 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding up the annotation process in semantic segmentation industrial applications
Jun 18, 2026Current machine learning models commonly require large and well-annotated datasets. However, the annotation process often becomes a bottleneck, with increased complexity leading to higher chances of human errors. Within this context, our goal in this paper is to leverage unsupervised algorithms to improve data annotation efficiency for complex semantic segmentation problems in industrial materials science. Previous research has quantified labeling time and others explored unsupervised methods. However, to the best of our knowledge, this is the first study to quantify how much unsupervised algorithms accelerate the labeling process. We aim to validate the extent to which this laborious process can be accelerated, focusing on semantic segmentation tasks that involve annotating each pixel of high-resolution images, such as the microstructure characterization challenge in materials science. Specifically, we demonstrate that by using unsupervised computer vision algorithms, the time required for the labeling process can be reduced from 170 hours to 37 hours, achieving an approximate reduction of 78\%. The dataset we work with includes large images of dimensions 1280x959 and 960x703, which further increases the complexity of the annotation task. Despite these challenges, we create and share the largest public steel microstructure segmentation dataset to date, available under MIT License with permanent DOI, contributing a fully annotated, high-resolution dataset to the field. Additionally, this is the first work to compare the labeling time from scratch (a common approach in previous studies) to the labeling time when using these unsupervised algorithms as a pre-annotation step. Furthermore, we provide a Deep Learning model trained on this dataset, validated by field experts, and deployed in an industrial setting, serving as an initial benchmark for this public dataset.
A practical artificial intelligence framework for legal age estimation using clavicle computed tomography scans
Mar 18, 2026Legal age estimation plays a critical role in forensic and medico-legal contexts, where decisions must be supported by accurate, robust, and reproducible methods with explicit uncertainty quantification. While prior artificial intelligence (AI)-based approaches have primarily focused on hand radiographs or dental imaging, clavicle computed tomography (CT) scans remain underexplored despite their documented effectiveness for legal age estimation. In this work, we present an interpretable, multi-stage pipeline for legal age estimation from clavicle CT scans. The proposed framework combines (i) a feature-based connected-component method for automatic clavicle detection that requires minimal manual annotation, (ii) an Integrated Gradients-guided slice selection strategy used to construct the input data for a multi-slice convolutional neural network that estimates legal age, and (iii) conformal prediction intervals to support uncertainty-aware decisions in accordance with established international protocols. The pipeline is evaluated on 1,158 full-body post-mortem CT scans from a public forensic dataset (the New Mexico Decedent Image Database). The final model achieves state-of-the-art performance with a mean absolute error (MAE) of 1.55 $\pm$ 0.16 years on a held-out test set, outperforming both human experts (MAE of approximately 1.90 years) and previous methods (MAEs above 1.75 years in our same dataset). Furthermore, conformal prediction enables configurable coverage levels aligned with forensic requirements. Attribution maps indicate that the model focuses on anatomically relevant regions of the medial clavicular epiphysis. The proposed method, which is currently being added as part of the Skeleton-ID software (https://skeleton-id.com/skeleton-id/), is intended as a decision-support component within multi-factorial forensic workflows.
Don't Forget your Inverse DDIM for Image Editing
May 14, 2025



The field of text-to-image generation has undergone significant advancements with the introduction of diffusion models. Nevertheless, the challenge of editing real images persists, as most methods are either computationally intensive or produce poor reconstructions. This paper introduces SAGE (Self-Attention Guidance for image Editing) - a novel technique leveraging pre-trained diffusion models for image editing. SAGE builds upon the DDIM algorithm and incorporates a novel guidance mechanism utilizing the self-attention layers of the diffusion U-Net. This mechanism computes a reconstruction objective based on attention maps generated during the inverse DDIM process, enabling efficient reconstruction of unedited regions without the need to precisely reconstruct the entire input image. Thus, SAGE directly addresses the key challenges in image editing. The superiority of SAGE over other methods is demonstrated through quantitative and qualitative evaluations and confirmed by a statistically validated comprehensive user study, in which all 47 surveyed users preferred SAGE over competing methods. Additionally, SAGE ranks as the top-performing method in seven out of 10 quantitative analyses and secures second and third places in the remaining three.
