 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTOOD-X methodology: using statistical nonparametric test for OOD Detection Large-Scale datasets enhanced with explainability
Apr 03, 2025Out-of-Distribution (OOD) detection is a critical task in machine learning, particularly in safety-sensitive applications where model failures can have serious consequences. However, current OOD detection methods often suffer from restrictive distributional assumptions, limited scalability, and a lack of interpretability. To address these challenges, we propose STOOD-X, a two-stage methodology that combines a Statistical nonparametric Test for OOD Detection with eXplainability enhancements. In the first stage, STOOD-X uses feature-space distances and a Wilcoxon-Mann-Whitney test to identify OOD samples without assuming a specific feature distribution. In the second stage, it generates user-friendly, concept-based visual explanations that reveal the features driving each decision, aligning with the BLUE XAI paradigm. Through extensive experiments on benchmark datasets and multiple architectures, STOOD-X achieves competitive performance against state-of-the-art post hoc OOD detectors, particularly in high-dimensional and complex settings. In addition, its explainability framework enables human oversight, bias detection, and model debugging, fostering trust and collaboration between humans and AI systems. The STOOD-X methodology therefore offers a robust, explainable, and scalable solution for real-world OOD detection tasks.
Local Attention Mechanism: Boosting the Transformer Architecture for Long-Sequence Time Series Forecasting
Oct 04, 2024

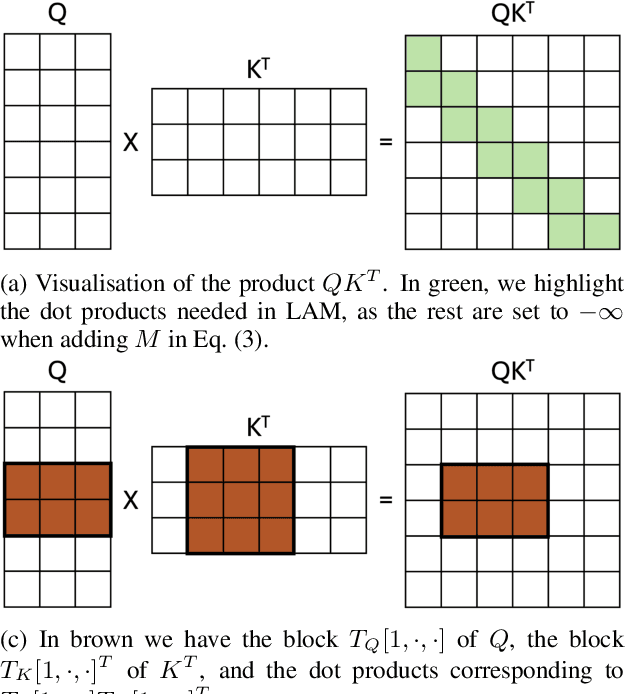

Transformers have become the leading choice in natural language processing over other deep learning architectures. This trend has also permeated the field of time series analysis, especially for long-horizon forecasting, showcasing promising results both in performance and running time. In this paper, we introduce Local Attention Mechanism (LAM), an efficient attention mechanism tailored for time series analysis. This mechanism exploits the continuity properties of time series to reduce the number of attention scores computed. We present an algorithm for implementing LAM in tensor algebra that runs in time and memory O(nlogn), significantly improving upon the O(n^2) time and memory complexity of traditional attention mechanisms. We also note the lack of proper datasets to evaluate long-horizon forecast models. Thus, we propose a novel set of datasets to improve the evaluation of models addressing long-horizon forecasting challenges. Our experimental analysis demonstrates that the vanilla transformer architecture magnified with LAM surpasses state-of-the-art models, including the vanilla attention mechanism. These results confirm the effectiveness of our approach and highlight a range of future challenges in long-sequence time series forecasting.
SHIELD: A regularization technique for eXplainable Artificial Intelligence
Apr 03, 2024



As Artificial Intelligence systems become integral across domains, the demand for explainability grows. While the effort by the scientific community is focused on obtaining a better explanation for the model, it is important not to ignore the potential of this explanation process to improve training as well. While existing efforts primarily focus on generating and evaluating explanations for black-box models, there remains a critical gap in directly enhancing models through these evaluations. This paper introduces SHIELD (Selective Hidden Input Evaluation for Learning Dynamics), a regularization technique for explainable artificial intelligence designed to improve model quality by concealing portions of input data and assessing the resulting discrepancy in predictions. In contrast to conventional approaches, SHIELD regularization seamlessly integrates into the objective function, enhancing model explainability while also improving performance. Experimental validation on benchmark datasets underscores SHIELD's effectiveness in improving Artificial Intelligence model explainability and overall performance. This establishes SHIELD regularization as a promising pathway for developing transparent and reliable Artificial Intelligence regularization techniques.
