 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Gaze Following: Detecting Objects in Videos Beyond the Camera Field of View
Paper and Code
Feb 28, 2019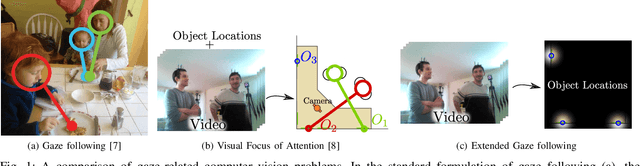
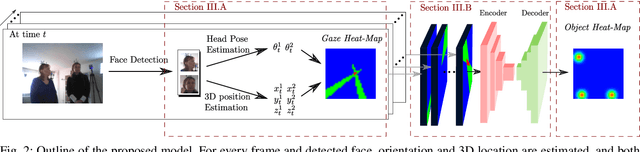
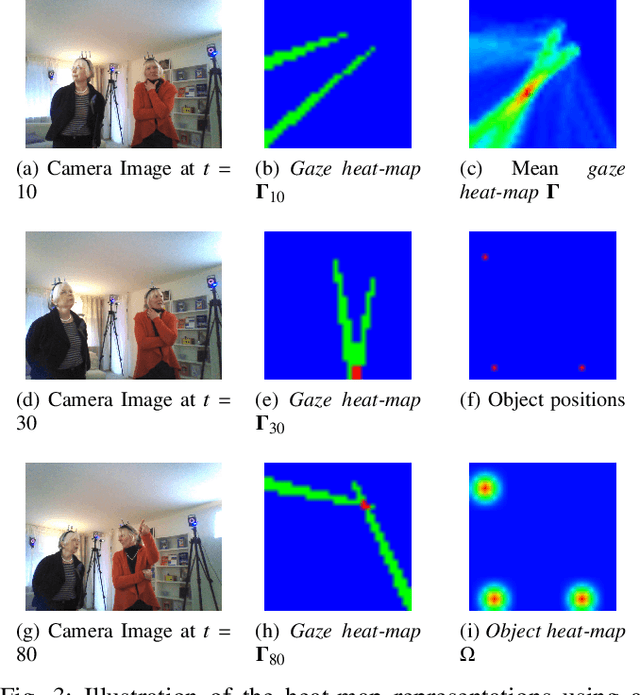
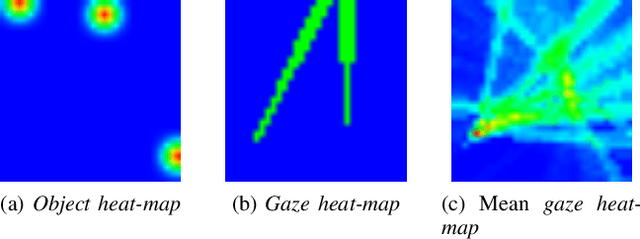
In this paper we address the problems of detecting objects of interest in a video and of estimating their locations, solely from the gaze directions of people present in the video. Objects can be indistinctly located inside or outside the camera field of view. We refer to this problem as extended gaze following. The contributions of the paper are the followings. First, we propose a novel spatial representation of the gaze directions adopting a top-view perspective. Second, we develop several convolutional encoder/decoder networks to predict object locations and compare them with heuristics and with classical learning-based approaches. Third, in order to train the proposed models, we generate a very large number of synthetic scenarios employing a probabilistic formulation. Finally, our methodology is empirically validated using a publicly available dataset.