A Roadmap to Guide the Integration of LLMs in Hierarchical Planning
Jan 14, 2025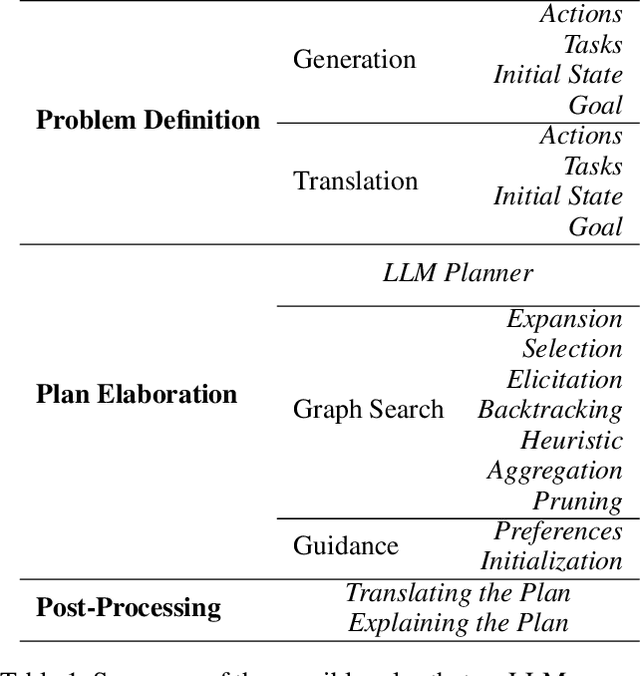
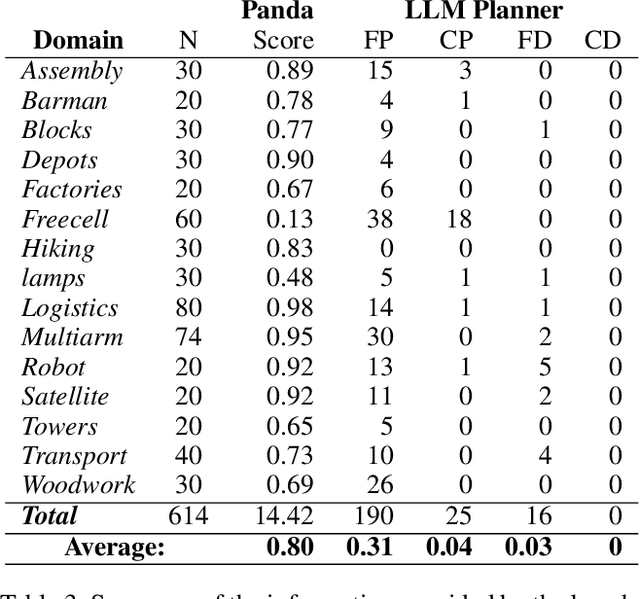
Recent advances in Large Language Models (LLMs) are fostering their integration into several reasoning-related fields, including Automated Planning (AP). However, their integration into Hierarchical Planning (HP), a subfield of AP that leverages hierarchical knowledge to enhance planning performance, remains largely unexplored. In this preliminary work, we propose a roadmap to address this gap and harness the potential of LLMs for HP. To this end, we present a taxonomy of integration methods, exploring how LLMs can be utilized within the HP life cycle. Additionally, we provide a benchmark with a standardized dataset for evaluating the performance of future LLM-based HP approaches, and present initial results for a state-of-the-art HP planner and LLM planner. As expected, the latter exhibits limited performance (3\% correct plans, and none with a correct hierarchical decomposition) but serves as a valuable baseline for future approaches.