A Survey on Semi-Supervised Semantic Segmentation
Feb 20, 2023Semantic segmentation is one of the most challenging tasks in computer vision. However, in many applications, a frequent obstacle is the lack of labeled images, due to the high cost of pixel-level labeling. In this scenario, it makes sense to approach the problem from a semi-supervised point of view, where both labeled and unlabeled images are exploited. In recent years this line of research has gained much interest and many approaches have been published in this direction. Therefore, the main objective of this study is to provide an overview of the current state of the art in semi-supervised semantic segmentation, offering an updated taxonomy of all existing methods to date. This is complemented by an experimentation with a variety of models representing all the categories of the taxonomy on the most widely used becnhmark datasets in the literature, and a final discussion on the results obtained, the challenges and the most promising lines of future research.
TSFEDL: A Python Library for Time Series Spatio-Temporal Feature Extraction and Prediction using Deep Learning
Jun 08, 2022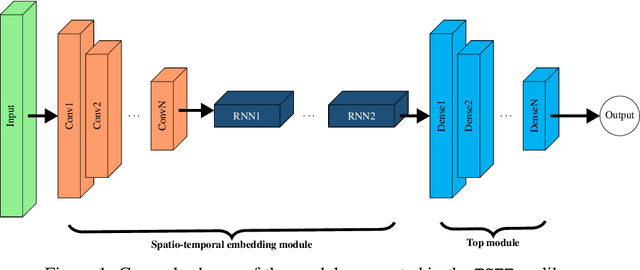
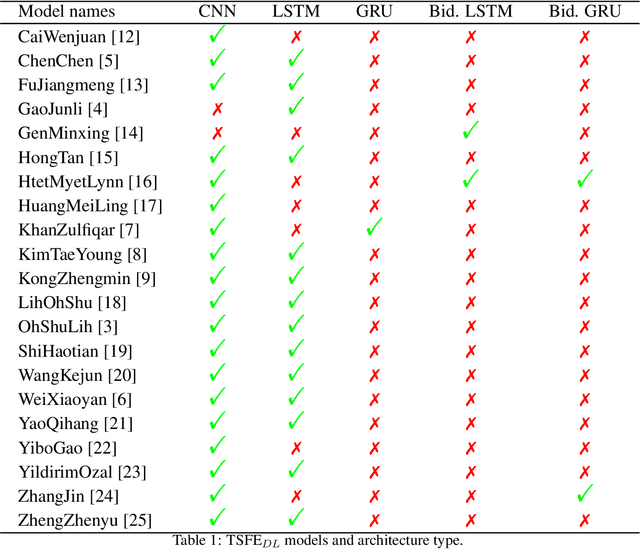
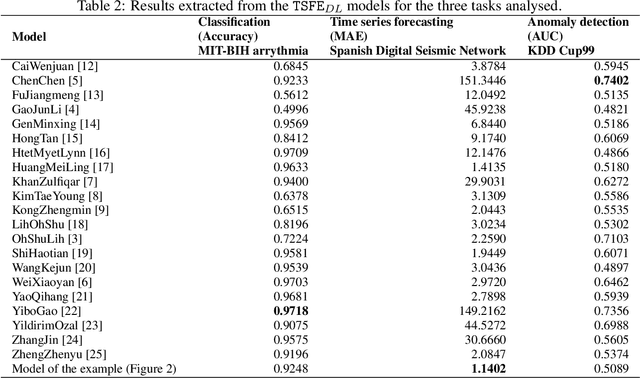
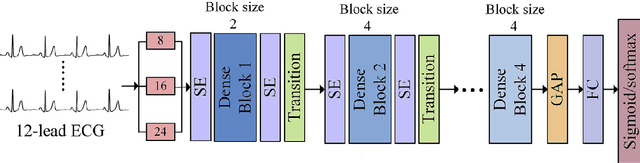
The combination of convolutional and recurrent neural networks is a promising framework that allows the extraction of high-quality spatio-temporal features together with its temporal dependencies, which is key for time series prediction problems such as forecasting, classification or anomaly detection, amongst others. In this paper, the TSFEDL library is introduced. It compiles 20 state-of-the-art methods for both time series feature extraction and prediction, employing convolutional and recurrent deep neural networks for its use in several data mining tasks. The library is built upon a set of Tensorflow+Keras and PyTorch modules under the AGPLv3 license. The performance validation of the architectures included in this proposal confirms the usefulness of this Python package.
