other disciplines to embrace the benefits of AI in their activity sectors, without any prior bias for its lack of interpretability.
Deep Learning in Video Multi-Object Tracking: A Survey
Jul 31, 2019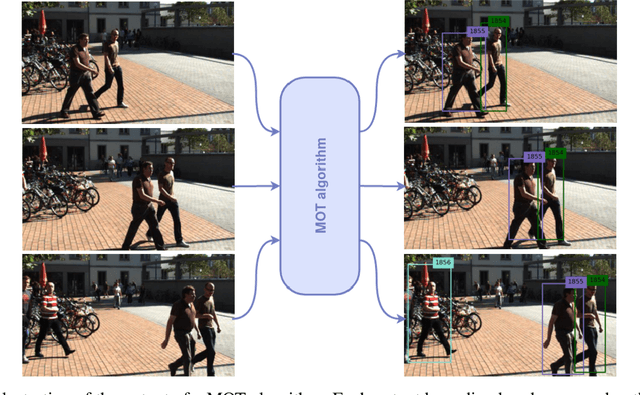
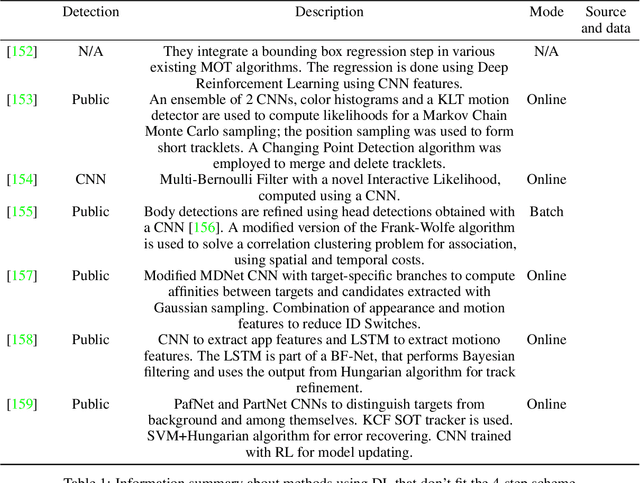
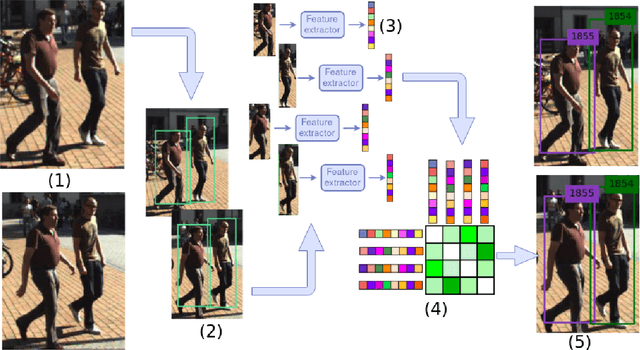
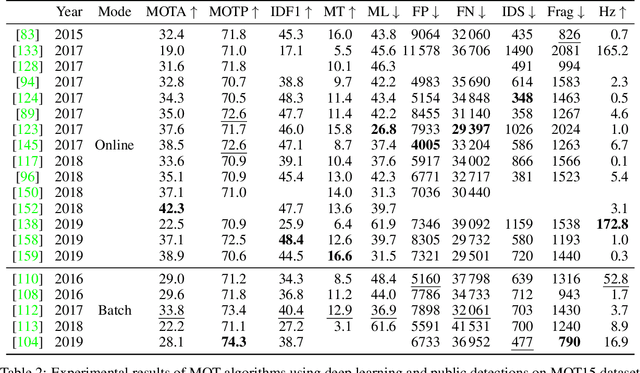
The problem of Multiple Object Tracking (MOT) consists in following the trajectory of different objects in a sequence, usually a video. In recent years, with the rise of Deep Learning, the algorithms that provide a solution to this problem have benefited from the representational power of deep models. This paper provides a comprehensive survey on works that employ Deep Learning models to solve the task of MOT on single-camera videos. Four main steps in MOT algorithms are identified, and an in-depth review of how Deep Learning was employed in each one of these stages is presented. A complete experimental comparison of the presented works on the three MOTChallenge datasets is also provided, identifying a number of similarities among the top-performing methods and presenting some possible future research directions.
Towards Highly Accurate Coral Texture Images Classification Using Deep Convolutional Neural Networks and Data Augmentation
Mar 27, 2018
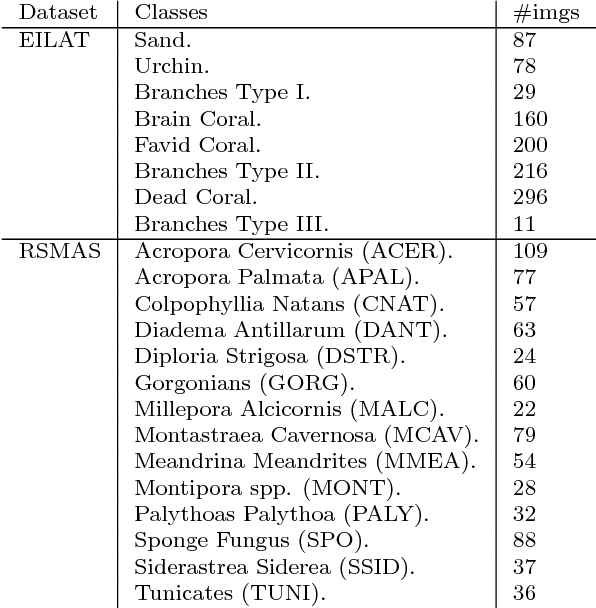
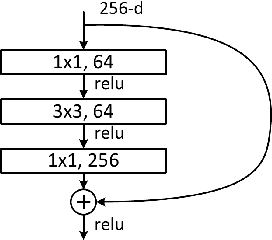

The recognition of coral species based on underwater texture images pose a significant difficulty for machine learning algorithms, due to the three following challenges embedded in the nature of this data: 1) datasets do not include information about the global structure of the coral; 2) several species of coral have very similar characteristics; and 3) defining the spatial borders between classes is difficult as many corals tend to appear together in groups. For this reason, the classification of coral species has always required an aid from a domain expert. The objective of this paper is to develop an accurate classification model for coral texture images. Current datasets contain a large number of imbalanced classes, while the images are subject to inter-class variation. We have analyzed 1) several Convolutional Neural Network (CNN) architectures, 2) data augmentation techniques and 3) transfer learning. We have achieved the state-of-the art accuracies using different variations of ResNet on the two current coral texture datasets, EILAT and RSMAS.