Towards a Unified Framework for Sequential Decision Making
Oct 03, 2023In recent years, the integration of Automated Planning (AP) and Reinforcement Learning (RL) has seen a surge of interest. To perform this integration, a general framework for Sequential Decision Making (SDM) would prove immensely useful, as it would help us understand how AP and RL fit together. In this preliminary work, we attempt to provide such a framework, suitable for any method ranging from Classical Planning to Deep RL, by drawing on concepts from Probability Theory and Bayesian inference. We formulate an SDM task as a set of training and test Markov Decision Processes (MDPs), to account for generalization. We provide a general algorithm for SDM which we hypothesize every SDM method is based on. According to it, every SDM algorithm can be seen as a procedure that iteratively improves its solution estimate by leveraging the task knowledge available. Finally, we derive a set of formulas and algorithms for calculating interesting properties of SDM tasks and methods, which make possible their empirical evaluation and comparison.
A Review of Symbolic, Subsymbolic and Hybrid Methods for Sequential Decision Making
Apr 20, 2023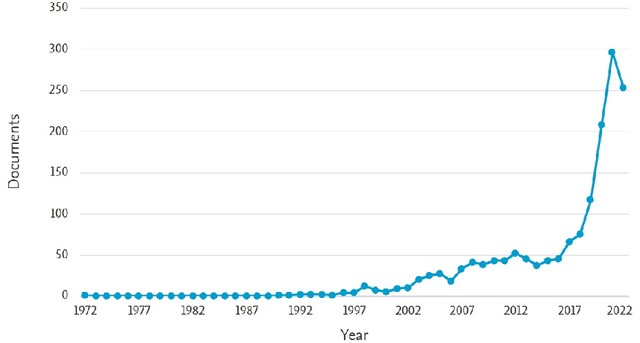
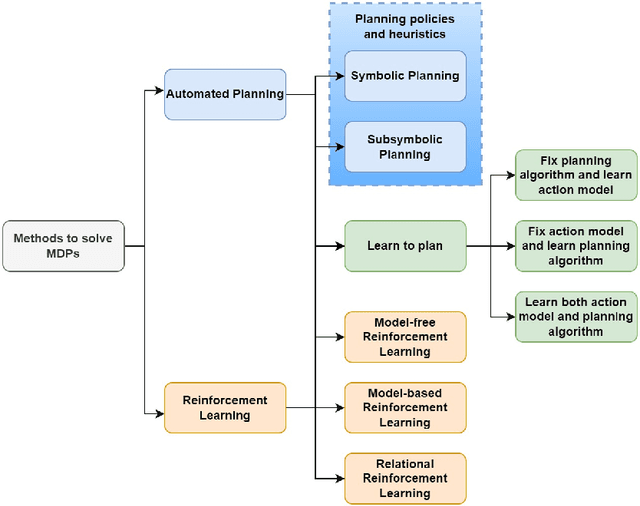
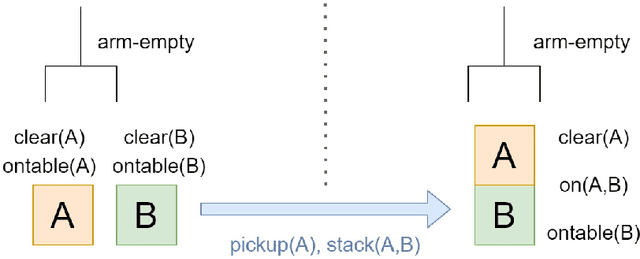
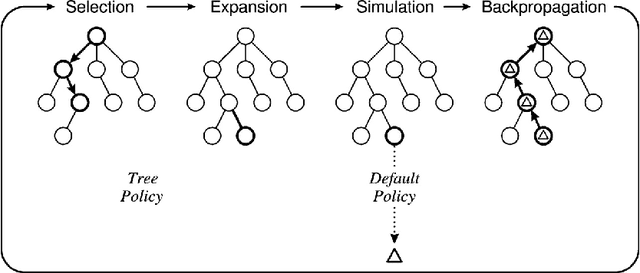
The field of Sequential Decision Making (SDM) provides tools for solving Sequential Decision Processes (SDPs), where an agent must make a series of decisions in order to complete a task or achieve a goal. Historically, two competing SDM paradigms have view for supremacy. Automated Planning (AP) proposes to solve SDPs by performing a reasoning process over a model of the world, often represented symbolically. Conversely, Reinforcement Learning (RL) proposes to learn the solution of the SDP from data, without a world model, and represent the learned knowledge subsymbolically. In the spirit of reconciliation, we provide a review of symbolic, subsymbolic and hybrid methods for SDM. We cover both methods for solving SDPs (e.g., AP, RL and techniques that learn to plan) and for learning aspects of their structure (e.g., world models, state invariants and landmarks). To the best of our knowledge, no other review in the field provides the same scope. As an additional contribution, we discuss what properties an ideal method for SDM should exhibit and argue that neurosymbolic AI is the current approach which most closely resembles this ideal method. Finally, we outline several proposals to advance the field of SDM via the integration of symbolic and subsymbolic AI.