A robust approach for deep neural networks in presence of label noise: relabelling and filtering instances during training
Sep 08, 2021



Deep learning has outperformed other machine learning algorithms in a variety of tasks, and as a result, it has become more and more popular and used. However, as other machine learning algorithms, deep learning, and convolutional neural networks (CNNs) in particular, perform worse when the data sets present label noise. Therefore, it is important to develop algorithms that help the training of deep networks and their generalization to noise-free test sets. In this paper, we propose a robust training strategy against label noise, called RAFNI, that can be used with any CNN. This algorithm filters and relabels instances of the training set based on the predictions and their probabilities made by the backbone neural network during the training process. That way, this algorithm improves the generalization ability of the CNN on its own. RAFNI consists of three mechanisms: two mechanisms that filter instances and one mechanism that relabels instances. In addition, it does not suppose that the noise rate is known nor does it need to be estimated. We evaluated our algorithm using different data sets of several sizes and characteristics. We also compared it with state-of-the-art models using the CIFAR10 and CIFAR100 benchmarks under different types and rates of label noise and found that RAFNI achieves better results in most cases.
Anomaly Detection in Predictive Maintenance: A New Evaluation Framework for Temporal Unsupervised Anomaly Detection Algorithms
May 26, 2021



The research in anomaly detection lacks a unified definition of what represents an anomalous instance. Discrepancies in the nature itself of an anomaly lead to multiple paradigms of algorithms design and experimentation. Predictive maintenance is a special case, where the anomaly represents a failure that must be prevented. Related time-series research as outlier and novelty detection or time-series classification does not apply to the concept of an anomaly in this field, because they are not single points which have not been seen previously and may not be precisely annotated. Moreover, due to the lack of annotated anomalous data, many benchmarks are adapted from supervised scenarios. To address these issues, we generalise the concept of positive and negative instances to intervals to be able to