 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Normed k-Means: A Paradigm-Shift in Clustering within Probabilistic Metric Spaces
Apr 04, 2025Existing approaches remain largely constrained by traditional distance metrics, limiting their effectiveness in handling random data. In this work, we introduce the first k-means variant in the literature that operates within a probabilistic metric space, replacing conventional distance measures with a well-defined distance distribution function. This pioneering approach enables more flexible and robust clustering in both deterministic and random datasets, establishing a new foundation for clustering in stochastic environments. By adopting a probabilistic perspective, our method not only introduces a fresh paradigm but also establishes a rigorous theoretical framework that is expected to serve as a key reference for future clustering research involving random data. Extensive experiments on diverse real and synthetic datasets assess our model's effectiveness using widely recognized evaluation metrics, including Silhouette, Davies-Bouldin, Calinski Harabasz, the adjusted Rand index, and distortion. Comparative analyses against established methods such as k-means++, fuzzy c-means, and kernel probabilistic k-means demonstrate the superior performance of our proposed random normed k-means (RNKM) algorithm. Notably, RNKM exhibits a remarkable ability to identify nonlinearly separable structures, making it highly effective in complex clustering scenarios. These findings position RNKM as a groundbreaking advancement in clustering research, offering a powerful alternative to traditional techniques while addressing a long-standing gap in the literature. By bridging probabilistic metrics with clustering, this study provides a foundational reference for future developments and opens new avenues for advanced data analysis in dynamic, data-driven applications.
Introducing the Short-Time Fourier Kolmogorov Arnold Network: A Dynamic Graph CNN Approach for Tree Species Classification in 3D Point Clouds
Apr 01, 2025Accurate classification of tree species based on Terrestrial Laser Scanning (TLS) and Airborne Laser Scanning (ALS) is essential for biodiversity conservation. While advanced deep learning models for 3D point cloud classification have demonstrated strong performance in this domain, their high complexity often hinders the development of efficient, low-computation architectures. In this paper, we introduce STFT-KAN, a novel Kolmogorov-Arnold network that integrates the Short-Time Fourier Transform (STFT), which can replace the standard linear layer with activation. We implemented STFT-KAN within a lightweight version of DGCNN, called liteDGCNN, to classify tree species using the TLS data. Our experiments show that STFT-KAN outperforms existing KAN variants by effectively balancing model complexity and performance with parameter count reduction, achieving competitive results compared to MLP-based models. Additionally, we evaluated a hybrid architecture that combines MLP in edge convolution with STFT-KAN in other layers, achieving comparable performance to MLP models while reducing the parameter count by 50% and 75% compared to other KAN-based variants. Furthermore, we compared our model to leading 3D point cloud learning approaches, demonstrating that STFT-KAN delivers competitive results compared to the state-of-the-art method PointMLP lite with an 87% reduction in parameter count.
Sentiment Analysis in SemEval: A Review of Sentiment Identification Approaches
Mar 13, 2025Social media platforms are becoming the foundations of social interactions including messaging and opinion expression. In this regard, Sentiment Analysis techniques focus on providing solutions to ensure the retrieval and analysis of generated data including sentiments, emotions, and discussed topics. International competitions such as the International Workshop on Semantic Evaluation (SemEval) have attracted many researchers and practitioners with a special research interest in building sentiment analysis systems. In our work, we study top-ranking systems for each SemEval edition during the 2013-2021 period, a total of 658 teams participated in these editions with increasing interest over years. We analyze the proposed systems marking the evolution of research trends with a focus on the main components of sentiment analysis systems including data acquisition, preprocessing, and classification. Our study shows an active use of preprocessing techniques, an evolution of features engineering and word representation from lexicon-based approaches to word embeddings, and the dominance of neural networks and transformers over the classification phase fostering the use of ready-to-use models. Moreover, we provide researchers with insights based on experimented systems which will allow rapid prototyping of new systems and help practitioners build for future SemEval editions.
LSTM based models stability in the context of Sentiment Analysis for social media
Nov 21, 2022
Deep learning techniques have proven their effectiveness for Sentiment Analysis (SA) related tasks. Recurrent neural networks (RNN), especially Long Short-Term Memory (LSTM) and Bidirectional LSTM, have become a reference for building accurate predictive models. However, the models complexity and the number of hyperparameters to configure raises several questions related to their stability. In this paper, we present various LSTM models and their key parameters, and we perform experiments to test the stability of these models in the context of Sentiment Analysis.
What is the best RNN-cell structure for forecasting each time series behavior?
Mar 15, 2022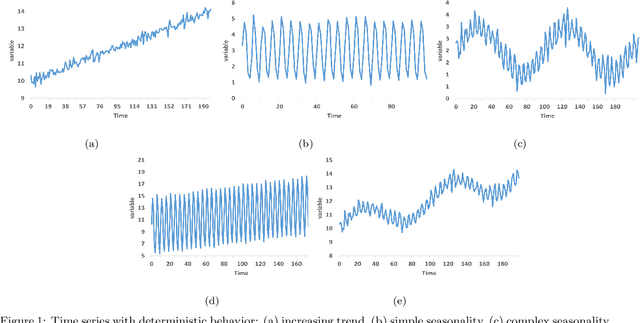

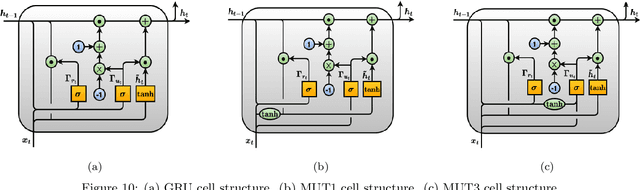

It is unquestionable that time series forecasting is of paramount importance in many fields. The most used machine learning models to address time series forecasting tasks are Recurrent Neural Networks (RNNs). Typically, those models are built using one of the three most popular cells, ELMAN, Long-Short Term Memory (LSTM), or Gated Recurrent Unit (GRU) cells, each cell has a different structure and implies a different computational cost. However, it is not clear why and when to use each RNN-cell structure. Actually, there is no comprehensive characterization of all the possible time series behaviors and no guidance on what RNN cell structure is the most suitable for each behavior. The objective of this study is two-fold: it presents a comprehensive taxonomy of all-time series behaviors (deterministic, random-walk, nonlinear, long-memory, and chaotic), and provides insights into the best RNN cell structure for each time series behavior. We conducted two experiments: (1) The first experiment evaluates and analyzes the role of each component in the LSTM-Vanilla cell by creating 11 variants based on one alteration in its basic architecture (removing, adding, or substituting one cell component). (2) The second experiment evaluates and analyzes the performance of 20 possible RNN-cell structures. Our results showed that the MGU-SLIM3 cell is the most recommended for deterministic and nonlinear behaviors, the MGU-SLIM2 cell is the most suitable for random-walk behavior, FB1 cell is advocated for long-memory behavior, and LSTM-SLIM1 for chaotic behavior.