A Survey on Semi-Supervised Semantic Segmentation
Feb 20, 2023



Semantic segmentation is one of the most challenging tasks in computer vision. However, in many applications, a frequent obstacle is the lack of labeled images, due to the high cost of pixel-level labeling. In this scenario, it makes sense to approach the problem from a semi-supervised point of view, where both labeled and unlabeled images are exploited. In recent years this line of research has gained much interest and many approaches have been published in this direction. Therefore, the main objective of this study is to provide an overview of the current state of the art in semi-supervised semantic segmentation, offering an updated taxonomy of all existing methods to date. This is complemented by an experimentation with a variety of models representing all the categories of the taxonomy on the most widely used becnhmark datasets in the literature, and a final discussion on the results obtained, the challenges and the most promising lines of future research.
NeSIG: A Neuro-Symbolic Method for Learning to Generate Planning Problems
Jan 24, 2023


In the field of Automated Planning there is often the need for a set of planning problems from a particular domain, e.g., to be used as training data for Machine Learning or as benchmarks in planning competitions. In most cases, these problems are created either by hand or by a domain-specific generator, putting a burden on the human designers. In this paper we propose NeSIG, to the best of our knowledge the first domain-independent method for automatically generating planning problems that are valid, diverse and difficult to solve. We formulate problem generation as a Markov Decision Process and train two generative policies with Deep Reinforcement Learning to generate problems with the desired properties. We conduct experiments on several classical domains, comparing our method with handcrafted domain-specific generators that generate valid and diverse problems but do not optimize difficulty. The results show NeSIG is able to automatically generate valid problems of greater difficulty than the competitor approaches, while maintaining good diversity.
A Survey on Evolutionary Computation for Computer Vision and Image Analysis: Past, Present, and Future Trends
Sep 14, 2022
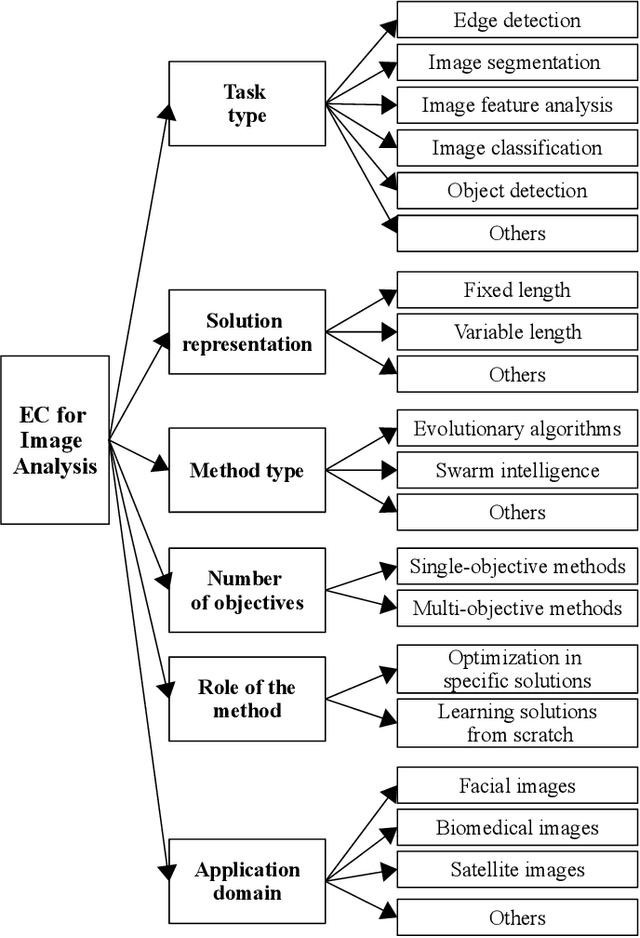
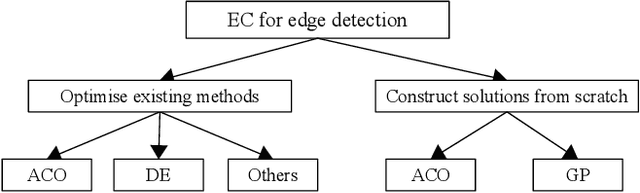