evaluate unsupervised anomaly detection algorithms. We also preserve the imbalance scheme for evaluation through the proposal of the Preceding Window ROC, a generalisation for the calculation of ROC curves for time-series scenarios. We also adapt the mechanism from a established time-series anomaly detection benchmark to the proposed generalisations to reward early detection. Therefore, the proposal represents a flexible evaluation framework for the different scenarios. To show the usefulness of this definition, we include a case study of Big Data algorithms with a real-world time-series problem provided by the company ArcelorMittal, and compare the proposal with an evaluation method.
Label Noise Filtering Techniques to Improve Monotonic Classification
Oct 21, 2018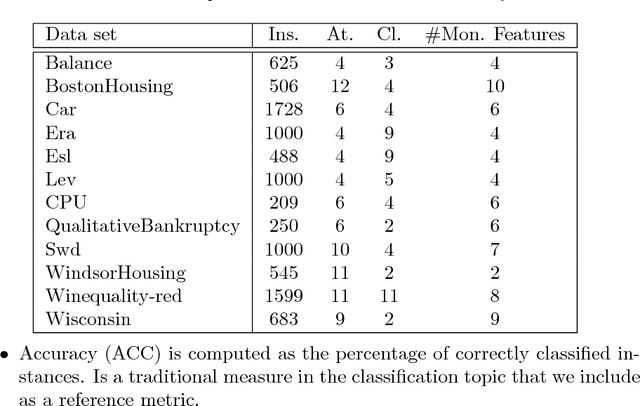
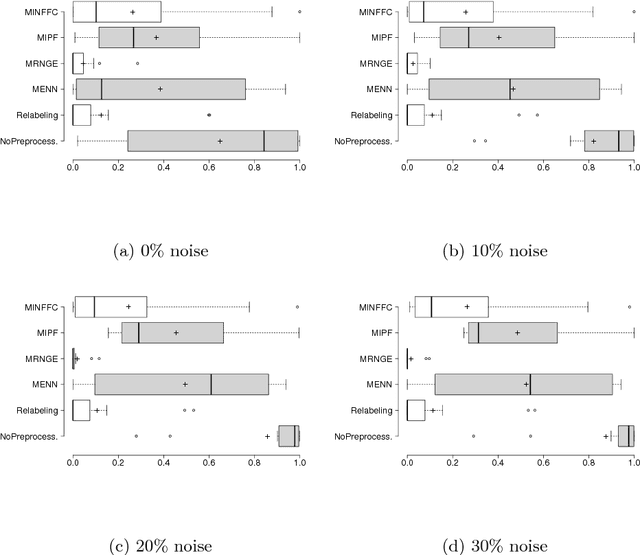
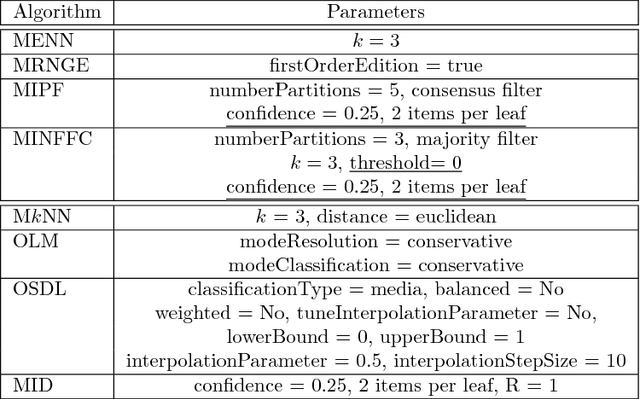
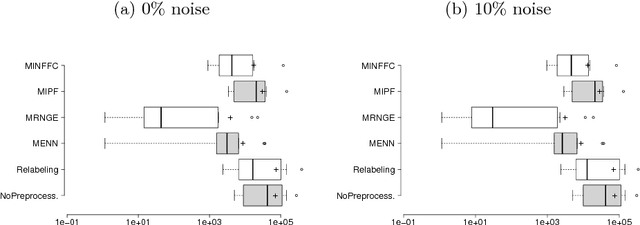
The monotonic ordinal classification has increased the interest of researchers and practitioners within machine learning community in the last years. In real applications, the problems with monotonicity constraints are very frequent. To construct predictive monotone models from those problems, many classifiers require as input a data set satisfying the monotonicity relationships among all samples. Changing the class labels of the data set (relabelling) is useful for this. Relabelling is assumed to be an important building block for the construction of monotone classifiers and it is proved that it can improve the predictive performance. In this paper, we will address the construction of monotone datasets considering as noise the cases that do not meet the monotonicity restrictions. For the first time in the specialized literature, we propose the use of noise filtering algorithms in a preprocessing stage with a double goal: to increase both the monotonicity index of the models and the accuracy of the predictions for different monotonic classifiers. The experiments are performed over 12 datasets coming from classification and regression problems and show that our scheme improves the prediction capabilities of the monotonic classifiers instead of being applied to original and relabeled datasets. In addition, we have included the analysis of noise filtering process in the particular case of wine quality classification to understand its effect in the predictive models generated.
Towards Highly Accurate Coral Texture Images Classification Using Deep Convolutional Neural Networks and Data Augmentation
Mar 27, 2018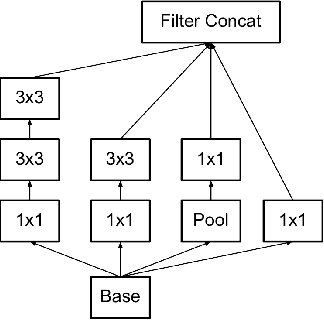
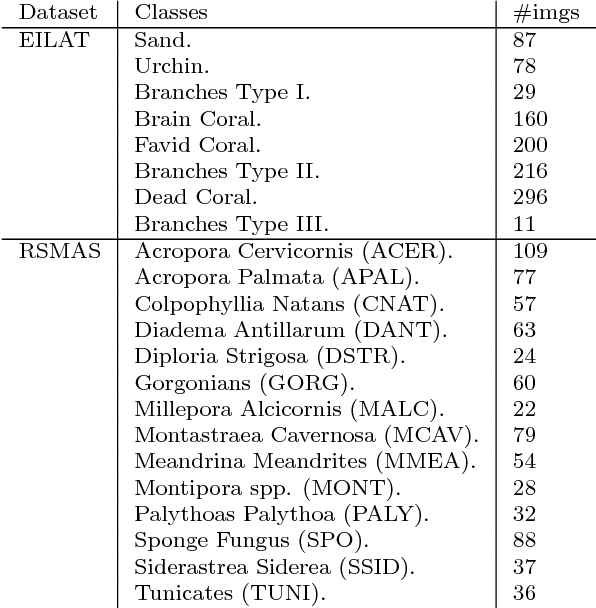
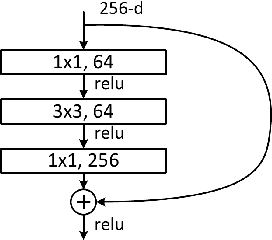

The recognition of coral species based on underwater texture images pose a significant difficulty for machine learning algorithms, due to the three following challenges embedded in the nature of this data: 1) datasets do not include information about the global structure of the coral; 2) several species of coral have very similar characteristics; and 3) defining the spatial borders between classes is difficult as many corals tend to appear together in groups. For this reason, the classification of coral species has always required an aid from a domain expert. The objective of this paper is to develop an accurate classification model for coral texture images. Current datasets contain a large number of imbalanced classes, while the images are subject to inter-class variation. We have analyzed 1) several Convolutional Neural Network (CNN) architectures, 2) data augmentation techniques and 3) transfer learning. We have achieved the state-of-the art accuracies using different variations of ResNet on the two current coral texture datasets, EILAT and RSMAS.
Enabling Smart Data: Noise filtering in Big Data classification
Jul 28, 2017
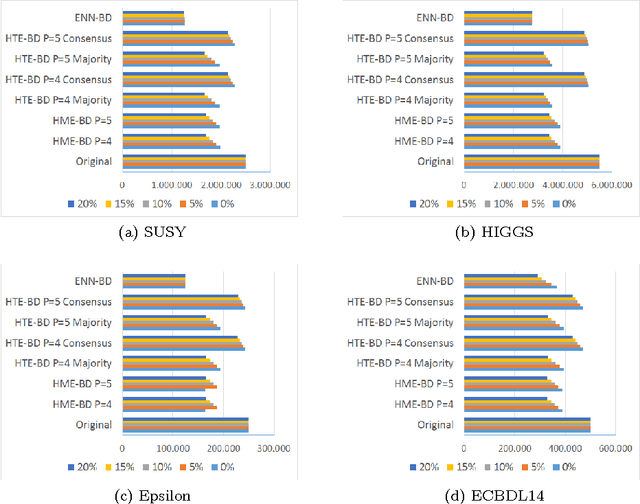
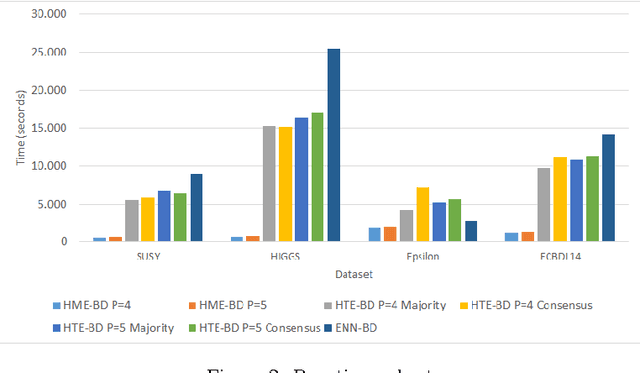

In any knowledge discovery process the value of extracted knowledge is directly related to the quality of the data used. Big Data problems, generated by massive growth in the scale of data observed in recent years, also follow the same dictate. A common problem affecting data quality is the presence of noise, particularly in classification problems, where label noise refers to the incorrect labeling of training instances, and is known to be a very disruptive feature of data. However, in this Big Data era, the massive growth in the scale of the data poses a challenge to traditional proposals created to tackle noise, as they have difficulties coping with such a large amount of data. New algorithms need to be proposed to treat the noise in Big Data problems, providing high quality and clean data, also known as Smart Data. In this paper, two Big Data preprocessing approaches to remove noisy examples are proposed: an homogeneous ensemble and an heterogeneous ensemble filter, with special emphasis in their scalability and performance traits. The obtained results show that these proposals enable the practitioner to efficiently obtain a Smart Dataset from any Big Data classification problem.