Computer vision (CV) is a big and important field in artificial intelligence covering a wide range of applications. Image analysis is a major task in CV aiming to extract, analyse and understand the visual content of images. However, image-related tasks are very challenging due to many factors, e.g., high variations across images, high dimensionality, domain expertise requirement, and image distortions. Evolutionary computation (EC) approaches have been widely used for image analysis with significant achievement. However, there is no comprehensive survey of existing EC approaches to image analysis. To fill this gap, this paper provides a comprehensive survey covering all essential EC approaches to important image analysis tasks including edge detection, image segmentation, image feature analysis, image classification, object detection, and others. This survey aims to provide a better understanding of evolutionary computer vision (ECV) by discussing the contributions of different approaches and exploring how and why EC is used for CV and image analysis. The applications, challenges, issues, and trends associated to this research field are also discussed and summarised to provide further guidelines and opportunities for future research.
* Conditionally accepted by IEEE Transactions on Evolutionary Computation
Custom Structure Preservation in Face Aging
Jul 22, 2022
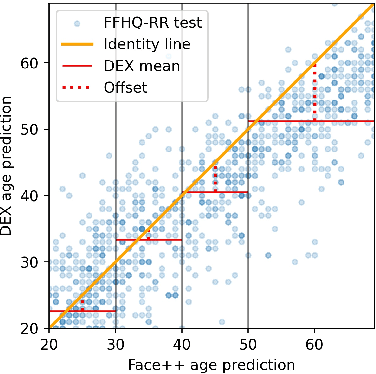
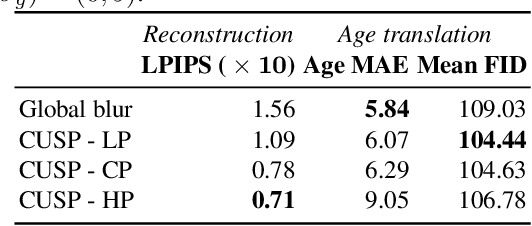
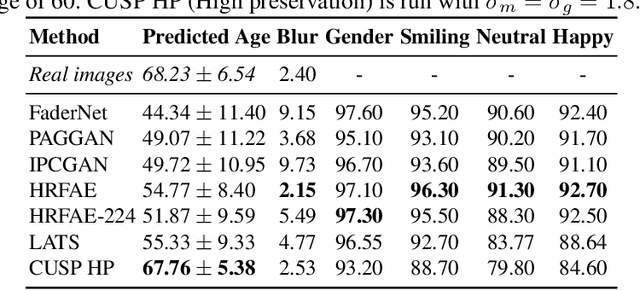
In this work, we propose a novel architecture for face age editing that can produce structural modifications while maintaining relevant details present in the original image. We disentangle the style and content of the input image and propose a new decoder network that adopts a style-based strategy to combine the style and content representations of the input image while conditioning the output on the target age. We go beyond existing aging methods allowing users to adjust the degree of structure preservation in the input image during inference. To this purpose, we introduce a masking mechanism, the CUstom Structure Preservation module, that distinguishes relevant regions in the input image from those that should be discarded. CUSP requires no additional supervision. Finally, our quantitative and qualitative analysis which include a user study, show that our method outperforms prior art and demonstrates the effectiveness of our strategy regarding image editing and adjustable structure preservation. Code and pretrained models are available at https://github.com/guillermogotre/CUSP.